
Google今日(6日)在台发表过去Google Brain团队在科学探索上的研究,包含用机器学习发现新行星的成果,以及用于基因变体识别的深度学习工具DeepVariant,而DeepVariant已经于去年底在GitHub上开源。
Google台湾董事总经理简立峰表示,这两项都是跨领域合作的研究成果,台湾发展AI也可以从跨领域的方向着手,现在有许多开放的资料集,让资料的取得更加方便,再加上许多开源的AI工具,台湾可以善加利用,打造出跨领域的AI应用。
另外,有趣的是,这两项成果也都是用了开源的数据库,来当作训练资料,意味着若配合开源工具,科学研究的门槛将会大幅地降低。
台湾天文科教界元老之一的台师大科学教育中心推广服务组组长傅学海就表示,若Google将发现新行星的机器学习工具,像DeepVariant一样开源,将可以把前端天文科学研究技术带给更多人,发现行星就不再是研究学者和机构的专利,由于NASA的资料都是公开的,加上开源的工具,就连高中生也有机会可以发现系外行星,这将会是科普教育的一大推力。
用机器学习模型分析微弱讯号,找到2颗新行星
寻找新行星是天文学家一大研究方向,NASA过去4年间透过开普勒太空望远镜收集了超过20万颗恒星的亮度,每30分钟记录一次,累积超过140亿笔资料,由于天文学的时间有限,只能聚焦在3万颗恒星的明显讯号,从中找到2,500个行星讯号,但是还有超过10万颗恒星的讯号因为讯号较微弱,且有较多噪声,无法用人工的方式处理。
因此,Google锁定较微弱的讯号资料,利用1万5千个已经过天文学家标示的开普勒讯号,训练机器学习模型,该模型可以分辨较微弱的亮度讯号,搜寻开普勒数据库中的670颗恒星讯号,成功地找到2颗以往未发现的新行星,分别命名为开普勒-90i和开普勒-80g。
Google Brain研究团队资深软件工程师Chris Shallue表示,以往天文学家寻找新行星是先透过电脑算法找出潜在行星的讯号,接着用肉眼辨识讯号是否来自行星,但是人工用肉眼判断的方式不仅耗时,且无法辨认较微弱的讯号,因此,常常忽略掉隐藏的讯号。
机器学习算法则可以透过大量的数据,从数据中学习如何判断行星的讯号,Chris的团队将讯号转为亮度曲线图,输入完整的亮度曲线图和局部变化的亮度曲线图,透过卷积神经网络(Convolutional Neural network)模型来分类影像,判别该亮度曲线图是否为行星。
特别的是,开普勒-90i为第8个围绕在开普勒-90星系的行星,这是除了太阳系外,第一个被发现的8大行星系统,因此,与Google Brain团队合作的德州大学奥斯汀分校天文学家Andrew Vanderburg也将Kepler-90描述为“迷你太阳系”。而开普勒-90i是开普勒-90星系中最小的一颗行星,也是第三靠近恒星的行星,根据估计,表面温度超过摄氏400度。
不过,Chris也表示,目前的研究还有一项瓶颈就是模型的预测结果会出现假阳性(False Positive),也就是说,侦测到的恒星亮度可能来自附近的恒星,模型还无法去除掉这样的噪声,还得透过人工的方式确认模型侦测到的行星位置讯号,因此,他期望,未来在建立模型时,可以加入位置的特征,让模型能够辨识噪声。
另外,开普勒数据库中有超过20万颗恒星,目前的成果只是从670颗恒星的讯号中,找寻到2颗新行星,未来还希望可以透过模型分析更多恒星讯号,他也相信会有更多的新发现。
用于基因变体识别的深度学习工具DeepVariant
另一方面,基因定序的研究应用范围相当广泛,新一代的测序仪虽然只需要百元美金就能检测基因序列,相较于以往的设备也较快速,但是测序仪测序的结果常常有误,得到的基因序列的资讯也是片段、不完整的,Google尝试着用软件来解决这样的问题,让新一代便宜的测序仪器可以更加准确。
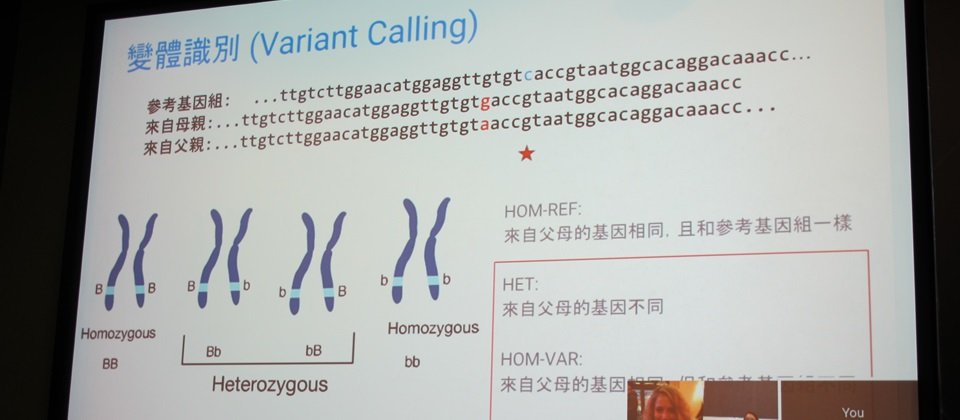
Google透过深度学习来做变体识别(Variant Calling),变体即是个体和参考基因组之间的差异,有些变体会造成疾病,目前Google主要聚焦在全序列和蛋白质序列的变体识别,也在去年底将用于基因变体识别的深度学习工具DeepVariant开源释出。
负责这项研究的Google Brain研究团队资深软件工程师张碧娟表示,变体识别对于医疗上的病因解释、药物开发、癌症标拔治疗都有帮助,但是检验变体是一项非常困难的研究,因为资料量太大,且目前透过测序仪测序的结果常常有误,再加上,目前的统计方式都需要手动设计特征和参数,不同的测序仪或是统计的方式不同,这些设计都不容易转移到不同的实验方法中。
也因此,Google Brain的团队采用机度学习,不需要手动萃取特征和调整参数,并与Verily Life Sciences合作花2年多时间开发基因变体识别工具DeepVariant,将测序仪读取到的资讯转成图像,用常见的图像分类算法Inception V3辨识图像,张碧娟表示,Google Brain用超过百万的基因序列资料,训练出DeepVariant,辨识的准确率高达99%以上。
未来,张碧娟期望将DeepVariant应用在不同的生物上,像是老鼠或是植物的变体识别,也希望来有更多临床验证的机会,实际结合临床的资讯与病史,验证DeepVariant的准确性。
相关文章
 YouTube更新违反规定政策,提升惩处透明度和一致性
YouTube更新违反规定政策,提升惩处透明度和一致性2023-12-31 14:00:52
 传苹果将把中国iCloud正式交给本地化经营 苹果手机icloud换区存储操作
传苹果将把中国iCloud正式交给本地化经营 苹果手机icloud换区存储操作2023-12-27 18:34:43
 刘德华代言什么手机?刘德华成华为Mate 60 RS非凡大师华为5G新手机代言人
刘德华代言什么手机?刘德华成华为Mate 60 RS非凡大师华为5G新手机代言人2023-09-26 21:55:08
 WebOS新系统:Palm Pre手机最新款高价登港
WebOS新系统:Palm Pre手机最新款高价登港2023-06-23 15:39:14
 帮助企业组织对抗勒索软件,资安通报机构设立防护专区,可协助事前、事中与事后因应
帮助企业组织对抗勒索软件,资安通报机构设立防护专区,可协助事前、事中与事后因应2023-06-22 09:36:10
 蔚来全系产品降价3万 取消免费换电 换一次电池180元
蔚来全系产品降价3万 取消免费换电 换一次电池180元2023-06-12 17:27:49
 电商平台三巨头开打最大规模折扣 价格战再次打响
电商平台三巨头开打最大规模折扣 价格战再次打响2023-03-05 18:58:40
 爱立信节省成本裁员四千人 爱立信全球员工总数五分之一
爱立信节省成本裁员四千人 爱立信全球员工总数五分之一2023-02-24 22:27:29
 蜜芽关停近况,八位数重金买三字顶级新域名mia.com也关闭
蜜芽关停近况,八位数重金买三字顶级新域名mia.com也关闭2023-02-23 16:18:14
 联想CEO杨元庆:联想集团需要裁员32%削减部分业务支出
联想CEO杨元庆:联想集团需要裁员32%削减部分业务支出2023-02-18 12:45:25
 蓝色光标2022营收亏损18亿 客户预算减少明显
蓝色光标2022营收亏损18亿 客户预算减少明显2023-02-18 12:40:08
 三星工厂或将80%生产转至越南 因本地劳动力成本上升
三星工厂或将80%生产转至越南 因本地劳动力成本上升2023-02-17 23:09:16
 香港八达通卡如何激活?没用失效过期余额怎么办
香港八达通卡如何激活?没用失效过期余额怎么办2023-02-17 18:34:51
 中兴通讯被曝将裁员20% 称只裁国外的
中兴通讯被曝将裁员20% 称只裁国外的2023-02-17 18:33:26
 苹果新iPhone15Pro手机终于改用USB-C(火牛)数据线??Lightning充电接口退出
苹果新iPhone15Pro手机终于改用USB-C(火牛)数据线??Lightning充电接口退出2023-02-17 16:57:22
 突发!蓝色光标曾为中国民企500强龙头 如今业绩亏损断崖下跌
突发!蓝色光标曾为中国民企500强龙头 如今业绩亏损断崖下跌2023-02-16 14:31:19
- 三星发布自家carplay车载中控系统 Car Mode for Galaxy 可以连接carplay吗?
2023-02-14 00:53:17
 Opera浏览器宣布集成ChatGPT 一键生成网页内容摘要
Opera浏览器宣布集成ChatGPT 一键生成网页内容摘要2023-02-14 00:32:08
 谷歌google计划重返进入中国市场?但结果可能令你失望
谷歌google计划重返进入中国市场?但结果可能令你失望2023-02-13 16:57:15
 Zoom紧急裁员1300人 佔员工总数15%
Zoom紧急裁员1300人 佔员工总数15%2023-02-08 14:59:11
最新资讯
- YouTube更新违反规定政策,提升惩处透明度和一致性2023-12-31 14:00:52
 美国法院裁定阿里须为Squishmallows玩具侵权案答辩2023-12-28 19:59:34
美国法院裁定阿里须为Squishmallows玩具侵权案答辩2023-12-28 19:59:34 小米汽车传员工3700人 雷军称小米汽车不可能卖9万92023-12-28 19:41:57
小米汽车传员工3700人 雷军称小米汽车不可能卖9万92023-12-28 19:41:57 吉利飙逾6% 电动车品牌极氪新车款极氪007昨上市 预售价格22.99万元2023-12-28 19:30:28
吉利飙逾6% 电动车品牌极氪新车款极氪007昨上市 预售价格22.99万元2023-12-28 19:30:28 日本丰田汽车厂11月全球产量创新高2023-12-28 19:26:02
日本丰田汽车厂11月全球产量创新高2023-12-28 19:26:02
手机
 中国11月手机出货量增34% 5G手机出货量2709.2万部2023-12-28 19:27:57
中国11月手机出货量增34% 5G手机出货量2709.2万部2023-12-28 19:27:57 荣耀发布新一代旗舰荣耀Magic5系列,新款上市价格分期0首付3999元起2023-03-06 16:12:32
荣耀发布新一代旗舰荣耀Magic5系列,新款上市价格分期0首付3999元起2023-03-06 16:12:32 美国商务部指违禁,长江存储被美国拜登制裁名单面临停工裁员2023-02-17 18:41:53
美国商务部指违禁,长江存储被美国拜登制裁名单面临停工裁员2023-02-17 18:41:53 苹果Apple iOS车载系统CarPlay支持哪些更多汽车品牌2023-02-02 17:33:27
苹果Apple iOS车载系统CarPlay支持哪些更多汽车品牌2023-02-02 17:33:27 香港去哪买三星手机回来吗? 买香港便宜售价手机市场地点和网站2023-02-02 11:03:11
香港去哪买三星手机回来吗? 买香港便宜售价手机市场地点和网站2023-02-02 11:03:11
数码
- 华为5G芯片正式亮相:预示华为将发首款5G手机2023-08-31 13:22:33
 腾讯传计划放弃虚拟现实VR硬件计划2023-02-17 23:32:30
腾讯传计划放弃虚拟现实VR硬件计划2023-02-17 23:32:30 三星手机份额大跌!三星手机中国市场份额变化国内仅剩3%2023-02-01 17:06:15
三星手机份额大跌!三星手机中国市场份额变化国内仅剩3%2023-02-01 17:06:15 三星手机份额大跌在中国没市场了!国内市场占有率仅剩1%国外比苹果销量高2023-02-01 16:59:53
三星手机份额大跌在中国没市场了!国内市场占有率仅剩1%国外比苹果销量高2023-02-01 16:59:53 vivo发布2022 vivoNEX手机极简易浏览器下载:简洁流畅无广告!2022-12-02 17:29:30
vivo发布2022 vivoNEX手机极简易浏览器下载:简洁流畅无广告!2022-12-02 17:29:30
科技
 中兴受美国制裁事件 被罚了20亿美元过程事件始末 中兴被制裁后公司现状2023-11-02 22:12:46
中兴受美国制裁事件 被罚了20亿美元过程事件始末 中兴被制裁后公司现状2023-11-02 22:12:46 B站怎么炸崩了哔哩哔哩服务器今日怎么又炸挂了?技术团队公开早先原因2023-03-06 19:05:55
B站怎么炸崩了哔哩哔哩服务器今日怎么又炸挂了?技术团队公开早先原因2023-03-06 19:05:55 苹果iPhoneXS/XR手机电池容量续航最强?答案揭晓2023-02-19 15:09:54
苹果iPhoneXS/XR手机电池容量续航最强?答案揭晓2023-02-19 15:09:54 华为荣耀两款机型起内讧:荣耀Play官方价格同价同配该如何选?2023-02-17 23:21:27
华为荣耀两款机型起内讧:荣耀Play官方价格同价同配该如何选?2023-02-17 23:21:27 google谷歌原生系统Pixel3 XL/4/5/6 pro手机价格:刘海屏设计顶配版曾卖6900元2023-02-17 18:58:09
google谷歌原生系统Pixel3 XL/4/5/6 pro手机价格:刘海屏设计顶配版曾卖6900元2023-02-17 18:58:09