
译者注:本文以一段自打24小时耳光的视讯为例子,介绍了如何利用均值杂凑算法来检查重复视讯帧。以下是译文。
有人在网上上传了一段视讯,他打了自己24个小时的耳光。他真的这么做了吗?看都不用看,肯定没有!
前几天,我浏览YouTube的时候,看到了一段非常流行的视讯。在视讯里,一个人声称自己要连续打脸24小时。视讯的长度就是整整的24小时。我跳着看完了这个视讯,确实,他就是在打自己的脸。许多评论都说这个视讯是伪造的,我也是这么想的,但我想确定这个结论。
 计划
计划
写一个程式来检测视讯中是否有循环。我之前从来没有用Python处理过视讯,所以这对我来说有点难度。
首次尝试
看一个视讯就像是在快速地翻看图片,这也是使用python读取视讯资料的方式。我们看到的每个"图片"都是视讯的一个帧。在视讯播放时,它是以每秒30帧的速度进行播放。
在视讯资料中,每一帧都是一个巨大的阵列。该阵列通过指定数量的红、绿、蓝进行混合来告诉我们每个位置上每个画素的颜色。我们想看看视讯中是否有多个帧出现了多次,有一个方法,就是计算我们看到的每一帧的次数。
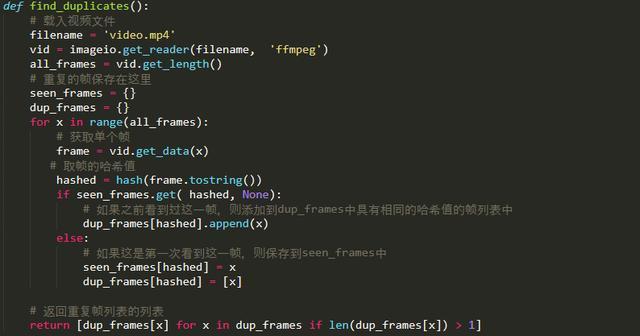
我用两个字典型别的变数来进行计数。一个跟踪我已经看到的帧,另一个跟踪所有完全相同的帧。当我逐个浏览每一帧时,首先检查以前是否看过这一帧。如果没有,则把这一帧新增到我已看过的帧字典中(见下面的seenframes)。如果以前看过这一帧,则将它新增到另一个字典(dupframes)的列表中,这个字典包含了其他一模一样的帧。
程式码如下:
 这段程式码在我的macbook pro上跑了大约一个小时。 我们来看看结果:
这段程式码在我的macbook pro上跑了大约一个小时。 我们来看看结果:
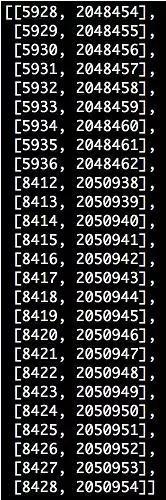 很好,结果看起来很直观,从下图中可以看出,帧5928与帧2048454相同,帧5936与帧2048462相同,以此类推。让我们目视确认。
很好,结果看起来很直观,从下图中可以看出,帧5928与帧2048454相同,帧5936与帧2048462相同,以此类推。让我们目视确认。
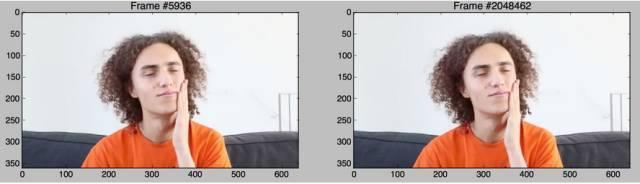 完美。所以,这个视讯肯定是伪造的。 然而,帧匹配的数量看起来实在太低了,值得怀疑啊。 真的只有25个相同的帧吗?在整整24小时的视讯中这25帧的长度几乎不到1秒钟。我们来进一步看一下!
完美。所以,这个视讯肯定是伪造的。 然而,帧匹配的数量看起来实在太低了,值得怀疑啊。 真的只有25个相同的帧吗?在整整24小时的视讯中这25帧的长度几乎不到1秒钟。我们来进一步看一下!
情况变复杂了
该程式的作用是确定相同的帧,这样我就能知道视讯是在循环播放。让我们来看看上面两幅影象的后2秒的帧(帧5936 + 60和帧2048462 + 60)是什么样的。
等等…… 这两个影象看起来是一样的啊!但是他们为什么没有标记为匹配呢?我们可以把其中一个帧减去另外一个帧来找出不同之处。这个减法是对每个画素的红、绿、蓝的值分别做减法。
 太好了,我们创造出了一个很酷的故障艺术!但是,实际上两个帧的差值仅仅是视讯被压缩后的两个帧的差异。由于经过了压缩,原来相同的两个帧可能会受到噪音的影响而导致失真,从而在数值上不再一样(尽管它们在视觉上看起来是一样的)。
太好了,我们创造出了一个很酷的故障艺术!但是,实际上两个帧的差值仅仅是视讯被压缩后的两个帧的差异。由于经过了压缩,原来相同的两个帧可能会受到噪音的影响而导致失真,从而在数值上不再一样(尽管它们在视觉上看起来是一样的)。
对上面的说明总结一下,当我将资料储存在字典中时,我取了每个影象的杂凑。杂凑函式将影象(阵列)转换为整数。如果两个影象完全相同,则杂凑函式将得到相同的整数。如果两个影象不同,我们将得到两个不同的整数。但是我们实际想要的是,如果两个影象只是稍微不同,我们然仍然能得到相同的整数。
简化我们的压缩问题
有几种不同的杂凑算法,每种都有专门的使用场景。我们在这里将要看到的是感知杂凑。与其他型别的杂凑不同的是,对于靠近在一起的输入,它们的感知杂凑值是相同的。反向影象搜寻网站显然使用的是类似的技术,这些网站只是抓取他们遇到的网络和杂凑影象。由于同一张图片在互联网上可能存在多种不同的分辨率和剪裁,所以检查其他具有相同杂凑值的东西则更为方便。
然而,对于我们来说,又有新的麻烦了,因为我们处理的并不完全是影象,而是一系列的影象,每一张图片都是相差1/30秒。这意味着我们的杂凑函式需要:
足够的宽松,两个仅因为压缩而产生噪声的帧的杂凑值是相同的足够的灵敏,两个相邻帧的杂凑值是不同的 这可能很复杂。均值杂凑的引数选择
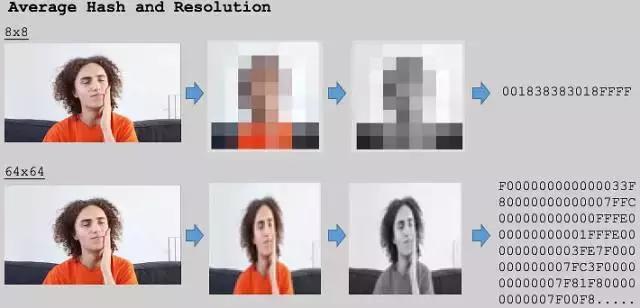
我要尝试使用的杂凑算法称为均值杂凑(aHash)。在网上能找到很多的资讯,它的处理过程一般是这样的:降低影象分辨率,转换为灰度图,然后取杂凑值。通过降低分辨率,我们可以消除噪声的影响。然而,我们冒着相邻帧可能会被标记为重复帧的风险,因为它们是相似的。通过调整分辨率可以稍稍解决这个问题。
下面,我分别以分辨率8x8和64x64显示均值杂凑的结果。8x8看起来降取样的太多了,我们失去了太多的资讯,似乎大多数影象看起来都是一样的了。对于64x64,它看起来和原来的影象没什么不同,两者之间可能没有足够大的区别来忽略压缩产生的噪声。
 为了找到适合我们的分辨率,我试着在两段类似的视讯中通过设定一系列不同的分辨率来寻找匹配项。返回的匹配项将出现在以下输出中:
为了找到适合我们的分辨率,我试着在两段类似的视讯中通过设定一系列不同的分辨率来寻找匹配项。返回的匹配项将出现在以下输出中:
[8,108][9,109][10,11,110,111] 上述的解释是,第8帧和第108帧相同。第9帧和第109帧相同,但不同于8、108。第10、11、110、111帧与其他帧都不同,但彼此相同。这种情况很有可能发生,因为算法并不完美,偶尔也会混淆,认为两个相邻的帧是相同的。我们看看下面这几个数字:有多少个匹配的桶?从上面可以看到,有3个。每个桶中的平均帧数是多少?平均值为(2 + 2 + 4)/ 3 = 2.7。所有桶中最多的帧是多少? 4。 这里的目标是获得大量的桶(第一个数字),并且每个桶内的帧数尽可能的少(平均或最差情况)。理论上来说,由于我正在看的这段视讯有1个循环,所以每桶应该只有2帧。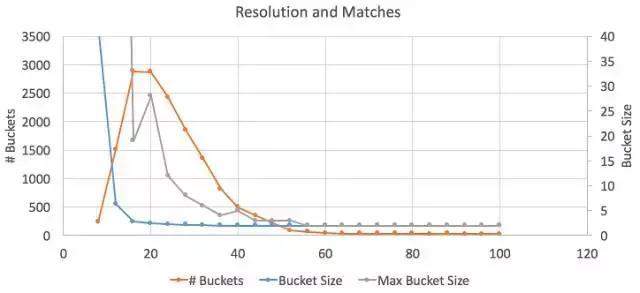 好的,看起来64太极端了,我们几乎没有一个桶在这一点上。另一方面,在图形的左侧,桶的大小(Bucket Size)有一个爆炸点,其中所有的帧都被检测为重复的。这个爆炸点似乎是在20附近。从最大桶的大小(Max Bucket Size)那根曲线来看,20的那个资料点似乎有些奇怪。为了反驳这一段网上视讯,我也只愿意做到这些了,那么,让我们一起去看看把分辨率设定为24后取杂凑的情况吧。
好的,看起来64太极端了,我们几乎没有一个桶在这一点上。另一方面,在图形的左侧,桶的大小(Bucket Size)有一个爆炸点,其中所有的帧都被检测为重复的。这个爆炸点似乎是在20附近。从最大桶的大小(Max Bucket Size)那根曲线来看,20的那个资料点似乎有些奇怪。为了反驳这一段网上视讯,我也只愿意做到这些了,那么,让我们一起去看看把分辨率设定为24后取杂凑的情况吧。
结果
我把原来的杂凑函式换成了这个新的均值杂凑函式,并重新计算分析。瞧,出现了太多的匹配帧!匹配帧太多了,没办法全部显示出来,这里我显示了同一桶中的一些资料:
426272096124855132392147466162540170077185151207762252984etc… 这些都是我们找到的重复帧。将它们转换为大概的时间戳(以秒为单位,译者注:视讯连结指向YouTube网站,请科学上网):
好极了!
如果你想要检视这些重复的位置,你可以看看这段视讯剪辑。它正好发生在掌掴的中间! 虽说不一定能保证每个匹配帧都能找到,但是这比我们以前做的要详细得多,我认为这已经够好了。
我并没有追随这个YouTube使用者,所以我不知道这个视讯是一个内部笑话还是其他什么(它释出于4月1日),但这绝对是一个有趣的专案。































