3D����ͷ����Ŀ���⣬���������״�ijɼ���������������
2018-11-26 15:11
��һ������ͷ���µ�ͼ����3DĿ���⣬�����ж��ѣ�Ŀǰ���Ƚ�ϵͳ�ijɼ�Ҳ�����ü����״���������1/10��
һ�����Խ��ŵ��о����õ�����ͷ���������������������״�ijɼ���
���к���������Twitter�Ͼ�����
����ܲ��ܽ����˹�����ü����״�����⣿��˹���㿴����û��
��“ֱ��”�ж�
Ϊ���˵���������3Dʶ�𣬶����ȴ��������
��Ϊֱ����
���ܹ�����ԶС������ӹ�ϵ���ó�����Ĵ�С�����λ�ù�ϵ��
������ʶ�������2D��Ƭ����3Dͼ����ƽ���ϵ�ͶӰ���Ѿ�ʧȥ�˾�����Ϣ��
Ϊ��ʶ������Զ�������˳���Ҫ��װ�����״ͨ���ز��������ľ�����Ϣ����һ����ֻ�ܻ��2D��Ϣ������ͷ���������ġ�
Ϊ��������ͷҲ��3D�����������������ƪ���������һ��“��ͶӰ����ת��”��OFT���㷨��
���߰������㷨�Ͷ˵��˵����ѧϰ�ܹ������������KITTI 3DĿ����������ʵ�������ȵijɼ���
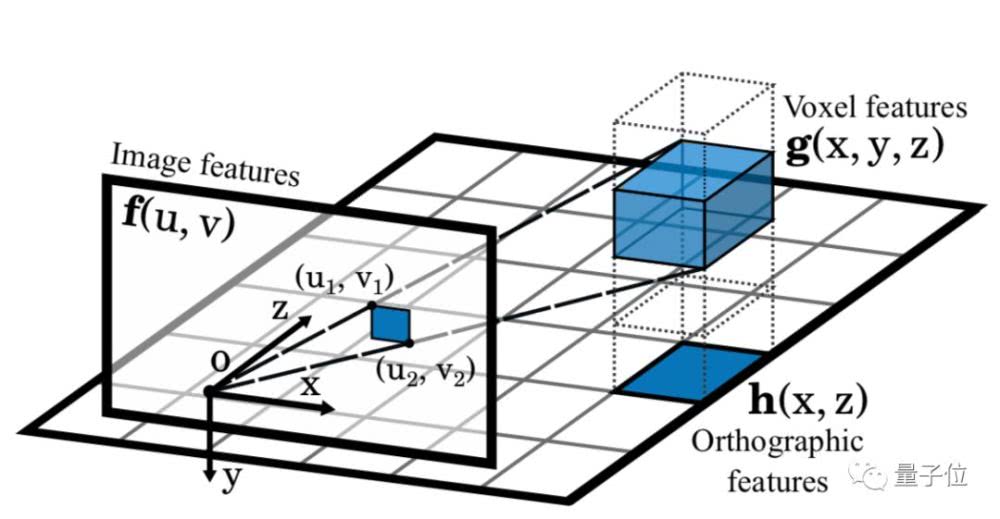
�����㷨����5�����֣�
ǰ��ResNet������ȡ�������ڴ�����ͼ������ȡ��߶�����ͼ��
���������任����ÿ���߶ȵĻ���ͼ�������ͼ�任Ϊ��ͶӰ���ͼ��ʾ��
���϶��µ����磬��һϵ��ResNet���Ԫ��ɣ���һ�ֶ�ͼ���й۲쵽�Ĺ۲�Ч������ķ�ʽ�������ͼ����ͼ��
һ�����ͷ��Ϊÿ��������͵�ƽ���ϵ�ÿ��λ���������ŷ�����λ��ƫ�ơ�ά��ƫ�ƺͷ������������ݡ�
��������ƺͽ���Σ�ʶ������ͼ�еķ�ֵ��������ɢ�߽��Ԥ�⡣
���ַ���ͨ��������ͼ�������ӳ�䵽һ������3D�ռ��У�������ͼ��������������3D�ռ�������������һ�¡�����Ҳ��������ġ�
Ч��Զ��Mono3D
�������Զ���ʻ���ݼ�KITTI��3712��ѵ��ͼ��3769��ͼ���ѵ�������������м�⡣��ʹ�òü������ź�ˮƽ��ת�Ȳ�����������ͼ�����ݼ�������������
��������˸���KITTI 3D�������������������ķ���������Ҫ��ÿ��Ԥ���3D�߽��Ӧ����Ӧʵ������߿��ཻ�����������������Ϊ70�����������˺������г���ӦΪ50����
��ǰ�˵�Mono3D�����Աȣ�OFT�����ͼƽ����ȷ�ȡ�3D����߽�ʶ���ϸ�����Գɼ��Ͼ����ڶ��֡�
������̽��Զ������ʱҪԶ��Mono3D��Զ����ʶ����������������ࡣ�����������ڵ����ضϵ������������ȷʶ������塣��ijЩ�����������ﵽ��3DOPϵͳ��ˮƽ��
������Զ�����ϣ���ͶӰ����ת����OFT-Net���ڶԲ�ͬ���������������ʱ��������Mono3D��
������Mono3D��ȣ�����ϵͳ����Ҳ���Խ��͵ø�����������Ϊ������ϵͳ����Զ�������������ɵġ�
���������ͼ�ռ��е�����������������ܡ�Ϊ����֤��һ˵���������л�������һ���о��������϶��µ�������ɾ��ͼ�㡣
��ͼ��ʾ�����ֲ�ͬ��ϵ�ṹ��ƽ����������������Ĺ�ϵͼ��
���ƺ����ԣ������϶���������ɾ��ͼ������Ž������ܡ�
���������½���һ����ԭ������ǣ��������϶�������Ĺ�ģ�ή�������������ȣ��Ӷ������������������
��ͼ�п��Կ��������þ��д������϶��������dzǰ�ˣ�ResNet-18��������ʵ�ֱ�û���κ����϶��²�ĸ�������磨ResNet-34�����õ����ܣ����������ּܹ����д�����ͬ�����IJ�����

�������
 王健林许家印游艇曝光 网友:这次真是贫穷限制了我们的想像力
王健林许家印游艇曝光 网友:这次真是贫穷限制了我们的想像力2018-04-16 16:32
 三季度全球可穿戴设备出货量上涨94.6%,苹果稳…
三季度全球可穿戴设备出货量上涨94.6%,苹果稳…2019-12-10 17:52
 Samsung新专利曝光全面屏没有刘海
Samsung新专利曝光全面屏没有刘海2018-05-13 13:33
 全幅高速连拍Canon1DX单机售28800元
全幅高速连拍Canon1DX单机售28800元2018-04-09 17:32
 华为Mate X预计供货20万台左右
华为Mate X预计供货20万台左右2019-06-30 15:50
 轻量级入门机:FujifilmX-M1无反登场
轻量级入门机:FujifilmX-M1无反登场2018-01-03 12:00
 闪光灯竟有这么多花样魅蓝E2评测
闪光灯竟有这么多花样魅蓝E2评测2018-05-29 19:33
 中科循环经济研究院在沧州成立
中科循环经济研究院在沧州成立2020-12-28 16:52
 2018春节第一新机 魅蓝E3背面设计捉眼
2018春节第一新机 魅蓝E3背面设计捉眼2019-02-19 05:37
 iPhone6Plus搜不到WiFi 手机店没修好 大神思路清晰一招搞定
iPhone6Plus搜不到WiFi 手机店没修好 大神思路清晰一招搞定2018-05-02 14:31
 阿里YunOS即将到来 目前已有国产手机支持 期待吗?
阿里YunOS即将到来 目前已有国产手机支持 期待吗?2018-04-29 20:31
 霸屏了!问卷网八周年感恩回馈活动火热进行中!
霸屏了!问卷网八周年感恩回馈活动火热进行中!2021-07-22 19:46
 360摄像机3C云台电池版开启预售 创新“不插电…
360摄像机3C云台电池版开启预售 创新“不插电…2021-03-20 09:54
 外媒报道:LG正研发新款翻盖式可折叠手机
外媒报道:LG正研发新款翻盖式可折叠手机2018-07-06 05:31
- 扎克伯格夫妇约会给孩子言传身教 扎克伯格家首次曝光
2019-12-05 18:53
 5799元起 三星GalaxyS9/S9+勃艮第红版发布 三大女神代言
5799元起 三星GalaxyS9/S9+勃艮第红版发布 三大女神代言2018-05-08 17:32
 印度造iPhone终于上市 但果粉依旧很失望
印度造iPhone终于上市 但果粉依旧很失望2018-09-22 00:32
 更生行薪酬ETC:智能薪酬市场的领跑者
更生行薪酬ETC:智能薪酬市场的领跑者2019-08-20 11:55
 魔兽争霸:守城关卡的设定十分经典 那么战役中最经典的是哪关?_希尔瓦娜斯
魔兽争霸:守城关卡的设定十分经典 那么战役中最经典的是哪关?_希尔瓦娜斯2019-06-30 14:46
 脑洞飘出天际的科研队伍开发出3D打印水质检测器
脑洞飘出天际的科研队伍开发出3D打印水质检测器2018-08-05 18:31