
熟悉资料科学的人都很喜欢NumPy库,它是时下最流行的Python系数据科学的中流砥柱,是Python科学计算、资料分析以及AI 机器学习的基础元件。在最流行的三大资料处理栈R、Matlab和Python中,NumPy是最重要的元件之一,有很多Python系的资料处理系统都依赖NumPy作为其基础架构的基础部分,比如tensorflow、pandas、SciPy和scikit-learn等。
NumPy极大地简化了向量和矩阵的操作和处理。本文中虫虫将一影象视觉化方式介绍NumPy的主要方法,以及在ML资料模型中的资料表示,图文并茂的方式系统对大家的学习有所帮助。
阵列
建立阵列
阵列的建立通常是通过使用`np.array()`,并将列表传递给它。如下图: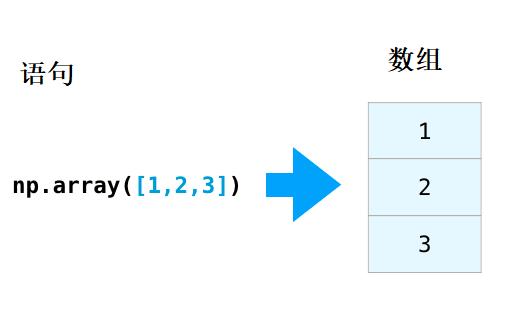
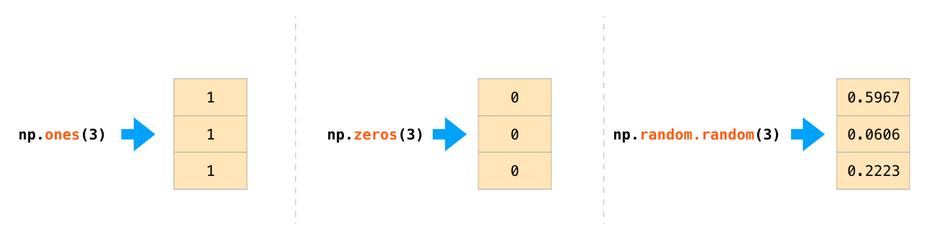
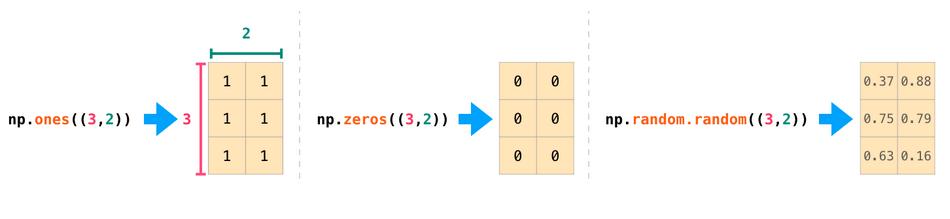
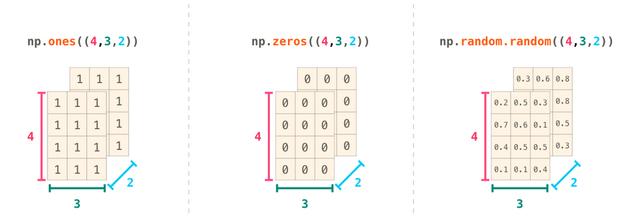
在建立时候NumPy也提供了很多方法帮我们初始化阵列,这些方法包括:ones(),zeros()和random.random()。其引数为要生成的元素个数:
阵列计算
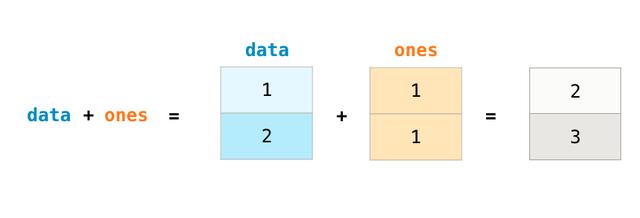
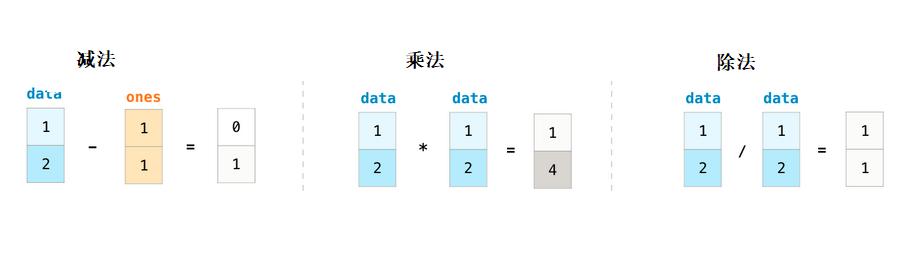
做为例子我们首先建立两个阵列data和one:
最其做加法运算,其实很简单就是对应位置元素互相想加。
NumPy在处理这些计算时候,简单就想正常数学计算一样,不像其他语言中那样复杂的处理方式(比如做计算符号过载)。从而可以让我们专注于数学计算而不是怎么用循环表示。更多计算:
实际中,也有阵列和单个数字之间执行计算(也称为向量和标量之间的计算)。比如,我们的阵列表示以英里为单位的距离,我们希望将其转换为公里数。我们可以简单使用data *1.6:
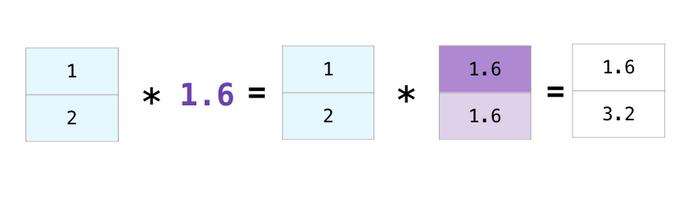
NumPy对每个元素都会做了乘法计算。这个又叫做广播,一个非常有用的概念。
索引
我们可以通过各种方式列表切片方式来表示NumPy阵列部分和对其索引:
聚合计算
NumPy也支援各种聚合函式: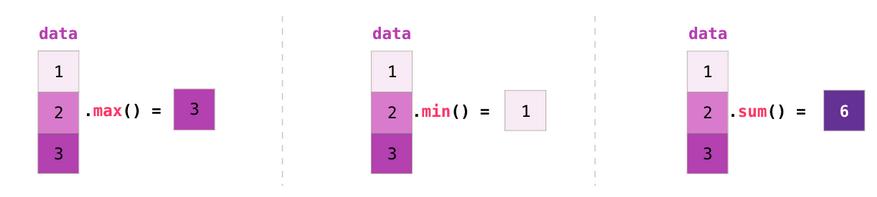
除了最小值,最大值和总和之外,还支援很多其他统计函式你,比如平均值mean,所有元素相乘的累乘prod,标准差std,及其他。
多维度
截止当前,我们所有例子都是在一个维度上处理向量。 NumPy强大之处的关键是它能够将所有方法都应用到任意数量的维度。建立矩阵
我们可以给array函式传递如下python列表引数,NumPy就会建立一个矩阵:np.array([[1,2],[3,4]])

也可以使用上面提到的相同方法(ones(),zeros()和random.random()),只要我们给它们一个元组来表示正在建立的矩阵的维度:
矩阵计算
如果两个矩阵的大小相同,我们可以使用算术运算子(+ - * /)来对矩阵计算。 NumPy将这些作为位置操作处理: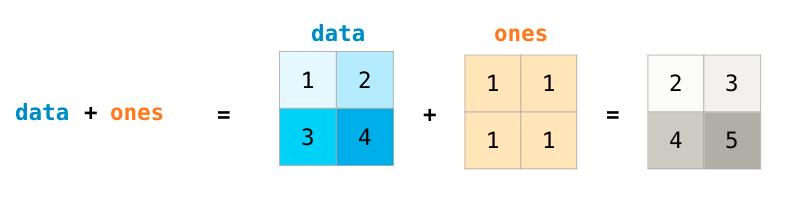
只有当不同维度为1时(例如矩阵只有一列或一行),我们才能在不同大小的矩阵上进行这些算术运算,在这种情况下,NumPy将其广播规则用于该操作:
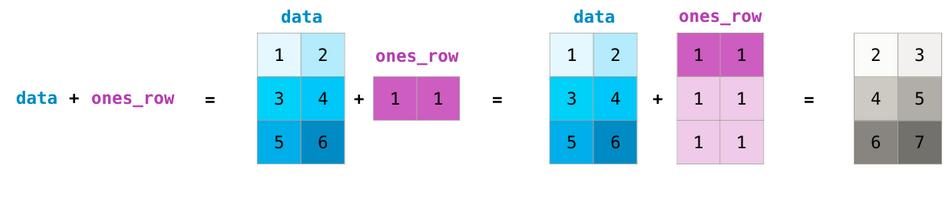
点计算
与算术相关的一个关键区别是使用点积的矩阵乘法。 NumPy为每个矩阵提供了一个dot()方法,我们可以用它来执行与其他矩阵的点积运算:
这个图的底部添加了矩阵尺寸,以强调两个矩阵在它们彼此面对的一侧必须具有相同的尺寸。可以将此操作视觉化为如下所示:

矩阵索引
当我们操作矩阵时,索引和切片操作会变得更加有用: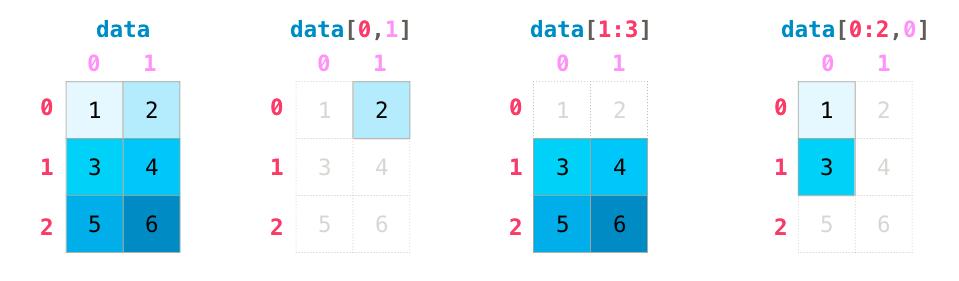
矩阵聚合
我们可以像聚合阵列一样聚合矩阵:
我们不仅可以聚合矩阵中的所有值,还可以使用axis引数对行或列进行聚合:
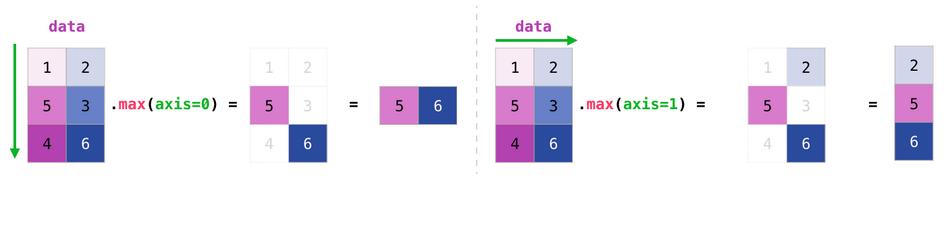
转置和重塑
处理矩阵时的一个共同需求是需要旋转矩阵。当我们需要采用两个矩阵的点积并需要对齐它们共享的维度时,通常就是这种情况。 NumPy阵列有一个方便的属性叫做T来获得矩阵的转置: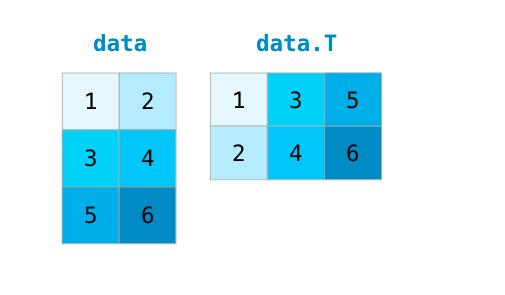
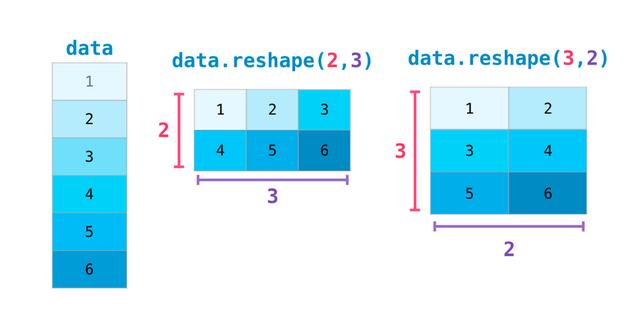
在更高阶的用例中,可能需要切换某个矩阵的维度。在机器学习应用程序中通常会有这种情况,其中某个模型期望输入的某个维度与资料集不同。在这些情况下,NumPy的reshape()方法很有用。只需将矩阵所需的新尺寸传递给它即可,可以为维度传递-1,NumPy可以根据已有矩阵推断出正确的维度:
更多维度
NumPy可以完成我们在任何维度上提到的所有内容。其中心资料结构称为ndarray(N维阵列)。
在很多时候,处理新维度只是在NumPy函式的引数中新增逗号:
实际用法——资料表示方法
最后来干货,我们来举一些NumPy能帮助你完成的有用示例包括公式和资料表示:公式
实现适用于矩阵和向量的数学公式是考虑NumPy的关键用例。这就是NumPy是科学Python社群的宠儿主要原因。例如,考虑平均误差公式,它是监督机器学习模型处理回归问题的核心: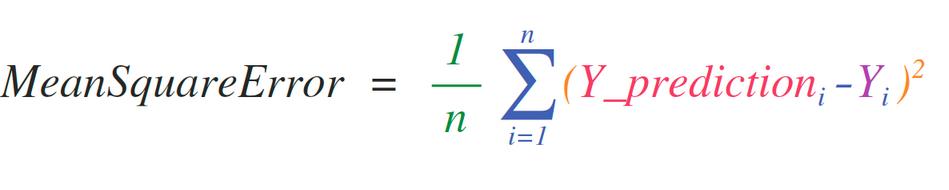
在NumPy中实现它是轻而易举的:

这样做的好处是,numpy并不会关心预测和标签是否包含一个或一千个值(只要它们的大小相同)。可以通过一个示例逐步执行该程式码行中的四个操作:

预测和标签向量都包含三个值。这意味着n的值为3。执行减法后,最终得到如下值:

然后就可以对向量中的值进行平方

最后:

资料表示
试想我们需要紧缩和构建模型所需的所有资料型别(电子表格,影象,音讯......等)。其中很多都非常适合在n维阵列中表示:表格和电子表格
电子表格或值表是二维矩阵。电子表格中的每个工作表都可以是自己的变数。 Python中最受欢迎的抽象是pandas资料帧,它实际上使用NumPy并在其上构建。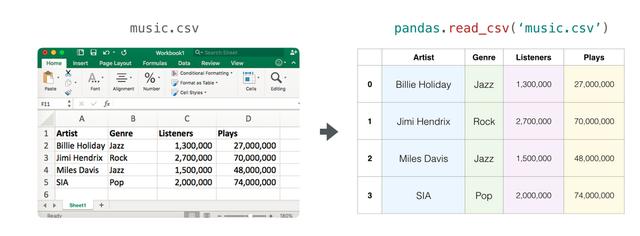
音讯和时间序列
音讯档案是一维样本阵列。每个样本都是一个代表音讯讯号的一小部分的数字。 CD质量的音讯每秒可能有44,100个样本,每个样本是-65535到65536之间的整数。这意味着如果你有一个10秒的CD质量的WAVE档案,你可以将它载入到长度为10 * 44,100的NumPy阵列中= 441,000个样本。想要提取音讯的第一秒?只需将档案载入到音讯的NumPy阵列中,然后获取音讯[:44100]。以下是一段音讯档案:
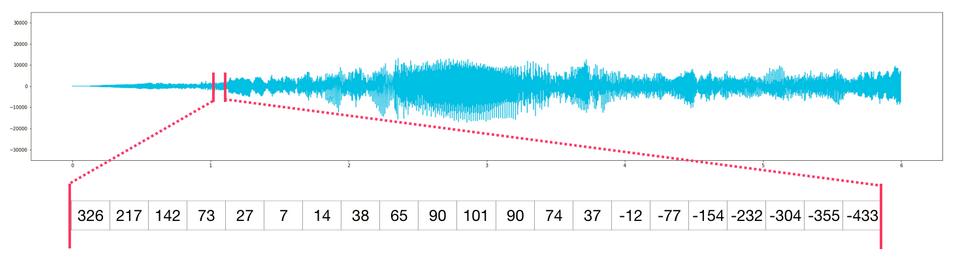
时间序列资料也是如此(例如,股票价格随时间变化)。
图片
影象是大小(高x宽)画素的矩阵。如果影象是黑白的(a.k.a.灰度),则每个画素可以用单个数字表示(通常在0(黑色)和255(白色)之间)。想要裁剪影象的左上角10 x 10画素部分?告诉NumPy通过image[:10,:10]。
下面一个影象档案的片段:

如果影象是彩色的,则每个画素由三个数字表示:红色,绿色和蓝色各自的值。在这种情况下,我们需要第三维(因为每个单元格只能包含一个数字)。因此彩色影象由尺寸的ndarray表示:(高x宽x 3)。

自然语言
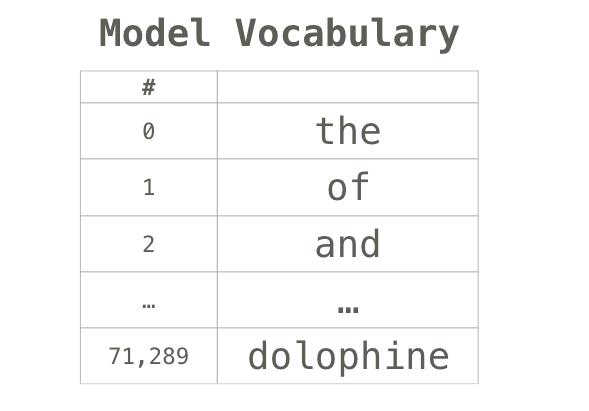
如果我们处理文字,资料就会有所不同。文字的数字表示需要一个构建词汇表的步骤(模型知道的所有唯一单词的清单)和嵌入步骤。让我们看看用古代用数字表示这个引用的步骤:我们可以继续处理一个小资料集并使用它来构建一个词汇表(71,290个单词):
然后可以将句子分成一系列标记(基于通用规则的单词或单词部分):

然后我们用词汇表中的id替换每个单词:

这些ID仍然不能为模型提供太多资讯价值。因此,在将一系列单词提供给模型之前,需要使用嵌入来替换标记/单词(比如:50维word2vec嵌入):

以看到此NumPy阵列的维度为[embedding_dimension x sequence_length]。在实践中,这些将是另一种方式,但我以这种方式呈现它的视觉一致性。出于效能原因,深度学习模型倾向于保留批量大小的第一维(因为如果并行训练多个示例,则可以更快地训练模型)。这是一个明显的情况,reshape()变得非常有用。例如,像BERT这样的模型会期望其输入形状为:[batch_size,sequence_length,embedding_size]。

现在这是一个数字卷,模型可以处理并执行有用的操作。其他行被留空了,但是他们会填充其他示例以供模型训练(或预测)。


































