
大资料文摘出品
编译:李雷、宁静
NumPy是Python中用于资料分析、机器学习、科学计算的重要软件包。它极大地简化了向量和矩阵的操作及处理。python的不少资料处理软件包依赖于NumPy作为其基础架构的核心部分(例如scikit-learn、SciPy、pandas和tensorflow)。除了资料切片和资料切块的功能之外,掌握numpy也使得开发者在使用各资料处理库除错和处理复杂用例时更具优势。

在本文中,将介绍NumPy的主要用法,以及它如何呈现不同型别的资料(表格,影象,文字等),这些经Numpy处理后的资料将成为机器学习模型的输入。
import numpy as np
NumPy中的阵列操作
建立阵列
我们可以通过将python列表传入np.array()来建立一个NumPy阵列(也就是强大的ndarray)。在下面的例子里,创建出的阵列如右边所示,通常情况下,我们希望NumPy为我们初始化阵列的值,为此NumPy提供了诸如ones(),zeros()和random.random()之类的方法。我们只需传入元素个数即可:
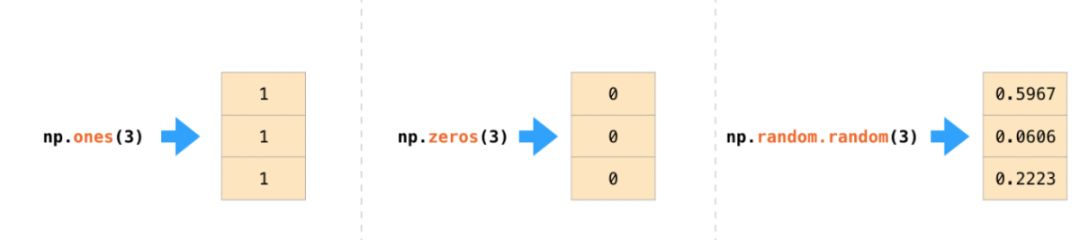
一旦我们建立了阵列,我们就可以用其做点有趣的应用了,文摘菌将在下文展开说明。
阵列的算术运算
让我们建立两个NumPy阵列,分别称作data和ones:

若要计算两个阵列的加法,只需简单地敲入data + ones,就可以实现对应位置上的资料相加的操作(即每行资料进行相加),这种操作比循环读取阵列的方法程式码实现更加简洁。
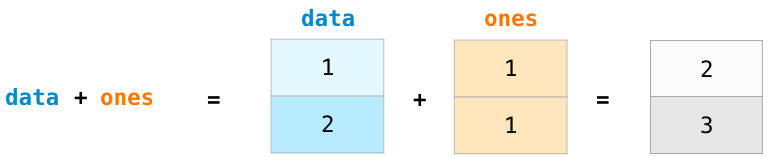
当然,在此基础上举一反三,也可以实现减法、乘法和除法等操作:

许多情况下,我们希望进行阵列和单个数值的操作(也称作向量和标量之间的操作)。比如:如果阵列表示的是以英里为单位的距离,我们的目标是将其转换为公里数。可以简单的写作data * 1.6:

NumPy通过阵列广播(broadcasting)知道这种操作需要和阵列的每个元素相乘。
阵列的切片操作
我们可以像python列表操作那样对NumPy阵列进行索引和切片,如下图所示:

聚合函式
NumPy为我们带来的便利还有聚合函式,聚合函式可以将资料进行压缩,统计阵列中的一些特征值:

除了min,max和sum等函式,还有mean(均值),prod(资料乘法)计算所有元素的乘积,std(标准差),等等。上面的所有例子都在一个维度上处理向量。除此之外,NumPy之美的一个关键之处是它能够将之前所看到的所有函式应用到任意维度上。
NumPy中的矩阵操作
建立矩阵
我们可以通过将二维列表传给Numpy来建立矩阵。
np.array([[1,2],[3,4]])

除此外,也可以使用上文提到的ones()、zeros()和random.random()来建立矩阵,只需传入一个元组来描述矩阵的维度:

矩阵的算术运算
对于大小相同的两个矩阵,我们可以使用算术运算子(+-*/)将其相加或者相乘。NumPy对这类运算采用对应位置(position-wise)操作处理:
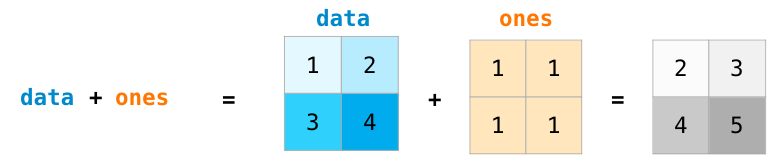
对于不同大小的矩阵,只有两个矩阵的维度同为1时(例如矩阵只有一列或一行),我们才能进行这些算术运算,在这种情况下,NumPy使用广播规则(broadcast)进行操作处理:

与算术运算有很大区别是使用点积的矩阵乘法。NumPy提供了dot()方法,可用于矩阵之间进行点积运算:

上图的底部添加了矩阵尺寸,以强调运算的两个矩阵在列和行必须相等。可以将此操作图解为如下所示:

矩阵的切片和聚合
索引和切片功能在操作矩阵时变得更加有用。可以在不同维度上使用索引操作来对资料进行切片。
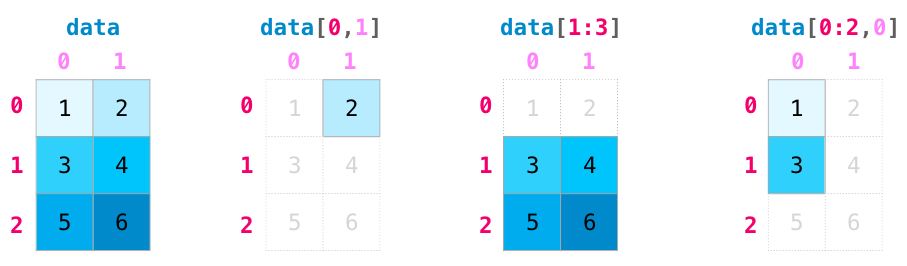
我们可以像聚合向量一样聚合矩阵:

不仅可以聚合矩阵中的所有值,还可以使用axis引数指定行和列的聚合:

矩阵的转置和重构
处理矩阵时经常需要对矩阵进行转置操作,常见的情况如计算两个矩阵的点积。NumPy阵列的属性T可用于获取矩阵的转置。
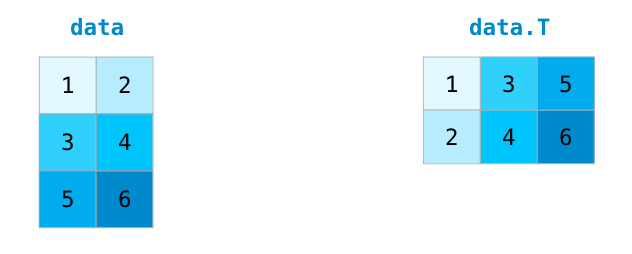
在较为复杂的用例中,你可能会发现自己需要改变某个矩阵的维度。这在机器学习应用中很常见,例如模型的输入矩阵形状与资料集不同,可以使用NumPy的reshape()方法。只需将矩阵所需的新维度传入即可。也可以传入-1,NumPy可以根据你的矩阵推断出正确的维度:
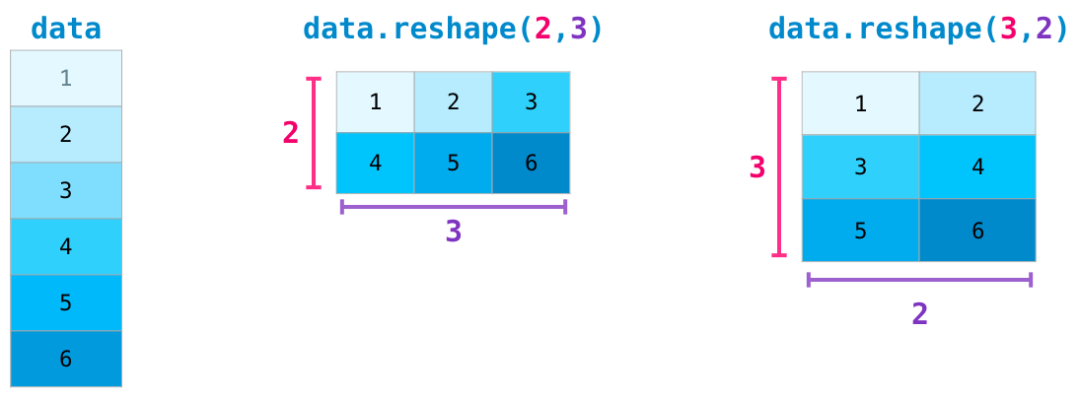
上文中的所有功能都适用于多维资料,其中心资料结构称为ndarray(N维阵列)。

很多时候,改变维度只需在NumPy函式的引数中新增一个逗号,如下图所示:

NumPy中的公式应用示例
NumPy的关键用例是实现适用于矩阵和向量的数学公式。这也Python中常用NumPy的原因。例如,均方误差是监督机器学习模型处理回归问题的核心:
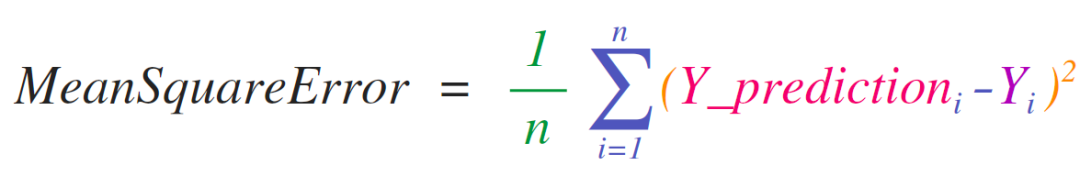
在NumPy中可以很容易地实现均方误差:

这样做的好处是,numpy无需考虑predictions与labels具体包含的值。文摘菌将通过一个示例来逐步执行上面程式码行中的四个操作:

预测(predictions)和标签(labels)向量都包含三个值。这意味着n的值为3。在我们执行减法后,我们最终得到如下值:

然后我们可以计算向量中各值的平方:

现在我们对这些值求和:

最终得到该预测的误差值和模型质量分数。
用NumPy表示日常资料
日常接触到的资料型别,如电子表格,影象,音讯......等,如何表示呢?Numpy可以解决这个问题。
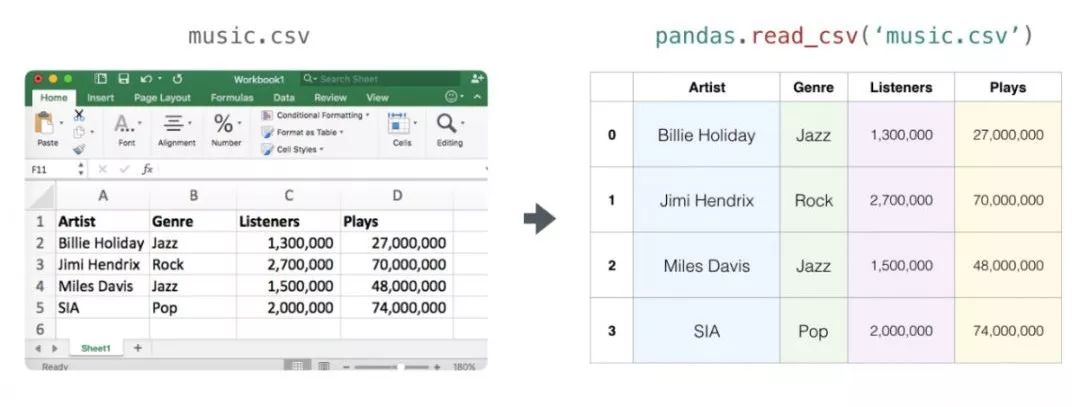
表和电子表格
电子表格或资料表都是二维矩阵。电子表格中的每个工作表都可以是自己的变数。python中类似的结构是pandas资料帧(dataframe),它实际上使用NumPy来构建的。
音讯和时间序列
音讯档案是一维样本阵列。每个样本都是代表一小段音讯讯号的数字。CD质量的音讯每秒可能有44,100个取样样本,每个样本是一个-65535到65536之间的整数。这意味着如果你有一个10秒的CD质量的WAVE档案,你可以将它载入到长度为10 * 44,100 = 441,000个样本的NumPy阵列中。想要提取音讯的第一秒?只需将档案载入到我们称之为audio的NumPy阵列中,然后撷取audio[:44100]。
以下是一段音讯档案:
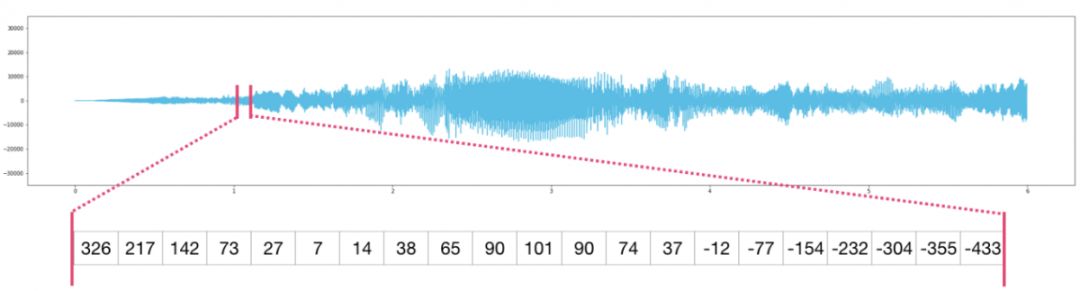
时间序列资料也是如此(例如,股票价格随时间变化的序列)。
影象
影象是大小为(高度×宽度)的画素矩阵。如果影象是黑白影象(也称为灰度影象),则每个画素可以由单个数字表示(通常在0(黑色)和255(白色)之间)。如果对影象做处理,裁剪影象的左上角10 x 10大小的一块画素区域,用NumPy中的image[:10,:10]就可以实现。
这是一个影象档案的片段:

如果影象是彩色的,则每个画素由三个数字表示 :红色,绿色和蓝色。在这种情况下,我们需要第三维(因为每个单元格只能包含一个数字)。因此彩色影象由尺寸为(高x宽x 3)的ndarray表示。

语言
如果我们处理文字,情况就会有所不同。用数字表示文字需要两个步骤,构建词汇表(模型知道的所有唯一单词的清单)和嵌入(embedding)。让我们看看用数字表示这个(翻译的)古语引用的步骤:“Have the bards who preceded me left any theme unsung?”
模型需要先训练大量文字才能用数字表示这位战场诗人的诗句。我们可以让模型处理一个小资料集,并使用这个资料集来构建一个词汇表(71,290个单词):

然后可以将句子划分成一系列“词”token(基于通用规则的单词或单词部分):

然后我们用词汇表中的id替换每个单词:

这些ID仍然不能为模型提供有价值的资讯。因此,在将一系列单词送入模型之前,需要使用嵌入(embedding)来替换token/单词(在本例子中使用50维度的word2vec嵌入):

你可以看到此NumPy阵列的维度为[embedding_dimension x sequence_length]。
在实践中,这些数值不一定是这样的,但我以这种方式呈现它是为了视觉上的一致。出于效能原因,深度学习模型倾向于保留批资料大小的第一维(因为如果并行训练多个示例,则可以更快地训练模型)。很明显,这里非常适合使用reshape()。例如,像BERT这样的模型会期望其输入矩阵的形状为:[batch_size,sequence_length,embedding_size]。
这是一个数字合集,模型可以处理并执行各种有用的操作。我留空了许多行,可以用其他示例填充以供模型训练(或预测)。
(事实证明,在我们的例子中,那位诗人的话语比其他诗人的诗句更加名垂千古。尽管生而为奴,诗人安塔拉(Antarah)的英勇和语言能力使他获得了自由和神话般的地位,他的诗是伊斯兰教以前的阿拉伯半岛《悬诗》的七首诗之一)。
相关报道:
https://jalammar.github.io/visual-numpy/


































