
架构说明
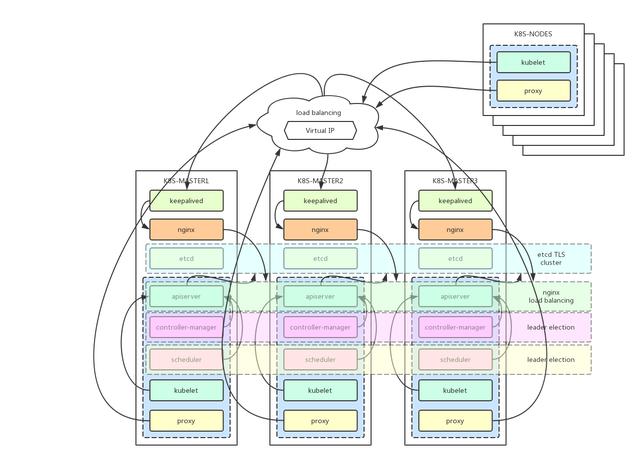
Kubernetes丛集元件:
etcd 一个高可用的K/V键值对储存和服务发现系统flannel 实现夸主机的容器网络的通讯kube-apiserver 提供kubernetes丛集的API呼叫kube-controller-manager 确保丛集服务kube-scheduler 排程容器,分配到Nodekube-proxy 提供网络代理服务kubeadm:用来初始化丛集的指令。kubectl: 用来与丛集通讯的命令列工具。通过kubectl可以部署和管理应用,检视各种资源,建立、删除和更新各种元件。kubelet 执行在丛集中的每个节点上,用来启动 pod 和 container 等。k8s丛集高可用,一般是etcd,kube-apiserver,kube-controller-manager,kube-scheduler服务元件的高可用。
规划:
3个master节点,2个worker节点,使用keepalived+haproxy做高可用
一、前期环境准备
修改所有主机的hosts档案cat >/etc/hosts130.252.10.235 node1
130.252.10.236 node2
130.252.10.237 node3
130.252.10.238 node4
130.252.10.239 node5
EOF
同步时间ntpdate time.windows.com
hwclock --systohc
禁用selinux,需要重启setenforce 0
sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/sysconfig/selinux
sed -i 's/^SELINUX=.*/SELINUX=disabled/' /etc/selinux/config
核心引数修改cat /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_nonlocal_bind = 1
net.ipv4.ip_forward = 1
vm.swappiness = 0
EOF
sysctl --system
关闭系统swapKubernetes 1.8开始要求关闭系统的Swap,如果不关闭,预设配置下kubelet将无法启动。
方法一 通过kubelet的启动引数–fail-swap-on=false更改这个限制。
方法二 关闭系统的Swap, swapoff -a
修改/etc/fstab档案,注释掉SWAP的自动挂载,使用free -m确认swap已经关闭。
swapoff -a
sed -i '/ swap / s/^(.*)$/#/g' /etc/fstab
关闭防火墙,生产环境不建议关闭防火墙systemctl disable firewalld.service
systemctl stop firewalld.service
systemctl disable postfix
载入ipvs核心模组cat > /etc/sysconfig/modules/ipvs.modules #!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
EOF
chmod 755 /etc/sysconfig/modules/ipvs.modules
bash /etc/sysconfig/modules/ipvs.modules
lsmod | grep -e ip_vs -e nf_conntrack_ipv4
二、docker安装
安装docker-ce,所有节点都要安装
yum-utils 提供yum-config-manager工具,devicemapper储存需要device-mapper-persistent-data和lvm2
yum install -y yum-utils device-mapper-persistent-data lvm2
新增yum源仓库
官方仓库
yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
安装docker
yum -y install docker-ce docker-ce-cli containerd.io
启动docker,设定开机启动docker
systemctl start docker
systemctl enable docker
systemctl list-unit-files |grep docker
配置docker中国映象加速器,修改cgroup driver为systemd,k8s建议使用systemd,配置后重启docker
cat > /etc/docker/daemon.json {
"registry-mirrors": ["https://registry.docker-cn.com", "https://docker.mirrors.ustc.edu.cn"],
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2",
"storage-opts": [
"overlay2.override_kernel_check=true"
]
}
EOF
systemctl restart docker
三、安装haproxy,keepalived
安装haproxy和keepalived,实现kube-apiserver高可用
psmisc提供killall命令
yum install keepalived haproxy psmisc ipvsadm -y
配置haproxy
cp /etc/haproxy/haproxy.cfg /etc/haproxy/haproxy.cfg.bak
cat > /etc/haproxy/haproxy.cfg global
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
stats socket /var/lib/haproxy/stats
defaults
mode tcp
log global
option tcplog
option dontlognull
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
listen stats
mode http
bind :10086
stats enable
stats uri /admin?stats
stats auth admin:admin
stats admin if TRUE
frontend k8s_https *:8443
mode tcp
maxconn 2000
default_backend https_sri
backend https_sri
balance roundrobin
server s1 130.252.10.235:6443 check inter 2000 fall 3 rise 3 weight 1
server s2 130.252.10.236:6443 check inter 2000 fall 3 rise 3 weight 1
server s3 130.252.10.237:6443 check inter 2000 fall 3 rise 3 weight 1
EOF
haproxy 在 10086 埠输出 status 资讯;haproxy 监听所有界面的 8443 埠,该埠与环境变数 ${KUBE_APISERVER} 指定的埠必须一致;server 字段列出所有 kube-apiserver 监听的 IP 和埠;配置keepalived
cp /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf.bak
cat > /etc/keepalived/keepalived.conf ! Configuration File for keepalived
global_defs {
script_user root
enable_script_security
router_id LVS_MASTER
}
vrrp_script check-haproxy {
script "/usr/bin/killall -0 haproxy"
interval 3
weight -30
}
vrrp_instance VI_kube-master {
state MASTER
interface ens32
virtual_router_id 60
dont_track_primary
priority 120
advert_int 3
track_script {
check-haproxy
}
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
130.252.10.233
}
}
EOF
注意:在另外两个节点,设定state为BACKUP,priority设定为110,100
启动所有节点的haproxy和keepalived
systemctl restart haproxy && systemctl enable haproxy && systemctl status haproxy
systemctl restart keepalived && systemctl enable keepalived && systemctl status keepalived
检视VIP
注意,使用ifconfig命令是看不到的,必须使用ip addr命令
# ip addr
1: lo: mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens32: mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:25:f1:8d brd ff:ff:ff:ff:ff:ff
inet 130.252.10.235/16 brd 130.252.255.255 scope global noprefixroute ens32
valid_lft forever preferred_lft forever
inet 130.252.10.233/32 scope global ens32
valid_lft forever preferred_lft forever
inet6 fe80::ece5:efc4:1cf1:2d7c/64 scope link noprefixroute
valid_lft forever preferred_lft forever
3: docker0: mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:88:7f:d3:1a brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
这时候vip在130.252.10.235上,我们关闭235上的haproxy,验证vip是否会漂移到其他节点
四、kubeadm/kubelet/kubectl安装
master节点安装:kubeadm、kubelet、kubectl
node节点安装:kubeadm、kubelet
kubeadm: 部署丛集用的命令kubelet: 在丛集中每台机器上都要执行的元件,负责管理pod、容器的生命周期kubectl: 丛集管理工具(可选,只要在控制丛集的节点上安装即可)cat /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
exclude=kube*
EOF
安装
yum install -y kubelet kubeadm kubectl
systemctl enable kubelet
五、使用kubeadm初始化cluster
step1 准备初始化配置档案
根据自己的环境修改配置.
apiVersion: kubeadm.k8s.io/v1beta1
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 130.252.10.235
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
name: node1
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/master
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta1
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controlPlaneEndpoint: "130.252.10.233:8443"
controllerManager: {}
dns:
type: CoreDNS
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: k8s.gcr.io
kind: ClusterConfiguration
kubernetesVersion: v1.14.3
networking:
dnsDomain: cluster.local
podSubnet: "10.244.0.0/16"
serviceSubnet: 10.96.0.0/12
scheduler: {}
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
featureGates:
SupportIPVSProxyMode: true
mode: ipvs
---
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
failSwapOn: false
cgroupDriver: systemd
step2 处理kubernetes依赖的映象
master需要的映象为
kube-apiserver
kube-controller-manager
kube-scheduler
kube-proxy
coredns
pause
etcd
flannel
node节点需要的映象为
kube-proxy
pause
flannel
检视需要的映象版本
kubeadm config images list --kubernetes-version=v1.14.3
拉取映象
kubeadm config images pull
六、初始化第一个master节点
注意:如果你禁用了swap分割槽,则不需要加--ignore-preflight-errors=Swap
# kubeadm init --config kubeadm-init.yaml --ignore-preflight-errors=Swap
配置kubectl
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config
启用kubectl的自动补全命令
yum install bash-completion -y
echo "source > ~/.bashrc
七、安装Pod网络flannel
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
八、将其他master节点新增到cluster
将node1证书档案复制到其他master节点node2,node3
for host in node2 node3
do
echo ">>>>>>>>>>>>>>>>>>>>$host ssh $host "mkdir -p /etc/kubernetes/pki/etcd"
scp /etc/kubernetes/pki/ca.* $host:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/sa.* $host:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/front-proxy-ca.* $host:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/etcd/ca.* $host:/etc/kubernetes/pki/etcd/
scp /etc/kubernetes/admin.conf $host:/etc/kubernetes/
done
分别在master1和master2 执行下面的命令
kubeadm join 130.252.10.233:8443 --token abcdef.0123456789abcdef
--discovery-token-ca-cert-hash sha256:4d95989174b67c857bed7313750e021f07ec56beb2e6e764c7ef2de5645187e9
--experimental-control-plane --ignore-preflight-errors=Swap
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config
九、将node节点新增到cluster
kubeadm join 130.252.10.233:8443 --token abcdef.0123456789abcdef
--discovery-token-ca-cert-hash sha256:4d95989174b67c857bed7313750e021f07ec56beb2e6e764c7ef2de5645187e9
--ignore-preflight-errors=Swap
十、检查丛集执行健康
在master节点检视节点状态
# kubectl get nodes
NAME STATUS ROLES AGE VERSION
node1 Ready master 15m v1.14.3
node2 Ready master 12m v1.14.3
node3 Ready master 10m v1.14.3
node4 Ready 25s v1.14.3
node5 Ready 2m34s v1.14.3
# kubectl get cs
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health":"true"}
所有的节点都是NotReady,这是因为每个节点都需要启动若干元件,这些元件都是在pod中执行,需要从Google下载映象
检视pod的状态
# kubectl get pod --all-namespaces -o wide
检视丛集资讯
# kubectl cluster-info
Kubernetes master is running at https://130.252.10.233:8443
KubeDNS is running at https://130.252.10.233:8443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
检视etcd丛集
检视丛集是否健康
# docker run --rm -it --net host
-v /etc/kubernetes:/etc/kubernetes k8s.gcr.io/etcd:3.3.10 etcdctl
--cert-file /etc/kubernetes/pki/etcd/peer.crt
--key-file /etc/kubernetes/pki/etcd/peer.key
--ca-file /etc/kubernetes/pki/etcd/ca.crt
--endpoints https://130.252.10.235:2379 cluster-health
检视丛集的leader
# docker run --rm -it --net host
-v /etc/kubernetes:/etc/kubernetes k8s.gcr.io/etcd:3.3.10 etcdctl
--cert-file /etc/kubernetes/pki/etcd/peer.crt
--key-file /etc/kubernetes/pki/etcd/peer.key
--ca-file /etc/kubernetes/pki/etcd/ca.crt
--endpoints https://130.252.10.235:2379 member list
注意:因为是3个节点的ETCD丛集,所以只能有一个宕机,如果同时又2个节点宕机,则会出现问题Unable to connect to the server: EOF
etd丛集需要大多数节点(仲裁)才能就丛集状态的更新达成一致,所以ETCD丛集节点一般是奇数个,而且只有存活节点个数大于下线节 点个数才能正常执行,5个节点的ETCD丛集,允许同时2个节点故障。
一般建议5个节点,超过五个虽然容错性更高,但是丛集写入性就会差。
检查IPVS
# ipvsadm -ln


































