

在腾讯游戏资料中心担任腾讯游戏数据后台架构开发的腾讯互娱高级工程师许振文近日来台参加Big Data Innovation Summit 2016活动时,也揭露了腾讯打造Spark游戏分析应用,并分享如何利用Spark,来加快游戏行销系统的预测和优化经营。
全中国拥有上亿游戏用户的腾讯游戏,同时经营超过百款以上的大、中型网络和休闲游戏,平均单日最高同时在线游戏人数更超过上千万人,每天新增的游戏资料高达60TB,腾讯游戏如何因应游戏爆量数据增长来加快分析速度,甚至做到游戏资料串流分析,以提高游戏玩家体验和营运效益,背后用的一套关键技术正是火红的大数据串流分析技术Spark。
在中国经营和代理多款超人气网络游戏,如《QQ游戏》、《英雄联盟》、《地下城与勇士》的腾讯游戏,是腾讯集团旗下5大网络业务之一,也是全球第3、中国最大规模的一家网络游戏开发和代理商。目前在腾讯游戏资料中心担任腾讯游戏数据后台架构开发的腾讯互娱高级工程师许振文近日来台参加Big Data Innovation Summit 2016活动时,也揭露了腾讯打造Spark游戏分析应用,并分享他们如何利用Spark来加快游戏行销系统的预测和优化经营。
许振文表示,他们依照游戏玩家的完整生命周期,从开始进入游戏到离开游戏,来打造出以Spark丛集运算引擎为核心的数据游戏服务平台iData,可用来优化游戏资料分析和行销与营运。管理者可用iData快速分析游戏用户资料,找出潜在问题,不只能依据分析结果即时因应调整游戏经营策略,也用于增加游戏用户的黏着度。
以Spark为核心加上HDFS搭建串流大数据分析平台
腾讯游戏资料分析阶段,从早期用多台服务器搭建运算丛集来分析游戏资料,到后来也用过大数据分析工具Hadoop,打造游戏大数据分析引擎。不过许振文说,Hadoop适合处理大量批次资料,但对于即时性资料处理并不在行,为了能够更快速地分析游戏资料,后来腾讯也开始采用了Spark来做为游戏资料串流分析的新工具。
许振文也提到目前腾讯游戏旗下经营的大、中型网络或休闲游戏超过200款,全部游戏数据资料加总将近20PB,资料量非常庞大,同时还以每天新增60TB的游戏资料量不断增长中,目前他们主要是锁定多款较热门或经过挑选的线上游戏的核心数据来加以分析,不过这资料量也超过200TB。
Spark的游戏分析应用上,许振文表示,腾讯目前已将Spark丛集分别运用在离线分析和即时分析处理上。在离线资料分析上,他们至今已使用了3,500台服务器搭建Spark运算丛集,并用Spark来承担ETL(Extract、Transform、 Load)的功能,做为游戏资料分析前的数据清洗、建立数据报表和统计处理工作。这些经过预先处理完毕后的资料,则会再批量写入到开源分散式数据库ElasticsSearch或Tredis中以供后续串流分析使用。许振文表示,Tredis是腾讯游戏研发部门以开源内存式数据库Redis和RocksDB为基础开发的一个套件,数据库读写速度更快。
另外将游戏数据写入数据库时,他们还会利用Spark来控制不同丛集写入速度,避免占满整个带宽而影响了读取效能。
目前9成腾讯游戏资料分析都采用Spark
许振文表示,透过Spark内建的内存内丛集运算技术,可以将搜集到的资料直接就在内存上运算,也使得资料写入速度变得更快,过去仅采用Redis数据库或是搭建小丛集的作法,最多只能达到每秒20万笔的写入速度,改用Spark后写入速度则是倍增,写入速度高达每秒50万笔的资料量。
许振文表示,现在公司内部改采用Spark做为串流大数据分析的比例已超过9成,“这是以前用Hadoop根本做不到,而是得靠Spark才能达成。”他说。
在即时分析游戏资料上,腾讯游戏则搭建了另一个Spark运算丛集,由Spark、HDFS、SparkScheduler,以及Zookeeper架构而成。位于底层的储存层采用分散式档案系统HDFS,用来记录和储存分析结果,包括分析结果数据、账号转换数据、算法模型数据等。中间层则是Spark的核心,负责调度CPU运算资源和任务分配。
许振文说明,目前在Spark丛集运算中他们用最多的Spark套件是SparkSQL、串流分析套件Spark Streaming与分散式机器学习套件MLlib,以提供不同游戏资料的串流分析应用时使用。另外还使用ZooKeeper做为Spark分散式运作的集中式管理工具。他们还自行开发了一个任务调度工具SparkScheduler,可以根据服务业务、用户或任务类型来动态调度。
在游戏资料分析时,系统会先搜集游戏用户的行为数据、属性数据、轮廓数据,这些数据有来自多个不同来源,包括了从分散式讯息提交系统Kafka和腾讯专为自家大数据处理开发的开源分散式资料仓储系统TDW(Tencent Distributed Warehouse)取得的日志和相关数据资料,之后再经过数据清洗、统计、合并后才放进Spark丛集引擎中来分析。
许振文表示,目前腾讯游戏常用于运算模型的即时分析引擎有几种,例如,轮廓分析、交叉分析和ES串流分析等。
许振文也以其中一个用户多维轮廓分析当例子。他表示,多维轮廓是所有游戏即时分析系统中非常重要的一环,能够做到很快速地识别目标用户或是有异常的游戏用户来做后续处理。例如,能从提取已流失的游戏用户的历史资料对他们做分析,以快速了解哪个地区的游戏用户流失最多或受到影响最大的年龄层分布。
许振文表示,透过Spark搭建的运算丛集能更快速帮助他们将上百万笔的游戏用户资料,来放入分析系统中做即时分析处理,平均约50毫秒就能算出结果,并在Web浏览页面显示轮廓分析结果,相当快速,还可进一步做到多个资料报表之间的交叉分析比对,比如用户性别、居住地、付费金额和年龄的统计分布图,来找出背后的关联性的意义,以辅助公司高层能在最短时间内就能调整营运策略来因应。
腾讯游戏还针对了SparkSQL套件开发出图形操作界面,并在前不久将SparkSQL升级到2.0.1版本,开始运用在前置分析前跨不同账号的多款游戏之间的账号转换或数据封包转换的处理。
许振文指出,SparkSQL 2.0以前,SparkSQL还只适合处理简单的统计或资料查询工作,SparkSQL 2.0新版释出后,效能做了很大的提升,也开始能用于提供更复杂的资料查询和相关统计作业,以加快运算分析的速度。
不只能用于游戏资料的即时分析,腾讯游戏也将Spark运用在游戏行销和营运优化,来增加新游戏用户、提高活跃用户的黏着度,以及提升游戏玩家的回流率。许振文表示,他们采用了Spark Streaming搭建一个营销干预平台,能即时串流分析游戏资料,能做到用户一登入立即判断有无符合资格来推送奖励,还搭配Kafka来即时处理庞大的资料传递工作,并透过玩家收取奖励的反应情形,再进一步来分析,以找出提高用户体验的更好行销作法。
许振文解释说,线上即时行销的作法上,营运团队要先选好要插入行销活动的游戏用户群后,当目标对象的游戏玩家登入游戏后,就会即时将他们游戏中的使用记录下的各种数据资料,经由后端游戏服务器传到Kafka丛集后,再透过Spark Streaming来分析处理,能做到在用户登入游戏后的0.2秒内就能得知该目标用户已登入游戏中,之后再依据事先设好的过滤规则来触发相关事件。例如登入的玩家属于新用户或是长时间没登入的旧用户时,便会根据不同用户分类给予相对应的奖励、礼包或道具发送。
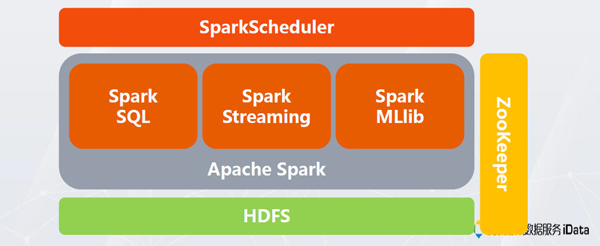
腾讯游戏将Spark运算丛集用于游戏资料的即时分析,由Spark、HDFS 、SparkScheduler、Zookeeper搭建而成。位于底层的储存层采用分散式档案系统HDFS,中间层则是Spark的核心,负责调度CPU运算资源和任务分配,并以SparkSQL、Spark Streaming和分散式机器学习套件MLlib使用最多,还使用ZooKeeper做为Spark分散式协作的集中管理工具,还自行开发了一个Spark Scheduler工具,能依据线上服务业务、用户或任务类型来动态调度。图片来源/许振文
相关文章
 YouTube更新违反规定政策,提升惩处透明度和一致性
YouTube更新违反规定政策,提升惩处透明度和一致性2023-12-31 14:00:52
 传苹果将把中国iCloud正式交给本地化经营 苹果手机icloud换区存储操作
传苹果将把中国iCloud正式交给本地化经营 苹果手机icloud换区存储操作2023-12-27 18:34:43
 刘德华代言什么手机?刘德华成华为Mate 60 RS非凡大师华为5G新手机代言人
刘德华代言什么手机?刘德华成华为Mate 60 RS非凡大师华为5G新手机代言人2023-09-26 21:55:08
 WebOS新系统:Palm Pre手机最新款高价登港
WebOS新系统:Palm Pre手机最新款高价登港2023-06-23 15:39:14
 帮助企业组织对抗勒索软件,资安通报机构设立防护专区,可协助事前、事中与事后因应
帮助企业组织对抗勒索软件,资安通报机构设立防护专区,可协助事前、事中与事后因应2023-06-22 09:36:10
 蔚来全系产品降价3万 取消免费换电 换一次电池180元
蔚来全系产品降价3万 取消免费换电 换一次电池180元2023-06-12 17:27:49
 电商平台三巨头开打最大规模折扣 价格战再次打响
电商平台三巨头开打最大规模折扣 价格战再次打响2023-03-05 18:58:40
 爱立信节省成本裁员四千人 爱立信全球员工总数五分之一
爱立信节省成本裁员四千人 爱立信全球员工总数五分之一2023-02-24 22:27:29
 蜜芽关停近况,八位数重金买三字顶级新域名mia.com也关闭
蜜芽关停近况,八位数重金买三字顶级新域名mia.com也关闭2023-02-23 16:18:14
 联想CEO杨元庆:联想集团需要裁员32%削减部分业务支出
联想CEO杨元庆:联想集团需要裁员32%削减部分业务支出2023-02-18 12:45:25
 蓝色光标2022营收亏损18亿 客户预算减少明显
蓝色光标2022营收亏损18亿 客户预算减少明显2023-02-18 12:40:08
 三星工厂或将80%生产转至越南 因本地劳动力成本上升
三星工厂或将80%生产转至越南 因本地劳动力成本上升2023-02-17 23:09:16
 香港八达通卡如何激活?没用失效过期余额怎么办
香港八达通卡如何激活?没用失效过期余额怎么办2023-02-17 18:34:51
 中兴通讯被曝将裁员20% 称只裁国外的
中兴通讯被曝将裁员20% 称只裁国外的2023-02-17 18:33:26
 苹果新iPhone15Pro手机终于改用USB-C(火牛)数据线??Lightning充电接口退出
苹果新iPhone15Pro手机终于改用USB-C(火牛)数据线??Lightning充电接口退出2023-02-17 16:57:22
 突发!蓝色光标曾为中国民企500强龙头 如今业绩亏损断崖下跌
突发!蓝色光标曾为中国民企500强龙头 如今业绩亏损断崖下跌2023-02-16 14:31:19
- 三星发布自家carplay车载中控系统 Car Mode for Galaxy 可以连接carplay吗?
2023-02-14 00:53:17
 Opera浏览器宣布集成ChatGPT 一键生成网页内容摘要
Opera浏览器宣布集成ChatGPT 一键生成网页内容摘要2023-02-14 00:32:08
 谷歌google计划重返进入中国市场?但结果可能令你失望
谷歌google计划重返进入中国市场?但结果可能令你失望2023-02-13 16:57:15
 Zoom紧急裁员1300人 佔员工总数15%
Zoom紧急裁员1300人 佔员工总数15%2023-02-08 14:59:11
最新资讯
- YouTube更新违反规定政策,提升惩处透明度和一致性2023-12-31 14:00:52
 美国法院裁定阿里须为Squishmallows玩具侵权案答辩2023-12-28 19:59:34
美国法院裁定阿里须为Squishmallows玩具侵权案答辩2023-12-28 19:59:34 小米汽车传员工3700人 雷军称小米汽车不可能卖9万92023-12-28 19:41:57
小米汽车传员工3700人 雷军称小米汽车不可能卖9万92023-12-28 19:41:57 吉利飙逾6% 电动车品牌极氪新车款极氪007昨上市 预售价格22.99万元2023-12-28 19:30:28
吉利飙逾6% 电动车品牌极氪新车款极氪007昨上市 预售价格22.99万元2023-12-28 19:30:28 日本丰田汽车厂11月全球产量创新高2023-12-28 19:26:02
日本丰田汽车厂11月全球产量创新高2023-12-28 19:26:02
手机
 中国11月手机出货量增34% 5G手机出货量2709.2万部2023-12-28 19:27:57
中国11月手机出货量增34% 5G手机出货量2709.2万部2023-12-28 19:27:57 荣耀发布新一代旗舰荣耀Magic5系列,新款上市价格分期0首付3999元起2023-03-06 16:12:32
荣耀发布新一代旗舰荣耀Magic5系列,新款上市价格分期0首付3999元起2023-03-06 16:12:32 美国商务部指违禁,长江存储被美国拜登制裁名单面临停工裁员2023-02-17 18:41:53
美国商务部指违禁,长江存储被美国拜登制裁名单面临停工裁员2023-02-17 18:41:53 苹果Apple iOS车载系统CarPlay支持哪些更多汽车品牌2023-02-02 17:33:27
苹果Apple iOS车载系统CarPlay支持哪些更多汽车品牌2023-02-02 17:33:27 香港去哪买三星手机回来吗? 买香港便宜售价手机市场地点和网站2023-02-02 11:03:11
香港去哪买三星手机回来吗? 买香港便宜售价手机市场地点和网站2023-02-02 11:03:11
数码
- 华为5G芯片正式亮相:预示华为将发首款5G手机2023-08-31 13:22:33
 腾讯传计划放弃虚拟现实VR硬件计划2023-02-17 23:32:30
腾讯传计划放弃虚拟现实VR硬件计划2023-02-17 23:32:30 三星手机份额大跌!三星手机中国市场份额变化国内仅剩3%2023-02-01 17:06:15
三星手机份额大跌!三星手机中国市场份额变化国内仅剩3%2023-02-01 17:06:15 三星手机份额大跌在中国没市场了!国内市场占有率仅剩1%国外比苹果销量高2023-02-01 16:59:53
三星手机份额大跌在中国没市场了!国内市场占有率仅剩1%国外比苹果销量高2023-02-01 16:59:53 vivo发布2022 vivoNEX手机极简易浏览器下载:简洁流畅无广告!2022-12-02 17:29:30
vivo发布2022 vivoNEX手机极简易浏览器下载:简洁流畅无广告!2022-12-02 17:29:30
科技
 中兴受美国制裁事件 被罚了20亿美元过程事件始末 中兴被制裁后公司现状2023-11-02 22:12:46
中兴受美国制裁事件 被罚了20亿美元过程事件始末 中兴被制裁后公司现状2023-11-02 22:12:46 B站怎么炸崩了哔哩哔哩服务器今日怎么又炸挂了?技术团队公开早先原因2023-03-06 19:05:55
B站怎么炸崩了哔哩哔哩服务器今日怎么又炸挂了?技术团队公开早先原因2023-03-06 19:05:55 苹果iPhoneXS/XR手机电池容量续航最强?答案揭晓2023-02-19 15:09:54
苹果iPhoneXS/XR手机电池容量续航最强?答案揭晓2023-02-19 15:09:54 华为荣耀两款机型起内讧:荣耀Play官方价格同价同配该如何选?2023-02-17 23:21:27
华为荣耀两款机型起内讧:荣耀Play官方价格同价同配该如何选?2023-02-17 23:21:27 google谷歌原生系统Pixel3 XL/4/5/6 pro手机价格:刘海屏设计顶配版曾卖6900元2023-02-17 18:58:09
google谷歌原生系统Pixel3 XL/4/5/6 pro手机价格:刘海屏设计顶配版曾卖6900元2023-02-17 18:58:09