
Kubernetes 已经成为事实上的编排平台的领导者,下一代分散式架构的王者,其在自动化部署、扩充套件性、以及管理容器化的应用中已经体现出独特的优势,在企业中应用落地已经成为一种共识。本次“K8S 技术落地实践”杭州站,青云QingCloud 软件工程师万宏明为大家带来《高效运维 K8S 丛集》主题分享。

随着微服务架构和容器技术的普及,应用被拆分的越来越细,这也对开发运维人员提出了新的要求。一旦丛集中执行的应用出现故障,需要面对的是成千上万个执行中的容器和复杂的网络环境,如果你需要借助 K8S 强大的容器编排能力,就必须要深入的去了解 K8S 的特性,能够快速的定位问题,处理故障。
今天给大家带来的分享主题高效运维 K8S 丛集将从三个话题进行展开,首先带大家了解一下 K8S 的丛集架构,再给大家分享一下我们在丛集运维中的一些经验,最后和大家探讨如何打造一个高可用的 K8S 丛集。
1
K8S 的丛集架构
 K8S 的丛集架构主要有两部分内容,一是 K8S 的设计和架构,二是 K8S 的系统分层。
K8S 的丛集架构主要有两部分内容,一是 K8S 的设计和架构,二是 K8S 的系统分层。
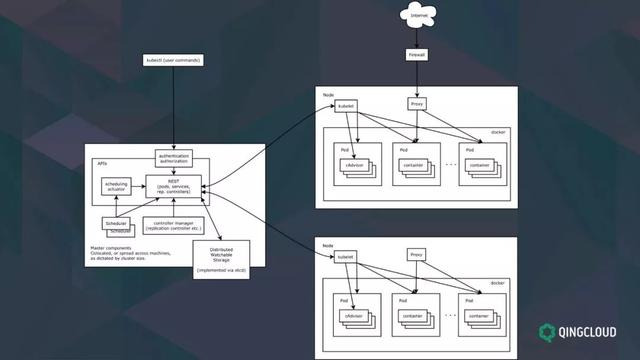 这是一张 K8S 的元件架构图,图中左侧是 K8S 中控制平面的一些元件包括 kube-apiserver、etcd、kube-controller-manager、kube-scheduler 等,这些元件是整个 K8S 的核心;右侧是 Worker 节点上的核心元件,kubelet、kube-proxy 这两个元件负责节点上容器的排程和管理 (包括网络和储存)。
这是一张 K8S 的元件架构图,图中左侧是 K8S 中控制平面的一些元件包括 kube-apiserver、etcd、kube-controller-manager、kube-scheduler 等,这些元件是整个 K8S 的核心;右侧是 Worker 节点上的核心元件,kubelet、kube-proxy 这两个元件负责节点上容器的排程和管理 (包括网络和储存)。
K8S 元件接管了整个节点上的容器排程和管理工作,接受来自控制平面的任务,为容器分配网络和储存。在节点上,这些元件会定时向控制平面上报当前节点的状态,方便丛集中的 Scheduler 进行排程。
 总结来说,K8S Master 节点上的元件也就是我们现在所说的核心元件。常用的包括 K8S API Server,它提供了所有资源的操作入口,提供了资源操作的唯一入口,并提供认证、授权、访问控制、API 注册和发现等机制。在 K8S 丛集中 etcd 是很重要的,K8S 依赖 etcd 储存整个丛集的状态。
总结来说,K8S Master 节点上的元件也就是我们现在所说的核心元件。常用的包括 K8S API Server,它提供了所有资源的操作入口,提供了资源操作的唯一入口,并提供认证、授权、访问控制、API 注册和发现等机制。在 K8S 丛集中 etcd 是很重要的,K8S 依赖 etcd 储存整个丛集的状态。
第三个是 Controller-Manager,它负责维护整个丛集中资源的状态,并且提供 API 。所有的 API 都是宣告式的 API ,宣告式的意思是说我描述我的 Depolyment 需要达到什么样的状态,最后它的状态转变是由 Controller 实现的。无论是 Prometheus Operator 还是 Istio 核心元件,都可能用到大量的 CRD 资源,他们需要用这些资源支援 K8S 中没有的概念。
刚刚讨论的是 K8S 的架构。现在大家看到的是另一个层面的东西,整个 K8S 的系统分层。
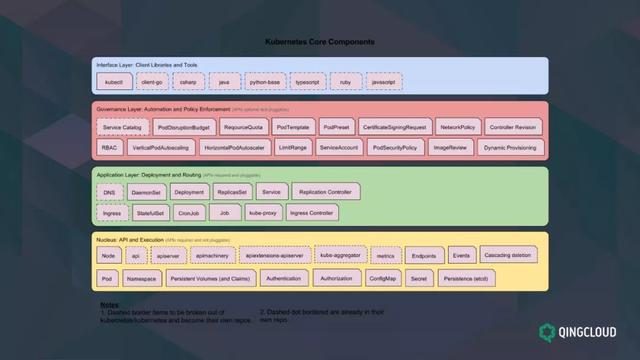 K8S API 或者架构是如何设计的?
K8S API 或者架构是如何设计的?
大家看到最底层黄色的是 K8S 最核心的功能,核心功能包括现在所说的 Pod、Namespace、Secret,还有 Service,这些都是 K8S 最基础的功能。在最基础的功能之上才能封装图中绿色方块的应用负载,如 DaemonSet、Depolyment,这些都是在应用层上的封装,都是通过 Controller-Manager 维护的。
其本质是,任何一个 Workload 都是由 Pod 组成的,有了底层 Pod 概念的支援,上面才会有 Depolyment 的资源理念。
再往上层是 K8S 管理者的东西,包括 K8S 中的 RBAC,这需要我们执行运维,我们可能需要对 Pod 的安全进行加固。再后面的是我们需要对 API Server 或者 Controller 进行度量,我们可能需要开发管理外挂。这是第三层。
往上是开发者和运维人员用得比较多的界面层,如 kubectl、SDK,这些都是我们开发者直接接触到的。
 总的来说,这分为五层:核心层、应用层、治理层,界面层和外围生态系统。我们作为 K8S 之上的应用开发者,我们更关注的是构建在 K8S 之上的生态应用,包括我们在 K8S 之上可以构建我们的监控系统,配置 etcd,这些功能都是建立在 K8S 界面之上的。
总的来说,这分为五层:核心层、应用层、治理层,界面层和外围生态系统。我们作为 K8S 之上的应用开发者,我们更关注的是构建在 K8S 之上的生态应用,包括我们在 K8S 之上可以构建我们的监控系统,配置 etcd,这些功能都是建立在 K8S 界面之上的。
另一种层面,K8S 与原有的界面、拓展层,包括 CRI、CSI 等机制都结合的非常紧密。通过 K8S CRD API 聚合方式,我们可以把丛集配置做到足够自动化。有了 K8S 强大的外挂机制,可以让我们丛集运维、使用管理变得非常简单。
2
常见故障及其处理方式
 只有熟悉 K8S 整个丛集的架构体系,我们才能支援 K8S 的运维。在我们运维 K8S 丛集中也遇到了非常多的问题,下面我会讲讲我们在执行 K8S 丛集过程中遇到的具体问题以及我们收集问题的方式。
只有熟悉 K8S 整个丛集的架构体系,我们才能支援 K8S 的运维。在我们运维 K8S 丛集中也遇到了非常多的问题,下面我会讲讲我们在执行 K8S 丛集过程中遇到的具体问题以及我们收集问题的方式。
主要包括三部分内容:
第一,我们如何处理故障,我们是按照什么样的顺序排查我们线上应用出现哪些问题。
第二,简单分享我们常常遇到的问题以及如何解决。
第三,如何避免线上业务出现这样的问题。
当线上应用出现问题时,突然发现某个服务不能访问了,我们该如何快速定位这个东西?
也许在之前单机运维场景下,我们很明确的知道不是 LB 的问题,是我们应用的问题。在微服务环节下,应用的排程链路变得非常长,一个应用不能访问,造成问题的点可能非常多,这时候我们需要有序地对整个丛集进行检查,定位问题、发现问题并且解决问题。
假如我们发现一个服务不可访问,首先需要检查丛集几个点是否正常?K8S 整个丛集是否正常?
 我们可以通过检视节点是否正常,一是保证 K8S API Server 是正常的,二是可以检视节点丛集网络中是否存在节点异常。如果我们在第一步发现哪个节点挂掉了,这时候我们可以重启节点,对节点上的应用进行恢复。假如我们发现这个节点挂掉是因为丛集资源不够,这时候我们要及时增加丛集节点,否则哪怕是重启丛集,可能还是会挂掉。
我们可以通过检视节点是否正常,一是保证 K8S API Server 是正常的,二是可以检视节点丛集网络中是否存在节点异常。如果我们在第一步发现哪个节点挂掉了,这时候我们可以重启节点,对节点上的应用进行恢复。假如我们发现这个节点挂掉是因为丛集资源不够,这时候我们要及时增加丛集节点,否则哪怕是重启丛集,可能还是会挂掉。
通过第一步,我们并没有发现丛集中的节点有什么问题,我可能需要看到应用本身的部分,我们需要检视应用本身的日志,需要检视涉及的 Pod 日志。执行时可以看到确认两点,一是看 Pod 基础网络是否通畅,通过日志检视这个应用是不是在执行过程中发现一些问题,是不是有一些错误的日志在里面。二是解决在启动时遇到的常见问题。
假设我们发现 Pod 没有错误情况发生,这时候我们可能需要看看 K8S 核心元件,包括 kube-apiserver,kube-scheduler,kube-controller-manager 的日志。这时候我们可以检视 K8S 核心元件的配置,看有没有问题。
第四步工作是检查 Service 是否可以访问,这时候我们需要检视 DNS 或者 kube-proxy 日志,可以很简单的检视 DNS 或者 kube-proxy 有没有报错。有些人习惯性地在某些 Pod 上抓包或者在节点上进行抓包,这种效率是非常低的。
实在没有定位到问题的话,还可以看看每个节点上 Kubelet,如果 Kubelet 上有错误资讯发生,可能就是因为这个节点上 Kubelet 发生了一场灾难,需要我们重新做节点。
以上五种情况可以解决丛集中大部分的网络、储存和应用本身的异常。核心依赖是本身丛集就有监控系统、监控告警系统,通过这种方式直接在我们监控系统中检视丛集中是不是有哪个节点异常。假如我们是微服务应用,还可以检视是不是某一个微服务中的某个链路断开了。
 除了以上谈到的丛集故障,我们还会遇到常见的应用故障。
除了以上谈到的丛集故障,我们还会遇到常见的应用故障。
第一种是 Pod 启动后一直处于 Pending 的状态,表示这个 pod 没有被排程到一个节点上。在我们实际场景中,大部分是因为节点上的资源不足引起的。
第二种是使用了 hostPort 导致端口出现冲突,服务无法正常启动。
第三种是如果你的程式在 Waiting 中,则表示这个 pod 已经除错到节点上,但是没有执行起来,通过 kubectl describe 这个命令来检视相关资讯。最常见的原因是拉取映象失败,这个情况在私有云环境中非常常见。
第四种跟我们应用本身使用引数或者应用本身的程式码有关系,这里有一个典型的例子——MySQL。我相信有在 K8S 上部署 MySQL 的使用者,都可能遇到这个问题。MySQL 在使用时,假如你的磁盘中快取不足,这时候我们需要查一查 MySQL 的报错,错误资讯会很明确地告诉你需要调大引数,这是都是通过 Controller 命令就可以查到的。假如 Pod 一直 restart 的话,我们可能需要检视它之前的日志。
第五种,Service 提供了多个服务和多个 Pod 之间的负载均衡功能。假设你的服务不可访问时,这时候我们需要考量,可以通过 Controller 检视 Service 下有没有挂载具体的 Pod。
 我们的丛集有时候会出现状况,比如我们的 CPU 或者内存不足,导致节点异常、宕机,或者整个丛集网络中断、闪断。
我们的丛集有时候会出现状况,比如我们的 CPU 或者内存不足,导致节点异常、宕机,或者整个丛集网络中断、闪断。
如果节点异常,这时候需要快速重启节点,资源不足要增加节点。如果节点频繁抖动导致业务出现漂移,这时候我们会检查一下 Controller-Manager 中的引数,配置响应引数,设定它整个节点状态检测周期。
如果我们发现 K8S 中发生异常,比如我们发现 Controller-Manager 挂了,或者 Cloud-Controller-Manager 挂了,最核心的是检视日志,及时把这些节点重启起来。最核心的需求是我们需要保证关键元件高可用,包括我们需要让这些元件一直保持在多个副本中。
储存和网络是 K8S 整个环境中最容易出问题的地方,一般像网络出现问题,定位它会像其他似的,我们需要由上至下一层层地筛选,在哪一层的网络出现问题。
 由于 K8S 整个丛集的负载是我们平时无法应付的,所以我们要想办法避免问题,我总结以下四点,帮助我们开发者规避丛集中可能遇到的情况。
由于 K8S 整个丛集的负载是我们平时无法应付的,所以我们要想办法避免问题,我总结以下四点,帮助我们开发者规避丛集中可能遇到的情况。
第一点是我们丛集搭建起来,真正落地到生产环境中时,我们非常依赖丛集中的监控系统,我们需要 Prometheus,需要 Docker 系统,帮助我们实时监控丛集中的资源状况。如果哪个节点发生异常,我们需要及时收到通知。
开发者或者运维人员很容易忽略的一点,假设我们丛集中部署了一些 Prometheus 或者日志的元件,我们可能会忽略这些系统元件本身会消耗掉一部分系统资源。
当我们节点不断增加,这些系统元件上面会有 overhead ,它还是会消耗资源。如果应用越来越多、Pod 越来越多,这些系统元件也会有更多的资源消耗,如果没有给系统元件足够的资源会导致这些关键系统元件崩溃,我们需要给他们设定合适的资源限制,需要根据丛集规模不断地调整。至少保证我们的监控告警系统正常执行。
第二点是很多时候 K8S 往往会暴露出非常多的安全问题,我们要实时关注,及时修复丛集中可能出现的问题。
第三点是应用层的优化,当我们应用出现问题时,如果我们想要快速恢复它,一个大前提是我们要保证应用是无状态的,不依赖于任何储存。有状态应用的恢复比无状态应用的恢复起来麻烦得多。无状态应用,我们可以让应用恢复副本数,充分利用 K8S 排程编排的优势,这是和普通传统应用有区别的地方。我们可以通过这种方式避免我们在 K8S 丛集中的应用出现问题。
最重要一点,我们需要及时备份丛集中的资料,之前我们发生了一场线上灾难,通过备份资料得以进行恢复,没有影响到业务。
3
如何打造 K8S 高可用架构
 即使我们有高可用架构,还是避免不了监控、告警和日志的系统元件。这是最典型的 K8S 多节点架构图:
即使我们有高可用架构,还是避免不了监控、告警和日志的系统元件。这是最典型的 K8S 多节点架构图:
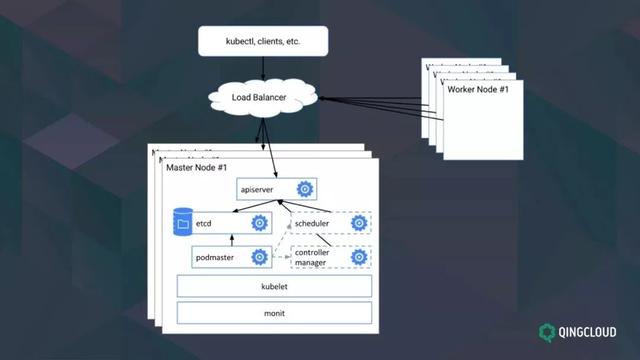 K8S 高可用架构包括以下四个步骤:
K8S 高可用架构包括以下四个步骤:
建立一个冗余的,可靠的储存层,etcd 丛集
K8S apiserver 的高可用,多节点多副本,apiserver 负载均衡
kube-scheduler,kube-controller-manager,核心元件支援多副本选主
重新配置 kubelet 和 kube-proxy,--apiserver 指向 apiserver lb
光有高可用的丛集架构只能保证我们 K8S 丛集可用,实际上我们最终还是要用自己的应用,我们需要大量依赖日志系统、监控系统、高可用系统,对我们丛集中运维实际日志的业务系统进行监控。
如果需要中的日志进行收集,我们可以通过 ELK 这种方案,对所有的 Pod 进行收集。我们可以接入视觉化的方案进行检视。刚刚有人提到 Prometheus,Prometheus 本身有 Manager 这样专案,Manager 有非常大的短板,所以在实际过程中有很多开发者都会自己实现。
最简单的方案是 KubeSphere® 提供一键式的部署,下面有监控、日志、告警所有的解决方案。
4
总结
Kubernetes 发展迅速,今天我总结的是我们常用的除错问题和解决问题的方式,不一定适用于每个人或者每个企业。你在使用 Kubernetes 时,我们需要及时关注新版本的变化,它可能会针对某个环境下的问题修复,我们可以对不熟悉的问题多加实验,最大程度的减少丛集中可能出现的问题。我们需要熟练应用 K8S 本身的命令列工具,如 Controller 等功能。
最后,我认为命令列操作非常繁琐,大家可以看看我们如何通过 UI 系统建立 K8S 中的服务,同时我们还集成了一键式 CI/CD、Istio 等,欢迎大家下载我们 KubeSphere® 体验一下。
点选阅读原文,一键下载资料。
系列分享回顾:
万字干货 | K8S 技术落地实践上海站分享
-FIN-
7 月 25 日, 秉承科技前沿与企业实践并重的 CIC 大会再度来袭,为大家奉上一场科技盛宴。依旧硬核依旧资讯过载,干货满满,绝对让你不虚此行。长按识别下面二维码,即刻报名!



































