
大家好,今天我们学习【机器学习速成】之 巢状:高维度资料对映到低维度空间。
巢状将高维度资料对映到低维度空间, 可以将语义上相似的不同输入对映到巢状空间里的邻近处, 以此来捕获输入的语义。
我们 马上学三点 ,
协同过滤电影推荐输入表示法深度网络中的巢状层大家可以点选下面的“ 了解更多”,或搜寻“ 马上学123 ”,线上观看PPT讲义。
协同过滤推荐
推荐系统最基本的方面是巢状, 这也是我们今天要讨论的内容。协同过滤是一项可以预测使用者兴趣的任务, 这里以电影推荐的任务为例, 假设我有一百万部电影和五十万使用者, 而且我知道每个使用者观看过的电影。
任务很简单:我要向用户推荐电影。 要解决这个问题, 我们需要使用某种方法来确定哪些电影是相似的。 我们可以通过将电影巢状到低维空间 (使得相似的电影彼此邻近)来实现这个目标。
如果您观看了3部电影, 我就可以推荐和这3部电影相邻的给你。
按相似度整理电影(一维)
首先,我们先试着沿着一维巢状这些电影。 为了更直观地了解巢状过程, 请准备一张纸,试着在一维数轴上排列以下电影, 让越相关的电影靠得越近: 按相似度整理电影(一维)
按相似度整理电影(一维)
比如说,我可能会在左侧放入动画片, 在右侧放入更加适合成人的电影, 这种巢状有助于捕获电影的适宜观赏年龄段。
我可以向儿童推荐动画片,这个效果不错, 但有些动画片不适合儿童观看, 还有一些电影很少有人看,我们应该少推荐。 但只有一个维度,我很难做出其它角度的判断。
按相似度整理影片(二维)
如果我们再新增一个维度, 有两个维度的话会怎样呢? 按相似度整理影片(二维)
按相似度整理影片(二维)
X轴的左侧是比较适合儿童的电影, 右侧则是比较适合成人的电影, Y轴的顶部是比较卖座的大片, 底部则是偏艺术类的电影。 当然,这只是电影诸多重要特征中的两个。
利用这种二维巢状,我们可以定义电影之间的距离, 从而使在适宜儿童或成人的程度上相近的电影 以及属于大片或艺术电影的程度上相近的电影位于相近的位置, 您可以看到位置相邻的电影比较类似, 而这正是我们想要实现的目标。
我们所做的是将这些电影对映到一个巢状空间, 其中的每个字词都由一组二维座标来表示。 例如,在这个空间中,《怪物史莱克》对映到了 (-1.0, 0.95), 而《蓝》则对映到了 (0.65, -0.2)。 此处的每部电影都可以仅由两个值组成的集表示, 而且我们现在可通过这些点之间的距离 了解电影之间的相似性。
d 维巢状
尽管我只绘制两个维度, 但实际上,您需要在D维空间中建模,二维不足以捕获一切内容。通常情况下,在学习 d 维巢状时, 每部影片都变成一个 d 维点,由d个数字表示, 其中维度 d 中的值表示这部影片符合相应方面的程度。
实际上可以通过资料学习这些巢状, 我们可以使用深度神经网络进行巢状, 巢状层只是隐藏层,每个维度一个单元。
输入表示法
现在,我们看看如何将这种方法运用到神经网络中。 输入表示法
输入表示法
如图所示, 我用一行表示一个使用者,一列表示一部电影, 并在这个简单的示例中打一个勾表示使用者看过这部电影。 每个样本其实只是此矩阵中的一行, 我们来重点关注一下最后一行。
如果有五十万部电影, 我可不想列出您没有看过的所有电影, 所以,只是记下您看过的电影会更高效。
为实现这一目标,我们将使用以下输入表示法, 为此,我们需要分两个阶段进行:
第一个阶段是预处理阶段: 在这个阶段,我们将构建名为字典的数据库, 字典就是从各个特征到相应整数的对映。 本例中,电影按照所在列的顺序对映相应整数, 我会将第0列命名为第0个电影, 将第1列命名为第1个电影, 以此类推,这是我们在预处理阶段执行的一项一次性操作。现在,我可以高效地将那个最后一行样本 仅表示为使用者看过的3个电影,而不用去管所有其他电影。 实际上这只是3个整数: 1、3、999999, 因为这些数字表示使用者看过的3个电影的索引。
深度网络中的巢状层
现在有了输入表示法, 我们就可以了解如何将其运用到整个网络, 深度网络中的巢状层
深度网络中的巢状层
电影推荐问题其实很有趣,我的训练资料在哪里? 我只知道每个使用者都看过一些电影, 但我怎样才能知道哪些电影适合推荐?我要使用什么作为标签?
在这种情况下,我们可以使用一个简单的技巧: 假设使用者看过10部电影, 我们会随机挑选3部电影,把这些电影放在一边, 这些就是标签, 这些是我要推荐的电影, 它们都是不错的推荐,因为您已经看过这些电影了, 至于另外7部电影,我会将其用作训练资料, 获取稀疏表示法,并会将其引入到巢状层。
我们还可以根据具体需求新增任何其他特征, 可以是型别,也可以是导演, 还可以是任何其他有关电影或使用者的特征, 然后,我们可以将这些特征新增到额外的隐藏层, 这样我们就有了一个对数层。 这个对数层很大,如果我有五十万部电影,则会有五十万个节点。 这会导致一些问题,但不在我们本次讨论的范围内。
但通过这五十万部电影, 我们可以获得我们认为您会喜欢的电影的概率分布, 然后根据选出的你可能会喜欢电影对softmax损失进行优化。 这样一来, 我们就可以在反向传播和标准训练中学习如何巢状电影。
深度网络与几何检视的对应关系
现在,我们一起回顾一下, 我们在深度神经网络中学习的内容 如何与我刚开始提供的几何检视联络在一起。 深度网络与几何检视的对应关系
深度网络与几何检视的对应关系
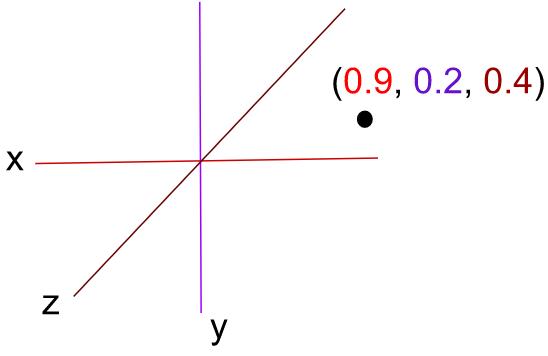
我们来看看深度网络, 底部的每个节点都可表示为五十万部电影的其中一部, 我已挑选其中一部并使其显示为黑色。 在此示例中, 有3个隐藏单元,所以我打算使用三维巢状方式。
这样,该黑色节点的边缘会连线到上述每个单元; 我使用红色显示第1个单元,使用洋红色显示第2个单元,使用棕色显示第3个单元。 完成神经网络训练后,这些边缘会表示权重, 每个边缘对应一个与其相关联的实值, 这就是我的巢状方式。
 深度网络与几何检视的对应关系
深度网络与几何检视的对应关系
红色表示X值,洋红色表示Y值,棕色表示Z值。 所以,这部电影就会巢状到三维空间内(0.9,0.2,0.4)。
选择巢状维度个数
与任何深度神经网络一样, 此网络也有超引数, 巢状层中的其中一个超引数指的是 您想在该层中新增的巢状维度数量,隐藏单元数量。维度越多越好,因为这样就能够梳理更多的差别, 从而了解相互之间更细致的关系。
但多重维度也存在缺陷,那就是当我增加维度的数量时, 还有可能出现过拟合, 从而导致训练程序变慢且需要更多资料。
因此,最好的经验法则是维度数量约为潜在值的数量(例如词汇量)的四次方根。
但这只是经验之谈,对于所有超引数, 您真正需要做的是使用验证资料, 根据您自己的具体问题多多尝试, 然后确定哪项引数能获得最佳效果。
总结:
协同过滤是一项可以预测使用者兴趣的任务,构建一个字典,其中包含各个特征到相应整数的对映深度网络中的巢状层,每个隐藏单元都对应一个维度,应使用验证资料进行微调;这里讲了三点,关键词有哪几个?提问!降维技术还有哪些?
欢迎回复评论


































