
前沿|通用句子语义编码器 谷歌在语义文本相似性上的探索
消息来源:baojiabao.com 作者: 发布时间:2026-07-29
选自Google AI Blog
作者:Yinfei Yang
机器之心编译
参与:
Pedro、蒋思源
近年来,基于神经网络的自然语言理解研究取得了快速发展(尤其是学习语义文本表示),这些深度方法给人们带来了全新的应用,且还可以帮助提高各种小数据集自然语言任务的性能。本文讨论了两篇关于谷歌语义表示最新进展的论文,以及两种可在 TensorFlow Hub 上下载的新模型。
语义文本相似度
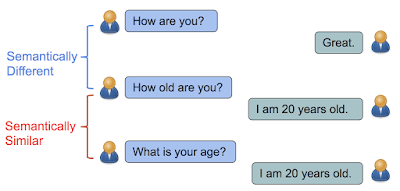
在“Learning Semantic Textual Similarity from Conversations”这篇论文中,我们引入一种新的方式来学习语义文本相似的句子表示。直观的说,如果句子的回答分布相似,则它们在语义上是相似的。例如,“你多大了?”以及“你的年龄是多少?”都是关于年龄的问题,可以通过类似的回答,例如“我 20 岁”来回答。相比之下,虽然“你好吗?”和“你多大了?”包含的单词几乎相同,但它们的含义却大相径庭,所以对应的回答也相去甚远。
论文地址:https://arxiv.org/abs/1804.07754
如果句子可以通过相同的答案来回答,那么句子在语义上是相似的。否则,它们在语义上是不同的。
这项工作中,我们希望通过给回答分类的方式学习语义相似性:给定一个对话输入,我们希望从一批随机选择的回复中分类得到正确的答案。但是,任务的最终目标是学习一个可以返回表示各种自然语言关系(包括相似性和相关性)的编码模型。我们提出了另一预测任务(此处是指 SNLI 蕴含数据集),并通过共享的编码层同时推进两项任务。利用这种方式,我们在 STSBenchmark 和 CQA task B 等相似度度量标准上取得了更好的表现,究其原因,是简单等价关系与逻辑蕴含之间存在巨大不同,后者为学习复杂语义表示提供了更多可供使用的信息。
对于给定的输入,分类可以认为是一种对所有可能候选答案的排序问题。
通用句子编码器
“Universal Sentence Encoder”这篇论文介绍了一种模型,它通过增加更多任务来扩展上述的多任务训练,并与一个类似 skip-thought 的模型联合训练,从而在给定文本片段下预测句子上下文。然而,我们不使用原 skip-thought 模型中的编码器 - 解码器架构,而是使用一种只有编码器的模型,并通过共享编码器来推进预测任务。利用这种方式,模型训练时间大大减少,同时还能保证各类迁移学习任务(包括情感和语义相似度分类)的性能。这种模型的目的是为尽可能多的应用(释义检测、相关性、聚类和自定义文本分类)提供一种通用的编码器。
论文地址:https://arxiv.org/abs/1803.11175
成对语义相似性比较,结果为 TensorFlow Hub 通用句子编码器模型的输出。
正如文中所说,通用句子编码器模型的一个变体使用了深度平均网络(DAN)编码器,而另一个变体使用了更加复杂的自注意力网络架构 Transformer。
“Universal Sentence Encoder”一文中提到的多任务训练。各类任务及结构通过共享的编码层/参数(灰色框)进行连接。
随着其体系结构的复杂化,Transformer 模型在各种情感和相似度分类任务上的表现都优于简单的 DAN 模型,且在处理短句子时只稍慢一些。然而,随着句子长度的增加,使用 Transformer 的计算时间明显增加,但是 DAN 模型的计算耗时却几乎保持不变。
新模型
除了上述的通用句子编码器模型之外,我们还在 TensorFlow Hub 上共享了两个新模型:大型通用句型编码器通和精简版通用句型编码器。
大型:https://www.tensorflow.org/hub/modules/google/universal-sentence-encoder-large/1
精简:https://www.tensorflow.org/hub/modules/google/universal-sentence-encoder-lite/1
这些都是预训练好的 Tensorflow 模型,给定长度不定的文本输入,返回一个语义编码。这些编码可用于语义相似性度量、相关性度量、分类或自然语言文本的聚类。
大型通用句型编码器模型是用我们介绍的第二篇文章中提到的 Transformer 编码器训练的。它针对需要高精度语义表示的场景,牺牲了速度和体积来获得最佳的性能。
精简版模型使用 Sentence Piece 辞汇库而非单词进行训练,这使得模型大小显著减小。它针对内存和 CPU 等资源有限的场景(如小型设备或浏览器)。
我们很高兴与大家分享这项研究以及这些模型。这只是一个开始,并且仍然还有很多问题亟待解决,如将技术扩展到更多语言上(上述模型目前仅支持英语)。我们也希望进一步地开发这种技术,使其能够理解段落甚至整个文档。在实现这些目标的过程中,很有可能会产生出真正的“通用”编码器。
原文链接:https://ai.googleblog.com/2018/05/advances-in-semantic-textual-similarity.html
本文为机器之心编译,
转载请联系本公众号获得授权
。?------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:
content
@jiqizhixin.com广告&商务合作:bd@jiqizhixin.com
相关文章
 B站怎么炸崩了哔哩哔哩服务器今日怎么又炸挂了?技术团队公开早先原因
B站怎么炸崩了哔哩哔哩服务器今日怎么又炸挂了?技术团队公开早先原因2023-03-06 19:05:55
 苹果iPhoneXS/XR手机电池容量续航最强?答案揭晓
苹果iPhoneXS/XR手机电池容量续航最强?答案揭晓2023-02-19 15:09:54
 华为荣耀两款机型起内讧:荣耀Play官方价格同价同配该如何选?
华为荣耀两款机型起内讧:荣耀Play官方价格同价同配该如何选?2023-02-17 23:21:27
 google谷歌原生系统Pixel3 XL/4/5/6 pro手机价格:刘海屏设计顶配版曾卖6900元
google谷歌原生系统Pixel3 XL/4/5/6 pro手机价格:刘海屏设计顶配版曾卖6900元2023-02-17 18:58:09
 科大讯飞同传同声翻译软件造假 浮夸不能只罚酒三杯
科大讯飞同传同声翻译软件造假 浮夸不能只罚酒三杯2023-02-17 18:46:15
 华为mate20pro系列手机首发上市日期价格,屏幕和电池参数配置对比
华为mate20pro系列手机首发上市日期价格,屏幕和电池参数配置对比2023-02-17 18:42:49
 小米MAX4手机上市日期首发价格 骁龙720打造大屏标准
小米MAX4手机上市日期首发价格 骁龙720打造大屏标准2023-02-17 18:37:22
 武汉弘芯遣散!结局是总投资1280亿项目烂尾 光刻机抵押换钱
武汉弘芯遣散!结局是总投资1280亿项目烂尾 光刻机抵押换钱2023-02-16 15:53:18
 谷歌GoogleDrive网云盘下载改名“GoogleOne” 容量提升价格优惠
谷歌GoogleDrive网云盘下载改名“GoogleOne” 容量提升价格优惠2023-02-16 13:34:45
 巴斯夫将裁员6000人 众化工巨头裁员潮再度引发关注
巴斯夫将裁员6000人 众化工巨头裁员潮再度引发关注2023-02-13 16:49:06
 人手不足 韵达快递客服回应大量包裹派送异常没有收到
人手不足 韵达快递客服回应大量包裹派送异常没有收到2023-02-07 15:25:20
 资本微念与李子柒销声匿迹谁赢? 微念公司退出子柒文化股东
资本微念与李子柒销声匿迹谁赢? 微念公司退出子柒文化股东2023-02-02 09:24:38
 三星GalaxyS8 S9 S10系统恢复出厂设置一直卡在正在检查更新怎么办
三星GalaxyS8 S9 S10系统恢复出厂设置一直卡在正在检查更新怎么办2023-01-24 10:10:02
 华为Mate50 RS保时捷最新款顶级手机2022多少钱?1.2万元售价外观图片吊打iPhone14
华为Mate50 RS保时捷最新款顶级手机2022多少钱?1.2万元售价外观图片吊打iPhone142023-01-06 20:27:09
 芯片常见的CPU芯片封装方式 QFP和QFN封装的区别?
芯片常见的CPU芯片封装方式 QFP和QFN封装的区别?2022-12-02 17:25:17
 华为暂缓招聘停止社招了吗?官方回应来了
华为暂缓招聘停止社招了吗?官方回应来了2022-11-19 11:53:50
 热血江湖手游:长枪铁甲 刚猛热血 正派枪客全攻略技能介绍大全
热血江湖手游:长枪铁甲 刚猛热血 正派枪客全攻略技能介绍大全2022-11-16 16:59:09
 东京把玩了尼康微单相机Z7 尼康Z7现在卖多少钱?
东京把玩了尼康微单相机Z7 尼康Z7现在卖多少钱?2022-10-22 15:21:55
 苹果iPhone手机灵动岛大热:安卓灵动岛App应用下载安装量超100万次
苹果iPhone手机灵动岛大热:安卓灵动岛App应用下载安装量超100万次2022-10-03 22:13:45
 苹果美版iPhone可以在中国保修 从哪看怎么查询iPhone的生产日期?
苹果美版iPhone可以在中国保修 从哪看怎么查询iPhone的生产日期?2022-09-22 10:00:07











