
在当今互联网行业,大多数人互联网从业者对"单元化"、"异地多活"这些词汇已经耳熟能详。而资料同步是异地多活的基础,所有具备资料储存能力的元件如:数据库、快取、MQ等,资料都可以进行同步,形成一个庞大而复杂的资料同步拓扑。
本文将先从概念上介绍单元化、异地多活、就近访问等基本概念。之后,将以数据库为例,讲解在资料同步的情况下,如何解决资料回环、资料冲突、资料重复等典型问题。
一、什么是单元化
如果仅仅从"单元化”这个词汇的角度来说,我们可以理解为将资料划分到多个单元进行储存。"单元"是一个抽象的概念,通常与资料中心(IDC)概念相关,一个单元可以包含多个IDC,也可以只包含一个IDC。本文假设一个单元只对应一个IDC。
考虑一开始只有一个IDC的情况,所有使用者的资料都会写入同一份底层储存中,如下图所示:

1、问题
这种架构是大多资料中小型互联网公司采用的方案,存在以下几个问题:
1)不同地区的使用者体验不同
一个IDC必然只能部署在一个地区,例如部署在北京,那么北京的使用者访问将会得到快速响应;但是对于上海的使用者,访问延迟一般就会大一点,上海到北京的一个RTT可能有20ms左右。
2)容灾问题
这里容灾不是单台机器故障,而是指机房断电、自然灾害或者光纤被挖断等重大灾害。一旦出现这种问题,将无法正常为使用者提供访问,甚至出现资料丢失的情况。
这并不是不可能,例如:2015年,支付宝杭州某资料中心的光缆就被挖断过;2018年9月,云栖大会上,蚂蚁金服当场把杭州两个资料中心的网线剪断。
为了解决这些问题,我们可以将服务部署到多个不同的IDC中,不同IDC之间的资料互相进行同步。如下图:

2、解决
通过这种方式,我们可以解决单机房遇到的问题:
1)使用者体验。不同的使用者可以选择离自己最近的机房进行访问
2)容灾问题。当一个机房挂了之后,我们可以将这个机房使用者的流量排程到另外一个正常的机房,由于不同机房之间的资料是实时同步的,使用者流量排程过去后,也可以正常访问资料 (故障发生那一刻的少部分资料可能会丢失)。
需要注意的是,关于容灾,存在一个容灾级别的划分,例如:单机故障,机架(rack)故障,机房故障,城市级故障等。
我们这里只讨论机房故障和城市故障:
上面的案例中,我们使用了2个IDC,但是2个IDC并不能具备机房容灾能力。
至少需要3个IDC,例如,一些基于多数派协议的一致性元件,如Zookeeper,Redis、etcd、consul等,需要得到大部分节点的同意。
例如我们部署了3个节点,在只有2个机房的情况下, 必然是一个机房部署2个节点,一个机房部署一个节点。
当部署了2个节点的机房挂了之后,只剩下一个节点,无法形成多数派。
在3机房的情况下,每个机房部署一个节点,任意一个机房挂了,还剩2个节点,还是可以形成多数派。这也就是我们常说的"两地三中心”。
在发生重大自然灾害的情况下,可能整个城市的机房都无法访问。一些元件,例如蚂蚁的ocean base,为了达到城市级容灾的能力,使用的是"三地五中心"的方案。
这种情况下,3个城市分别拥有2、2、1个机房。当整个城市发生灾难时,其他两个城市依然至少可以保证有3个机房依然是存活的,同样可以形成多数派。
3、小结
如果仅仅是考虑不同地区的使用者资料就近写入距离最近的IDC,这是纯粹意义上的”单元化”。
不同单元的之间资料实时进行同步,相互备份对方的资料,才能做到真正意义上"异地多活”。
实现单元化,技术层面我们要解决的事情很多,例如:流量排程,即如何让使用者就近访问附近的IDC;资料互通,如何实现不同机房之间资料的相互同步。
流量排程不在本文的讨论范畴内,资料同步是本文讲解的重点。
二、如何实现资料同步
需要同步的元件有很多,例如数据库、快取等,这里以多个MySQL丛集之间的资料同步为例进行讲解,实际上快取的同步思路也是类似。
1、基础知识
为了了解如何对不同MySQL的资料相互进行同步,我们先了解一下MySQL主从复制的基本架构,如下图所示:

通常一个MySQL丛集有一主多从构成。使用者的资料都是写入主库Master,Master将资料写入到本地二进位制日志binary log中。
从库Slave启动一个IO执行绪(I/O Thread)从主从同步binlog,写入到本地的relay log中,同时slave还会启动一个SQL Thread,读取本地的relay log,写入到本地,从而实现资料同步。
基于这个背景知识,我们就可以考虑自己编写一个元件,其作用类似与MySQL slave,也是去主库上拉取binlog,只不过binlog不是储存到本地,而是将binlog转换成sql插入到目标MySQL丛集中,实现资料的同步。
这并非是一件不可能完成的事,MySQL官网上已经提供好所有你自己编写一个MySQL slave 同步binlog所需的相关背景知识,访问这个连结:https://dev.mysql.com/doc/internals/en/client-server-protocol.html,你将可以看到MySQL客户端与服务端的通讯协议。
下图红色框中展示了MySQL主从复制的相关协议:

当然,笔者的目的并不是希望读者真正的按照这里的介绍尝试编写一个MySQL的slave,只是想告诉读者,模拟MySQL slave拉取binlog并非是一件很神奇的事,只要你的网络基础知识够扎实,完全可以做到。
然而,这是一个庞大而复杂的工作。以一人之力,要完成这个工作,需要占用你大量的时间。
好在,现在已经有很多开源的元件,已经实现了按照这个协议可以模拟成一个MySQL的slave,拉取binlog。例如:
你可以利用这些元件来完成资料同步,而不必重复造轮子。假设你采用了上面某个开源元件进行同步,需要明白的是这个元件都要完成最基本的2件事:
为什么划分成两块独立的功能?因为binlog订阅解析的实际应用场景并不仅仅是资料同步,如下图:

如图所示,我们可以通过binlog来做很多事,如:
因此,通常我们把binlog syncer单独作为一个模组,其只负责解析从数据库中拉取并解析binlog,并在内存中快取(或持久化储存)。
另外,binlog syncer另外提一个sdk,业务方通过这个sdk从binlog syncer中获取解析后的binlog资讯,然后完成自己的特定业务逻辑处理。
显然,在资料同步的场景下,我们可以基于这个sdk,编写一个元件专门用于将binlog转换为sql,插入目标库,实现资料同步,如下图所示:

北京使用者的资料不断写入离自己最近的机房的DB,通过binlog syncer订阅这个库binlog,然后下游的binlog writer将binlog转换成SQL,插入到目标库。
上海使用者类似,只不过方向相反,不再赘述。通过这种方式,我们可以实时的将两个库的资料同步到对端。当然事情并非这么简单,我们有一些重要的事情需要考虑。
2、如何获取全量+增量资料?
通常,MySQL不会储存所有的历史binlog。原因在于,对于一条记录,可能我们会更新多次,这依然是一条记录,但是针对每一次更新操作,都会产生一条binlog记录,这样就会存在大量的binlog,很快会将磁盘占满。
因此DBA通常会通过一些配置项,来定时清理binlog,只保留最近一段时间内的binlog。
例如,官方版的MySQL提供了expire_logs_days配置项,可以设定储存binlog的天数,笔者这里设定为0,表示预设不清空,如果将这个值设定大于0,则只会储存指定的天数。
另外一些MySQL的分支,如percona server,还可以指定保留binlog档案的个数。我们可以通过show binary logs来检视当前MySQL存在多少个binlog档案,如下图:

通常,如果binlog如果从来没被清理过,那么binlog档名字字尾通常是000001,如果不是这个值,则说明可能已经被清理过。当然,这也不是绝对,例如执行"reset master”命令,可以将所有的binlog清空,然后从000001重新开始计数。
Whatever! 我们知道了,binlog可能不会一直保留,所以直接同步binlog,可能只能获取到部分资料。
因此,通常的策略是,由DBA先dump一份源库的完整资料快照,增量部分,再通过binlog订阅解析进行同步。
3、如何解决重复插入
考虑以下情况下,源库中的一条记录没有唯一索引。对于这个记录的binlog,通过sql writer将binlog转换成sql插入目标库时,丢掷了异常,此时我们并不知道是否插入成功了,则需要进行重试。
如果之前已经是插入目标库成功,只是目标库响应时网络超时(socket timeout)了,导致的异常,这个时候重试插入,就会存在多条记录,造成资料不一致。
因此,通常在资料同步时,通常会限制记录必须有要有主键或者唯一索引。
4、如何解决唯一索引冲突
由于两边的库都存在资料插入,如果都使用了同一个唯一索引,那么在同步到对端时,将会产生唯一索引冲突。
对于这种情况,通常建议是使用一个全域性唯一的分散式ID生成器来生成唯一索引,保证不会产生冲突。
另外,如果真的产生冲突了,同步元件应该将冲突的记录储存下来,以便之后的问题排查。
5、对于DDL语句如何处理
如果数据库表中已经有大量资料,例如千万级别、或者上亿,这个时候对于这个表的DDL变更,将会变得非常慢,可能会需要几分钟甚至更长时间,而DDL操作是会锁表的,这必然会对业务造成极大的影响。
因此,同步元件通常会对DDL语句进行过滤,不进行同步。DBA在不同的数据库丛集上,通过一些线上DDL工具(如gh-ost),进行表结构变更。
6、如何解决资料回环问题
资料回环问题,是资料同步过程中,最重要的问题。我们针对INSERT、UPDATE、DELETE三个操作来分别进行说明:
1)INSERT操作
假设在A库插入资料,A库产生binlog,之后同步到B库,B库同样也会产生binlog。由于是双向同步,这条记录,又会被重新同步回A库。由于A库应存在这条记录了,产生冲突。
2)UPDATE操作
先考虑针对A库某条记录R只有一次更新的情况,将R更新成R1,之后R1这个binlog会被同步到B库,B库又将R1同步会A库。对于这种情况下,A库将不会产生binlog。
因为A库记录当前是R1,B库同步回来的还是R1,意味着值没有变。
在一个更新操作并没有改变某条记录值的情况下,MySQL是不会产生binlog,相当于同步终止。
下图演示了当更新的值没有变时,MySQL实际上不会做任何操作:

上图资料中原本有一条记录(1,"tianshouzhi”),之后执行一个update语句,将id=1的记录的name值再次更新为“tianshouzhi”,意味着值并没有变更。
这个时候,我们看到MySQL返回的影响的记录函式为0,也就是说并不会产生真是的更新操作。然而这并不意味UPDATE 操作没有问题,事实上,其比INSERT更加危险。
考虑A库的记录R被连续更新了2次,第一次更新成R1,第二次被更新成R2;这两条记录变更资讯都被同步到B库,B也产生了R1和R2。
由于B的资料也在往A同步,B的R1会被先同步到A,而A现在的值是R2,由于值不一样,将会被更新成R1,并产生新的binlog;此时B的R2再同步会A,发现A的值是R1,又更新成R2,也产生binlog。由于B同步回A的操作,让A又产生了新的binlog,A又要同步到B,如此反复,陷入无限循环中。
3)DELETE操作
同样存在先后顺序问题。例如先插入一条记录,再删除。B在A删除后,又将插入的资料同步回A,接着再将A的删除操作也同步回A,每次都会产生binlog,陷入无限回环。
关于资料回环问题,笔者有着血的教训,曾经因为笔者的误操作,将一个库的资料同步到了自身,最终也导致无限循环,原因分析与上述提到的UPDATE、DELETE操作类似,读者可自行思考。
针对上述资料同步到过程中可能会存在的资料回环问题,最终会导致资料无限循环,因此我们必须要解决这个问题。由于存在多种解决方案,我们将在稍后统一进行讲解。
7、资料同步架构设计
现在,让我们先把思路先从解决资料同步的具体细节问题转回来,从更高的层面讲解资料同步的架构应该如何设计。稍后的内容中,我们将讲解各种避免资料回环的各种解决方案。
前面的架构中,只涉及到2个DB的资料同步,如果有多个DB资料需要相互同步的情况下,架构将会变得非常复杂。例如:
可以看到,GTID会在每个事务(Query->...->Xid)之前,设定这个事务下一次要使用到的GTID。
从源库订阅binlog的时候,由于这个GTID也可以被解析到,之后在往目标库同步资料的时候,我们可以显示的的指定这个GTID,不让目标自动生成。
也就是说,往目标库,同步资料时,变成了2条SQL:
SET GTID_NEXT= '09530823-4f7d-11e9-b569-00163e121964:1’
insert into users(name) values("tianbowen")
由于我们显示指定了GTID,目标库就会使用这个GTID当做当前事务ID,不会自动生成。同样,这个操作也会在目标库产生binlog资讯,需要同步回源库。
再往源库同步时,我们按照相同的方式,先设定GTID,在执行解析binlog后得到的SQL,还是上面的内容
SET GTID_NEXT= '09530823-4f7d-11e9-b569-00163e121964:1'
insert into users(name) values("tianbowen")
由于这个GTID在源库中已经存在了,插入记录将会被忽略,演示如下:
mysql> SET GTID_NEXT= '09530823-4f7d-11e9-b569-00163e121964:1';
Query OK, 0 rows affected (0.00 sec)
mysql> insert into users(name) values("tianbowen");
Query OK, 0 rows affected (0.01 sec) #注意这里,影响的记录行数为0
注意这里,对于一条insert语句,其影响的记录函式居然为0,也就会插入并没有产生记录,也就不会产生binlog,避免了循环问题。
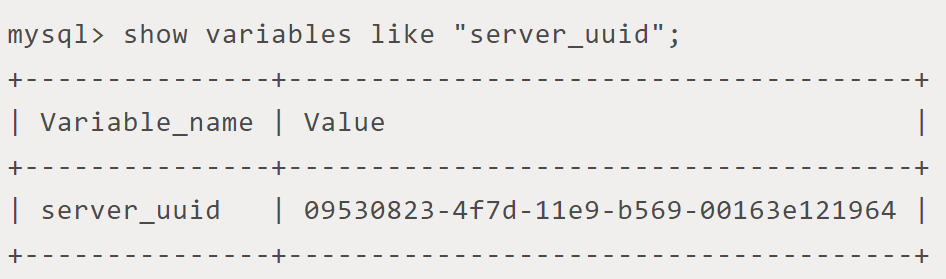
如何做到的呢?MySQL会记录自己执行过的所有GTID,当判断一个GTID已经执行过,就会忽略。通过如下sql检视:

上述value部分,冒号":"前面的是server_uuid,冒号后面的1-5,是一个范围,表示已经执行过1,2,3,4,5这个几个transaction_id。
这里就能解释了,在GTID模式的情况下,为什么前面的插入语句影响的记录函式为0了。
显然,GTID除了可以帮助我们避免资料回环问题,还可以帮助我们解决资料重复插入的问题,对于一条没有主键或者唯一索引的记录,即使重复插入也没有,只要GTID已经执行过,之后的重复插入都会忽略。
当然,我们还可以做得更加细致,不需要每次都往目标库设定GTID_NEXT,这毕竟是一次网络通讯。
sql writer在往目标库插入资料之前,先判断目标库的server_uuid是不是和当前binlog事务资讯携带的server_uuid相同,如果相同,则可以直接丢弃。
检视目标库的gtid,可以通过以下sql执行:
GTID应该算是一个终极的资料回环解决方案,MySQL原生自带,比新增一个辅助表的方式更轻量,开销也更低。
需要注意的是,这倒并不是一定说GTID的方案就比辅助表好,因为辅助表可以新增机房等额外资讯。
在一些场景下,如果下游需要知道这条记录原始产生的机房,还是需要使用辅助表。
四、开源元件介绍canal/otter
前面深入讲解了单元化场景下资料同步的基础知识。读者可能比较感兴趣的是,哪些开源元件在这些方面做的比较好。笔者建议的首选,是canal/otter组合。
canal的作用就是类似于前面所述的binlog syncer,拉取解析binlog。otter是canal的客户端,专门用于进行资料同步,类似于前文所讲解的sql writer。并且,canal的最新版本已经实现了GTID。
另外,笔者也在自己的部落格上写了一个canal系列的源代码分析教程,完成了大部分。相信对于需要深入阅读canal源代码的使用者有一定的借鉴意义。点选阅读原文,即可查 看。
作者:田守枝
来源:田守枝的技术部落格订阅号(ID:tianshouzhi_blog)
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:[email protected]


































