
全文共4143字,预计学习时长15分钟
 图片来源:pexels.com
图片来源:pexels.com
我们正处于深度学习的变革浪潮中。在构建计算机视觉与应用自然语言处理(NLP)方面,深度神经网络学习模型取得了前所未有的成就。
现在可谓是应用深度学习技术的大好时机,在目标检测、语言翻译和情感分析等任务中,人们不断引入最前沿的基准。
但这股浪潮并未席卷资讯保安领域:深度学习在资讯保安领域(InfoSec)的应用仍处于起步阶段;而在其他领域,深度学习的应用瞩目耀眼,吸引了大量研究人员与投资者。资讯保安是最关键的领域之一,值得每位资料科学家的关注。

好讯息是,与基于规则和基于经典机器学习的方案相比,深度学习已经在恶意软件检测和网络入侵检测两个领域取得了重要进展。

目录
· 什么是PowerShell?
· 了解当前问题
· 收集和生成PowerShell指令码资料集
· 资料实验

什么是PowerShell?

PowerShell是一个由鲁棒命令列壳层程式组成的任务自动化和配置管理框架。2016年8月,微软开放PowerShell源代码,使其得以跨平台相容。
PowerShell已被广泛运用于各种网络攻击中。赛门铁克(Symantec)的一项研究显示,在赛门铁克Blue Coat沙盒分析的所有指令码中,近95.4%是恶意的。
黑客组织Odinaff甚至利用PowerShell的恶意指令码攻击银行及其他金融机构的网络。在网上,人们可以找到很多工具(例如PowerShellEmpire [6]和PowerSploit[7])用于监听、许可权提升、内网漫游、永续性控制、逃避防御,最后达到资料窃取的目的。
黑客通过使用两种技术来逃避检测:
· 首先,通过执行无档案恶意软件,将从网上下载的恶意指令码直接载入到内存中,从而避免了反病毒(AV)档案扫描。
· 然后使用混淆技术,令程式码难以解码。因此,任何反病毒扫描和分析师都难以判断指令码的真实意图。
使用混淆技术掩盖PowerShell指令码恶意意图的做法也靡然成风。由于其语法的高度灵活性,分析指令码意图也变得更加困难。在Acalvio的高互动蜜罐(一种诱饵系统)中,我们可以监控攻击者在蜜罐中执行的PowerShell日志、命令和指令码。研究人员收集这些日志并进行实时分析,检测指令码是否经过混淆处理。

了解当前问题
在Windows操作系统中,MicrosoftPowerShell成为开展网络攻击的理想工具。主要原因有两点:
· PowerShell预设安装在Windows系统中
· 黑客最擅长利用可进行混淆处理的现成工具,尽可能避开反病毒(AV)软件扫描。
微软推出了PowerShell3.0后,极大强化了PowerShell的日志记录功能。如果启用Script Block日志记录功能(ScriptBlock Logging),可在事件日志中捕获通过PowerShell执行的命令和指令码。通过对这些日志进行分析,我们就可以检测和阻止恶意指令码。
混淆处理通常用于逃避检测。丹尼尔和福尔摩斯(均为使用者名称)在Blackhat(黑帽技术大会,是世界顶级的黑客技术会议)上释出的论文中谈到了如何应对经过混淆处理过的指令码。他们使用了逻辑回归分类算法和梯度下降法来达到合理的分类精度,最终将混淆处理过的指令码与正常指令码区分开。
然而,深度前馈神经网络(FNN)可能会增强其他效能指标,如精确度和召回率。因此,在本部落格中,我们决定使用深度神经网络,并将效能指标与不同的机器学习(ML)分类算法进行比较。

收集和生成PowerShell指令码资料集
我们已经将丹尼尔释出以及开放源代码的PowerShellCorpus资料集用于资料实验。该资料集由大约30万个PowerShell指令码组成,这些指令码是从各种开源网站(如GitHub、PowerShellGallery和TechNet)中获取的。
我们还从Poshcode中获取了PowerShell指令码,并将其新增到语料库中。最后,得到近3GB的指令码资料,其中包含30万个正常指令码。我们使用Invoke-Obfusion工具对指令码进行混淆处理。在对所有指令码进行混淆处理后,将包含类标签的资料集标记为正常指令码或混淆指令码。

资料实验
黑客在高互动蜜罐中进行的所有操作都被视作恶意行为。然而,高阶的混淆处理依然能蒙蔽混淆检测。以下是获取程序列表的一个简单PowerShell命令:
Get-Process| Where($_.Handles -gt 600}| sort Handles| Format -Table
这一命令可能被混淆处理为:
(((“{2}{9}{12}{0}{3}{10}{13}{4}{18}{8}{17}{11}{5}{16}{1}{15}{14}{7}{19}{6}"-f'-P','es','G',
'rocess8Dy Whe','{','S','le','-Ta','-gt','e','r','y ','t','e','t',' 8Dy Forma','ort Handl','600} 8D','RYl_.Handles ','b'))
-crePLACE'8Dy',[cHar]124-crePLACE'RYl',[cHar]36)| IEx
这种命令就看起来十分可疑、需要检测。下面是对同一命令进行细微混淆处理的另一示例:
&(“{1}{2}{0}"-f's','G','et-Proces')| &("{1}{0}"-f'here','W') {$_.Handles -gt600} | &("{1}{0}" -f'ort','S') Handles |.("{1}{0}{2}"-f '-','Format','Table')
这种混淆使得反病毒软件很难检测PowerShell命令/指令码的意图。大多数民间的恶意PowerShell指令码都会采用这种细微的混淆,可轻松避开反病毒软件的扫描。
安全分析人员也不可能检查每个PowerShell指令码以确定它是否经过混淆处理。因此,我们需要使混淆检测自动化。我们可以使用基于规则的方法进行混淆检测;但是,这种方法可能会遗漏很多混淆型别,还需要领域专家手动编写大量规则。因此,一种基于机器学习/深度学习的解决方案是该问题的理想答案。
通常,机器学习的第一步是资料清理和预处理。在混淆检测资料集中,资料预处理的任务就是从指令码中删除Unicode字元。
经过混淆处理的指令码和正常指令码截然不同。混淆指令码中使用的某些字串不可能出现在正常指令码中。因此,我们采用字元级,而非基于词表示PowerShell指令码。
此外,在PowerShell指令码的编写中,复杂的混淆处理有时会完全混淆词/令牌/识别符号之间的界限,使得任何基于词的标记化技术完全失效。事实上,基于字元的标记化技术也被安全研究人员用来检测PowerShell混淆指令码。
微软的李·霍尔姆斯在部落格中讨论了使用基于字元频率表示和余弦相似性来检测混淆指令码。
对字元进行向量化有多种方式。字元的独热编码用一位表示一个字元。根据指令码中是否存在该字元,位被设定为0或1。用单字元独热编码训练的分类器表现良好。
但是,通过捕获字元序列可以进一步完善这一方法。例如,像New-Object这样的命令可以被混淆处理为(‘Ne’+’w-‘+’Objec’+’t’)。加号运算子(+)在任何PowerShell指令码中都十分常见。但是,加号(+)后接单引号(‘)或双引号(“)可能就不那么常见了。因此,我们使用tf-idf字元二元语法来表示输入到分类器中的特征。
以下是训练资料集中tf-idf字元检测分数最高的20个二元语法:
正常指令码:
['er', 'te', 'in', 'at', 're', 'pa', 'st', 'on', 'me', 'en','ti', 'le', 'th', 'am', 'nt', 'es', 'se', 'or', 'ro', 'co']
混淆指令码:
["'+", "+'", '}{', ",'","',", 'er', 'te', 'in', 're', 'me', 'st', 'et', 'se', 'ar', 'on','at', 'ti', 'am', 'es', '{1']
每个指令码都用字元二元语法表示。我们使用深度前馈神经网络(FFN)处理所有这些特征,其中N个隐藏层使用Keras和TensorFlow工具。
 图1:深度前馈神经网络混淆检测资料流程图
图1:深度前馈神经网络混淆检测资料流程图
上面的资料流程图显示了混淆检测的训练和预测流程。我们尝试了深度前馈神经网络中隐藏层的各种值,最后发现N=6是最佳值。
RELU启用函式适用于所有隐藏层。每个隐藏层本质上都是全连线层(dense),输入是1000维,神经网络单元丢弃率为0.5。在最后一层,Sigmiod函式被用作启用函式。下列图2展示了用于混淆检测的深度前馈神经网络:
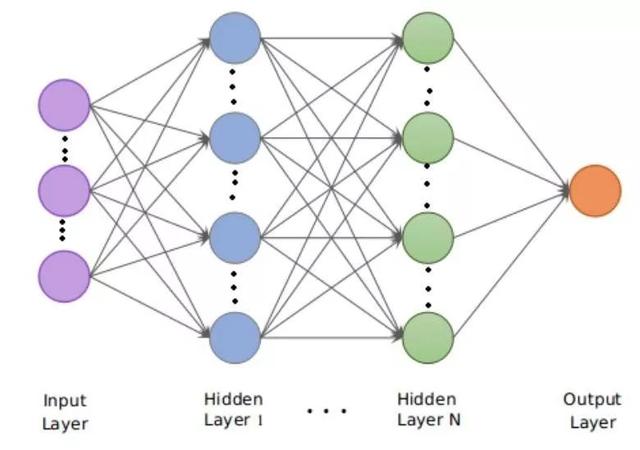 图2:用于混淆检测的深度前馈神经网络
图2:用于混淆检测的深度前馈神经网络
可以看到,验证的精确度接近92%,这表明该模型在训练集之外得到了很好的应用。
接下来,在测试集中测试该模型,得到的准确率为93%,混淆类的召回率为0.99。下列图3展示了每个时期训练和验证资料的分类精度以及分类损失函式图:
 图3:训练和验证阶段的分类精度以及损失函式图
图3:训练和验证阶段的分类精度以及损失函式图
对比下表中其他机器学习模型的资料,看一看深度前馈神经网络的结果。精确度和召回率可以用来衡量各种模型的有效性:

目标是将大多数混淆指令码检测出来。换句话说,我们想将混淆类的检测错误率降到最低。在这种情况下,召回率似乎是一个合适的衡量指标。
表1显示,与其他分类器相比,深度前馈神经网络模型的召回率更高。在实验中使用的是中等大小的资料集。日常使用的资料集通常很大,因此,与其他机器学习分类器相比,深度前馈神经网络的效能更好。
PowerShell混淆处理确实是避开现有反病毒软件、隐藏黑客意图的好方法。目前很多黑客都在使用这种技术。

留言 点赞 关注
我们一起分享AI学习与发展的干货
欢迎关注全平台AI垂类自媒体 “读芯术”


































