
编者有言:友情提示,本文提到的快取思想不仅仅可以用在Druid上,同样可以用在ClickHouse,Impala等其他的OLAP引擎的查询优化上。接下来,我们就一起来看看知乎资料分析平台在查询优化方面的成果~
知乎作为中文知识内容平台,业务增长和产品迭代速度很快,如何满足业务快速扩张中的灵活分析需求,是知乎资料平台组要面临的一大挑战。
知乎资料平台团队基于开源的Druid打造的业务自助式的资料分析平台,经过研发迭代,目前支撑了全业务的资料分析需求,是业务资料分析的重要工具。
目前,平台主要的能力如下:
目前,业务使用平台的资料如下:
一、资料分析平台架构
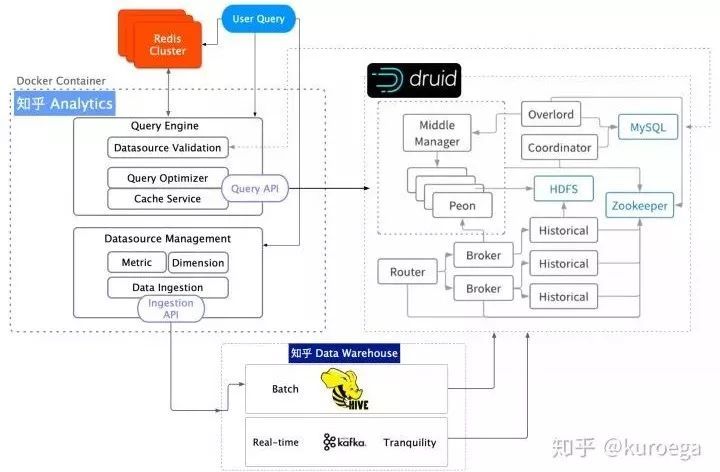
知乎实时多维分析平台架构
二、技术选型-Druid
Druid是一种能对历史和实时资料提供亚秒级别的查询的资料储存。Druid支援低延时的资料摄取,灵活的资料探索分析,高效能的资料聚合,简便的水平扩充套件。适用于资料量大,可扩充套件能力要求高的分析型查询系统。

Druid整体架构
三、Druid资料结构和架构简介
1、Druid资料结构
2、查询服务的相关元件
内部元件
外部元件
四、平台的演进
1、Druid查询量大
在Druid成为主力查询引擎之后,我们发现大查询量的场景下直接查Druid会有一些弊端,其中最大的痛点就是查询响应慢。
2、快取查询结果
为了提高整体查询速度,我们引入了Redis作为快取。

使用Redis来快取查询结果
最简单的快取设计,是将Druid的查询体(Request
)作为key,Druid的返回体(Response)作为value。上述的快取机制的缺点是显而易见的,只能应对查询条件完全一致的重复查询。在实际应用中,查询条件往往是多变的,尤其是查询时间的跨度。
举个例子,在相同指标维度组合下使用者发起两次查询,第一次查询10月1日到10月7日的资料,Druid查出结果并快取到Redis。使用者调整时间跨度到10月2日到10月8日,发起第二次查询,这条请求的不会命中Redis,又需要Druid来查询资料。
从例子中,我们发现两次查询的时间跨度交集是10月2日到10月7日,但是这部分的快取结果并没有被复用。这种查询机制下,查询延时主要来自于Druid处理重复的请求,快取结果没有被充分利用。
3、提高快取的复用
为了提高快取复用率,我们需要增加一套新的快取机制:当查询在Redis没有直接命中时,先扫描Redis中是否已快取查询中部分时间跨度的结果提取命中的结果,未命中再查询Druid。在扫描的过程中,被扫描的物件是单位时间跨度的快取。
为了能获得到任意一个单位时间跨度内的快取,除了在Redis中快取单条查询的结果之外,需要进一步按时间粒度将总跨度等分,快取所有单位时间跨度对应的结果(如下图所示):

Druid结果按时间粒度快取
4、减少Redis IO
从上图中我们发现,对每个单位时间跨度的结果判断是否已被快取都需要对Redis进行一次读操作,当使用者查询量增大时,这种操作会对Redis丛集造成比较大的负担,偶尔会出现Redis连线超时的情况。
为了减少对Redis的IO,我们对时间跨度单独设计了一套快取机制。
基于减少读操作的想法,我们设计了通过一次读操作就可得到已经被快取的所有时间跨度,然后再一次性地将所有快取的结果读出。
优化后快取机制如下图所示:

Redis读操作优化
5、Druid查询时间跨度长
在未命中快取的情况下,设定较长的查询时间跨度(长时间跨度:2周以上),Druid经常会出现返回速度变慢,甚至阻塞其他查询请求的现象。
我们测试了长时间跨度的查询请求对丛集整体的影响,通过对Druid丛集的监控资料的分析,我们发现被长时间跨度查询命中的Broker节点会出现内存消耗过大的问题,并且随着时间跨度的增大,内存消耗跟着提高,甚至出现内存不足导致Broker节点无响应的问题。
6、一个Broker处理一个请求
在调研了Druid执行原理以后,我们发现一个查询请求只会被Router路由到一个Broker节点,经由Broker节点去Historical节点上查询目标资料在Deep Storage的储存位置,最后返回的资料也是经过Broker节点来合并返回结果。查询的时间跨度越长,对Broker的压力也越大,内存消耗越多。

单个Broker处理长时间跨度查询
7、多个Broker处理一个请求
单个Broker的效能无法满足长时间跨度的查询,为了让提高查询效能,我们尝试把一个查询N天资料的请求,拆分成N个查询,每个只查询一天,然后异步地将这些请求发出,结果这N个请求都被很快的返回了。和拆分前的查询耗时相比,拆分后的耗时大大减小。
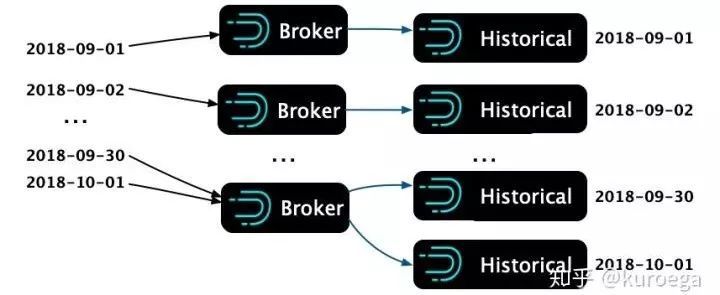
多个Broker处理长时间跨度查询
从Broker节点的监控来看,当一个长时间的查询请求被多个Broker一起处理,可以减少单个Broker内存消耗,并且加快了整体的查询速度。提速程度请参考下图的测试比对,测试用例采用平台一天的所有查询,测试方式是在不命中Redis的情况下异步地“回放”这些查询到Druid。

benchmark
根据上述Broker在查询过程中的工作原理,想达到长时间跨度查询的提速,我们需要在使用者发起查询之后把请求拆分。
拆分的机制是根据每个查询请求的查询时间粒度而定,例如上述中的一个N天跨度的天粒度请求,在查询到达Druid丛集之前,我们尝试把它拆分成N个1天跨度的天级别粒度请求。
整个查询从拆分到命中Druid的过程如下图所示(在Druid内部的工作细节请参考上文)。

按时间粒度拆分使用者查询请求
8、快取结果过期
前两步的演进完成了从高负载下查询效能低、查询时间跨度长而速度慢、Redis复用率低,到查询效能高、Redis IO稳定。
分析平台的资料来源来自于离线数仓的Hive和实时数仓的Kafka。重新摄入上游资料到Druid后,对应时间列的Segment档案会进行重建索引。
在Segment档案索引重建之后,对应的Druid查询结果也会发生改变。当这个情况发生时,使用者从Redis获取到的结果并没有及时得到更新,这时就会出现资料不一致的情况。因此一套平台使用者无感的快取自动失效机制就显得尤为重要。
9、快取自动失效
在Druid查询链路下,资料来源的最近成功摄入的时间可以被抽象为它的最新版本号,利用这一思想,我们可以给每个资料来源都打上资料版本的标签,在资料更新后,给更新的资料来源替换新的标签。这样一来,每次校验Druid查询结果是否过期时就有了参照物件。
Druid支援MySQL储存元资料资讯(Metastore Storage),元资料中的时间戳就恰好可以作为资料版本。在使用者查询请求发起后,先后取出Redis快取结果中携带的时间戳和MySQL元资料版本,然后比较两个时间。
在添加了资料版本校验后,一个请求的整个生命周期如下图所示:

快取自动失效机制
五、总结
本文重点介绍了知乎资料分析平台对Druid的查询优化。
通过自研的一整套快取机制和查询改造,该平台目前在较长的时间内,满足了业务固化的指标需求和灵活的分析需求,减少了资料开发者的开发成本。
资料分析平台在上线后,提供了非常灵活的能力。在实践中,我们发现过度的自由未必是使用者想要的。适当的流程约束,有助于降低使用者的学习成本,以及大幅度改善业务在该平台上的查询体验。早期我们对资料的摄入并没有做过多的约束,在整个资料稳定性提升过程中,通过和数仓团队的大力配合,我们对摄入的资料来源做了优化,包括限制高基数维度等治理的工作。
本文的快取思想不仅仅可以用在Druid上,同样可以用在ClickHouse,Impala等其他的OLAP引擎的查询优化上。
参考
[1]http://druid.io/docs/latest/design/


































