�ֻ���֤��ƽ̨����д��֤�룬��ʵ���ڰ�Google��ѵ��AI
2018-12-20 18:12
����ʵ����������֤�룬���������ڰ���˱�ע���ϣ�ѵ�� AI ��?��֪����
������ΪͼƬ���ࣺ

�о������ڽ����˼�ʻ�� AI ��·��……
��ʵ��������֤�������Ϊ AI �������������̫�ࡣ��ʵ�ϣ�����������֤��ʱ���˴���ʷ���ӹ����������֤��ʱ�ھͿ�ʼ�ˡ�
ÿ��������֤�룬�㶼�ڰ��˴�
����Ӧ��������֤��ϵͳ���� reCAPTCHA ��Completely Automated Public Turing Test To Tell Computers and Humans Apart�������˻���ȫ�Զ�ͼ�����ϵͳ���ˡ�
�������ѱ� Google �չ��Ĺ�˾���е��������ϴ���·���˻���֤���������ĵ��������Ӿ����� reCAPTCHA����
2007 �꣬reCAPTCHA �Ĵ�ʼ��֮һ�����ڻ���¡��ѧ����·��˹‧��‧����Luis von Ahn���뵽���������������������ó����ܲ���������֤��ϵͳ��������ͻ�����ͬ��������أ���

��ʱ��һ��ؽ�������������ǣ���ΰѺ����̺�������ֽ�ʵ伮��λ����
��Ҫ��λ�����ݣ������ַ���:
��һ�ַ������ֹ�¼�롣���ַ�����ʱ�����������׳���¼�����
��һ�ַ�������ɨ���ļ����ٽ�Ϲ�ѧ���ֱ�ʶ����¼�����֡�����������������Щ�����Զ����Ʒ�ʾͲ���ļ�ɨ�������ʵ����̫����……
����Ϊ�Լ�������֤�룬���������ʵ�ڰ�Google��ѵ��AI��
�����ڵ��Ա�ʶ����������©���ٳ�������û������
����Ϊ�Լ�������֤�룬���������ʵ�ڰ�Google��ѵ��AI��
Ϊ�˽���ļ���λ�������⣬2007 �꣬·��˹�Ƴ����µ���֤��ϵͳ reCAPTCHA��
�� reCAPTCHA ��֤��ϵͳ�һ����֤����������ֹ��ɡ�
��һ���ֺʹ�ͳ��֤��һ�������Զ��������Ҿ������δ��������֣������������Dz������ˡ����ڶ����֣����Ǵ�����ʶ���ļ��н�ȡ�����Ĵʡ�

���ʹ������ȷ����ǰ�벿�֣���ô reCAPTCHA �ͻ����ʹ��������ĺ�벿��Ҳ����ȷ�ģ�Ȼ���¼�������ظ� reCAPTCHA ��������
�������������������������������ɷ������ʹ���߽��н�����֤����ȷ��û�в�С�Ļ����������ʵ������
Ҳ����˵��������Ч���˻���������֤���ǰ����Ѿ���ɣ������Σ���������Ϊ���������������ˡ�
��ô��reCAPTCHA �������˶�����أ�
2007 ���Ƴ�֮����reCAPTCHA ÿ�춼�ܰ���¼�� 3000 ����ַ��� 2008�꣬�������������� 6000 ���������ͳ�ƣ��ڽ��죬ȫ����ÿ�춼�� 2 �ڸ��ַ��� reCAPTCHA ¼�룬�൱������ 15 ��Сʱ�Ĺ�������
Ҳ����˵��һ����Ҫ���Բ��Ȳ�˯����룬������� reCAPTCHA һ��Ĺ�������
������Ϊֹ�� reCAPTCHA �Ѿ�¼���˴� 1851 ����������С�ŦԼʱ���������� 1300 ��ƪ���¡�����ŦԼʱ�����⣬reCAPTCHA ����λ���˳��� 2500 ���飬��ȫ���ͼ������ԼΪ 1.3 �ڱ���
����Ϊ�Լ�������֤�룬���������ʵ�ڰ�Google��ѵ��AI��
·��˹�ڽ���ý�� The Hustle �ɷ�ʱ�������� reCAPTCHA �����Ҵ�����һ��ϵͳ����ʮ��Ϊ��λ��������СʱΪ������������������������Դ���˵Ĵ��ԡ���
��֤�����ڰ���������
��� reCAPTCHA �Ĺ��µ�����ͽ����ˣ�ÿ���˶���ܿ��ġ�������û��ô��
2009 �꣬Google �Դ�Լ 2780 ����Ԫ�ļ۸��չ��� reCAPTCHA������ʼ���� reCAPTCHA ������ע���ϡ�
����ǰ����˵��reCAPTCHA ��ǰ���������֤���Dz������ˣ����ξ�������Ϊ��֤����ˡ�
2012 �꣬Google ��ʼ�� Google �־������Ա�ʶ�����ƺ�·�Ƽ�����֤�룬��ʹ���߰�æ��ע��
����Ϊ�Լ�������֤�룬���������ʵ�ڰ�Google��ѵ��AI��
���˱�ע����·�ƣ���ʹ���߰�æΪ���Ͽ����Ҳ�dz�������ʽ֮һ��������ͼ������ʹ���ߡ���������·�Ƶ�ͼƬ������֤�롣
����Ϊ�Լ�������֤�룬���������ʵ�ڰ�Google��ѵ��AI��
���Google AI �Ѿ��ܾ�ȷ����·���ϵ����ֺ����֣�ȷ�Ⱥ����۲������¡�
����һ����������ʹ���� Google ���Զ���ʻ���������� AI ����ʶ·�ƺ�·��ʱ���ⱳ���ܲ�˵û����ǧ��ʹ��������ע�Ŀ��ͣ����е�ȻҲ������Ĺ��ס�
����Ϊ�Լ�������֤�룬���������ʵ�ڰ�Google��ѵ��AI��
������һĿ�ģ�Google Ҳ�����ܻ䡣�� reCAPTCHA �����ϣ�Google ����˵���� reCAPTCHA ������֮����ע���ϡ�ѵ�� AI �ġ�Ⱥ��ͳ����ģʽ��
����Ϊ�Լ�������֤�룬���������ʵ�ڰ�Google��ѵ��AI��
��������ʹ���߶���һ��е�������
һλ������֤�벻���µ� Reddit ʹ����д��������ͺ����ü��������ÿ��Ϊ���� 5 ���ӵĹ�����Ȼ��һ��Ǯ������һ����������𣿡�
����Ϊ�Լ�������֤�룬���������ʵ�ڰ�Google��ѵ��AI��
��֤���ǰ������
��֤�뵮��֮������Ϊ�˽��һ���ر�ʵ�ڵ����⡣
��·������ô������ô֪����һ���Dz���һ�������������ˣ���
�ڲ�������Ϸ�������ϣ������˿����ô����������ۺ����û����ʹ�������µ��м�ֵ��ѶϢ���ڽ��ڽ���ƽ̨���ű���ʽ���Կ���ͣ�����������ƽ����룻��Ʊ����վ���Ҹ�˵�������ʮֻ��Ҳ�����������˻�ţ……
���ȷ����·���������˷��͵ģ�����ά����·�����ͱ���ʹ���߰�ȫ�Ĵ����⡣
2002 �꣬����·��˹‧��‧�������һ����ʵ���еĽ���������ܷ��塸�����ǹ�����
��Ȼ���Ե������ͷ�������������ǿ�ö࣬���ǵ�ʱ�ĵ�������һֻСè�ڱ��ܡ������Ѳ�������С������ͼ���ϲ���������������ԭ��·��˹������ͬ�º��������� reCAPTCHA ������ CAPTCHA��Ҳ���������׳Ƶ���֤�롣
������֤��һ����һЩ����Ť�����ε����ֻ����֡�������Ա�ʶ��Щ���֣�����ż��Ҳ�����������Ҳ�ϲ���������������������������ַ��ĺ��塣
����Ϊ�Լ�������֤�룬���������ʵ�ڰ�Google��ѵ��AI��
֮����֤��Ҳ�����������⡢ѡ���⣬����ֲ��������͵ĵ����������ڸDz�סһ�������������⣺��Ȼ CAPTCHA �Ѿ�����ԱȽϺõĽ����������Ҳ��������һ�顣
���²⡢�˹��ǻ۱�ʶͼ�������ǰ���֤��ͼƬ���ظ��˹�����������ȷ����������������ҵ��ɳ�֮����
��������Щ��֤�룬�����˶��㲻����
����Ϊ��֤���˷�ʱ�䣬��ʶ�Ѷȴ��Ҷ���ִ��ijЩ�ض���Ϊ�����������ϻ���ѧ���о���������ʹ���߶��Լ����Ѻã���֤�볤���ڡ���·ʱ����˷�������������ǰé��
���ǣ� reCAPTCHA �Ƴ��˸���ѧ����֤ϵͳ��������֤ϵͳ����ʹ���ߵĿͻ��˻�������ʹ���ߵĻ���ͼ��̲����켣������˻����˵�ģ��ɱ���ʹ������Ҳ����Ҫ������ر�ʶ����ŤŤ�����֣�ֻ��Ҫ�ڶԻ����������Ҳ��ǻ����ˡ�������ͨ����֤��
����Ϊ�Լ�������֤�룬���������ʵ�ڰ�Google��ѵ��AI��
��Ȼ�Ѿ����˸�������ȫ�������ʽ����ô�������dzɳ�����֤�룬�Dz���Ҳ�ñ���̭���أ������ܽ��������ġ��ڰ�ģʽ�������Ƿ�����أ�

�������
 王健林许家印游艇曝光 网友:这次真是贫穷限制了我们的想像力
王健林许家印游艇曝光 网友:这次真是贫穷限制了我们的想像力2018-04-16 16:32
 三季度全球可穿戴设备出货量上涨94.6%,苹果稳…
三季度全球可穿戴设备出货量上涨94.6%,苹果稳…2019-12-10 17:52
 Samsung新专利曝光全面屏没有刘海
Samsung新专利曝光全面屏没有刘海2018-05-13 13:33
 全幅高速连拍Canon1DX单机售28800元
全幅高速连拍Canon1DX单机售28800元2018-04-09 17:32
 华为Mate X预计供货20万台左右
华为Mate X预计供货20万台左右2019-06-30 15:50
 轻量级入门机:FujifilmX-M1无反登场
轻量级入门机:FujifilmX-M1无反登场2018-01-03 12:00
 闪光灯竟有这么多花样魅蓝E2评测
闪光灯竟有这么多花样魅蓝E2评测2018-05-29 19:33
 中科循环经济研究院在沧州成立
中科循环经济研究院在沧州成立2020-12-28 16:52
 2018春节第一新机 魅蓝E3背面设计捉眼
2018春节第一新机 魅蓝E3背面设计捉眼2019-02-19 05:37
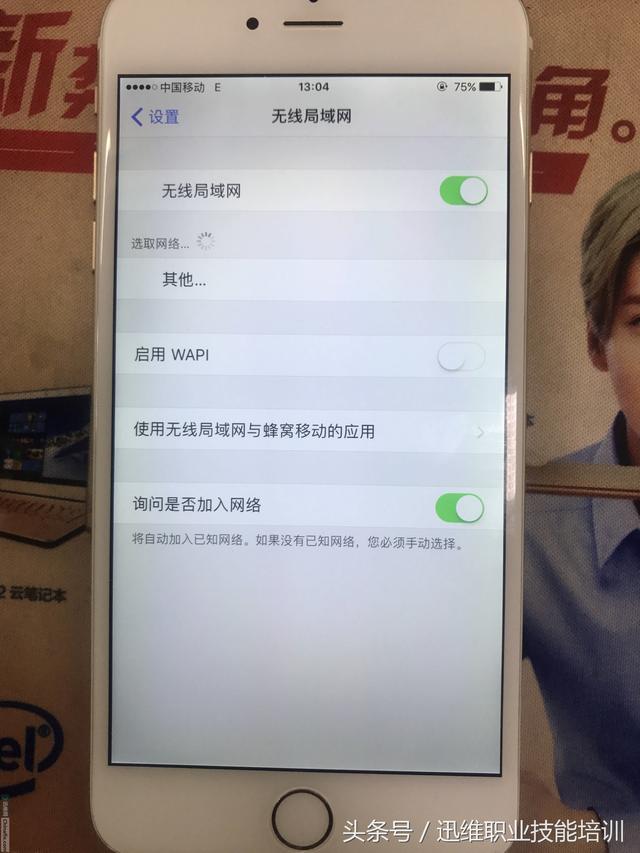 iPhone6Plus搜不到WiFi 手机店没修好 大神思路清晰一招搞定
iPhone6Plus搜不到WiFi 手机店没修好 大神思路清晰一招搞定2018-05-02 14:31
 阿里YunOS即将到来 目前已有国产手机支持 期待吗?
阿里YunOS即将到来 目前已有国产手机支持 期待吗?2018-04-29 20:31
 霸屏了!问卷网八周年感恩回馈活动火热进行中!
霸屏了!问卷网八周年感恩回馈活动火热进行中!2021-07-22 19:46
 360摄像机3C云台电池版开启预售 创新“不插电…
360摄像机3C云台电池版开启预售 创新“不插电…2021-03-20 09:54
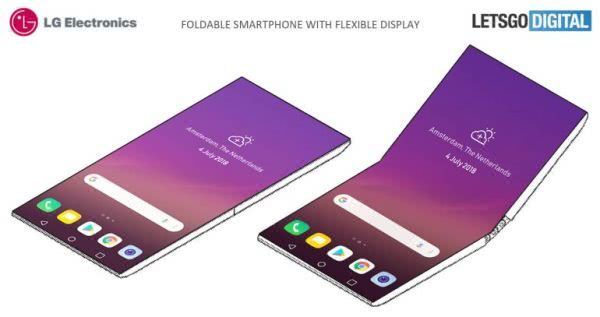 外媒报道:LG正研发新款翻盖式可折叠手机
外媒报道:LG正研发新款翻盖式可折叠手机2018-07-06 05:31
- 扎克伯格夫妇约会给孩子言传身教 扎克伯格家首次曝光
2019-12-05 18:53
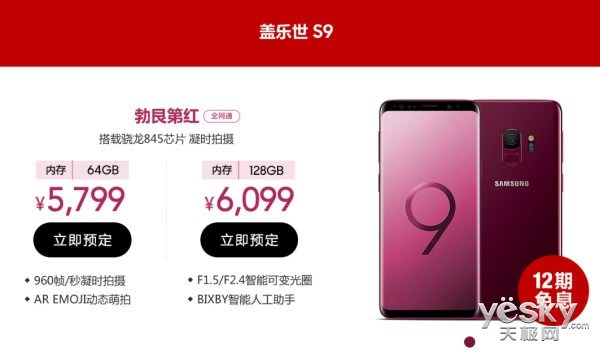 5799元起 三星GalaxyS9/S9+勃艮第红版发布 三大女神代言
5799元起 三星GalaxyS9/S9+勃艮第红版发布 三大女神代言2018-05-08 17:32
 印度造iPhone终于上市 但果粉依旧很失望
印度造iPhone终于上市 但果粉依旧很失望2018-09-22 00:32
 更生行薪酬ETC:智能薪酬市场的领跑者
更生行薪酬ETC:智能薪酬市场的领跑者2019-08-20 11:55
 魔兽争霸:守城关卡的设定十分经典 那么战役中最经典的是哪关?_希尔瓦娜斯
魔兽争霸:守城关卡的设定十分经典 那么战役中最经典的是哪关?_希尔瓦娜斯2019-06-30 14:46
 脑洞飘出天际的科研队伍开发出3D打印水质检测器
脑洞飘出天际的科研队伍开发出3D打印水质检测器2018-08-05 18:31