
我们已经知道,list 和 tuple 可以用来表示顺序集合,例如,班里同学的名字:
L = ['大宝', '二宝', '三宝']
或者考试的成绩列表:
M = [95, 85, 59]
但是,要根据名字找到对应的成绩,用两个 list 表示就不方便。
如果把名字和分数关联起来,组成类似的查询表:
'大宝' ==> 95'二宝' ==> 85'三宝' ==> 59
给定一个名字,就可以直接查到分数。
Python中的dict 就是专门干这件事的。用 dict 表示"名字"-"成绩"的查询表如下:
d = { '大宝':95, '二宝':85, '三宝':59}
我们把名字称为key,对应的成绩称为value,dict就是通过 key 来查询 value。
花括号 {} 表示这是一个dict,然后按照 key: value, 写出来即可。最后一个 key: value 的逗号可以省略。
由于dict也是集合,len() 函式可以计算任意集合的大小:

注意: 一个 key-value 算一个,因此,dict大小为3。
试一试:
新来的 川普 同学成绩是 75 分,请编写一个dict,把 川普 同学的成绩也加进去。
访问dict
我们已经能建立一个dict,用于表示名字和成绩的对应关系:
d = { '大宝':95, '二宝':85, '三宝':59}print(len(d))
那么,如何根据名字来查询对应的成绩呢?
可以简单地使用 d[key] 的形式来查询对应的 value,这和 list 很像,不同之处是,list 必须使用索引返回对应的元素,而dict使用key:

注意: 通过 key 访问 dict 的value,只要 key 存在,dict就返回对应的value。如果key不存在,会直接报错:KeyError。比如:

要避免 KeyError 发生,有两个办法:
一是先判断一下 key 是否存在,用 in 操作符:

如果 'Paul' 不存在,if语句判断为False,自然不会执行 print d['Paul'] ,从而避免了错误。
二是使用dict本身提供的一个 get 方法,在Key不存在的时候,返回None:

试一试:
根据下面的dict:
d = { '大宝':95, '二宝':85, '三宝':59}
请打印出:
}Adam: 95Lisa: 85Bart: 59
dict的特点
dict的第一个特点是查询速度快,无论dict有10个元素还是10万个元素,查询速度都一样。而list的查询速度随着元素增加而逐渐下降。
不过dict的查询速度快不是没有代价的,dict的缺点是占用内存大,还会浪费很多内容,list正好相反,占用内存小,但是查询速度慢。
由于dict是按 key 查询,所以,在一个dict中,key不能重复。
dict的第二个特点就是储存的key-value序对是没有顺序的!这和list不一样:

打印的顺序不一定是我们建立时的顺序,而且,不同的机器打印的顺序都可能不同,这说明dict内部是无序的,不能用dict储存有序的集合。
dict的第三个特点是作为 key 的元素必须不可变,Python的基本型别如字串、整数、浮点数都是不可变的,都可以作为 key。但是list是可变的,就不能作为 key。
可以试试用list作为key时会报什么样的错误。
不可变这个限制仅作用于key,value是否可变无所谓:

最常用的key还是字串,因为用起来最方便。
更新dict
dict是可变的,也就是说,我们可以随时往dict中新增新的 key-value。比如已有dict:
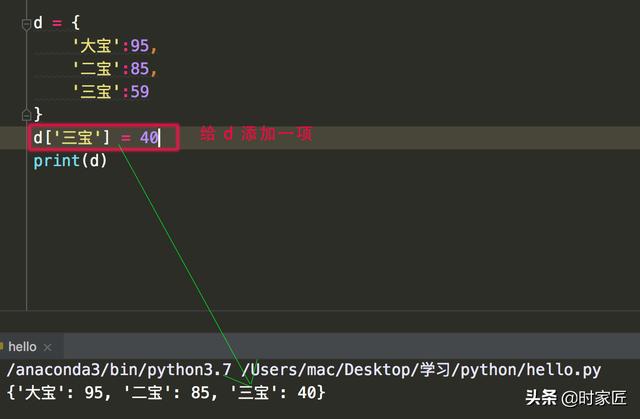
我们上面说,dict是可以变的,但是dict中的 key 值是不可以变的,如果key值重复了,会发生什么呢?看下图:

试一试:
请根据 三宝 的成绩 72 更新下面的dict:
d = { '大宝':95, '二宝':85, '三宝':59}
好好学哦,加油。


































