
一、背景
Apache Flink 和 Apache Storm 是当前业界广泛使用的两个分散式实时计算框架。其中 Apache Storm(以下简称“Storm”)在美团点评实时计算业务中已有较为成熟的运用,有管理平台、常用 API 和相应的档案,大量实时作业基于 Storm 构建。
Apache Storm参考连结:http://storm.apache.org/
而 Apache Flink(以下简称“Flink”)在近期倍受关注,具有高吞吐、低延迟、高可靠和精确计算等特性,对事件视窗有很好的支援,目前在美团点评实时计算业务中也已有一定应用。
Apache Flink参考连结:https://flink.apache.org/
为深入熟悉了解 Flink 框架,验证其稳定性和可靠性,评估其实时处理效能,识别该体系中的缺点,找到其效能瓶颈并进行优化,给使用者提供最适合的实时计算引擎,我们以实践经验丰富的 Storm 框架作为对照,进行了一系列实验测试 Flink 框架的效能。
计算 Flink 作为确保“至少一次”和“恰好一次”语义的实时计算框架时对资源的消耗,为实时计算平台资源规划、框架选择、效能调优等决策及 Flink 平台的建设提出建议并提供资料支援,为后续的 SLA 建设提供一定参考。
Flink 与 Storm 两个框架对比:

二、测试目标
评估不同场景、不同资料压力下 Flink 和 Storm 两个实时计算框架目前的效能表现,获取其详细效能资料并找到处理效能的极限;了解不同配置对 Flink 效能影响的程度,分析各种配置的适用场景,从而得出调优建议。
1、测试场景
1)“输入-输出”简单处理场景
通过对“输入-输出”这样简单处理逻辑场景的测试,尽可能减少其它因素的干扰,反映两个框架本身的效能。
同时测算框架处理能力的极限,处理更加复杂的逻辑的效能不会比纯粹“输入-输出”更高。
2)使用者作业耗时较长的场景
如果使用者的处理逻辑较为复杂,或是访问了数据库等外部元件,其执行时间会增大,作业的效能会受到影响。因此,我们测试了使用者作业耗时较长的场景下两个框架的排程效能。
3)视窗统计场景
实时计算中常有对时间视窗或计数视窗进行统计的需求,例如一天中每五分钟的访问量,每 100 个订单中有多少个使用了优惠等。Flink 在视窗支援上的功能比 Storm 更加强大,API 更加完善,但是我们同时也想了解在视窗统计这个常用场景下两个框架的效能。
4)精确计算场景(即讯息投递语义为“恰好一次”)
Storm 仅能保证“至多一次” (At Most Once) 和“至少一次” (At Least Once) 的讯息投递语义,即可能存在重复传送的情况。
有很多业务场景对资料的精确性要求较高,希望讯息投递不重不漏。Flink 支援“恰好一次” (Exactly Once) 的语义,但是在限定的资源条件下,更加严格的精确度要求可能带来更高的代价,从而影响效能。
因此,我们测试了在不同讯息投递语义下两个框架的效能,希望为精确计算场景的资源规划提供资料参考。
2、效能指标
1)吞吐量(Throughput)
2)延迟(Latency)
三、测试环境
为 Storm 和 Flink 分别搭建由 1 台主节点和 2 台从节点构成的 Standalone 丛集进行本次测试。其中为了观察 Flink 在实际生产环境中的效能,对于部分测内容也进行了 on Yarn 环境的测试。
1、丛集引数

2、框架引数

四、测试方法
1、测试流程

1)资料生产
Data Generator 按特定速率生成资料,带上自增的 id 和 eventTime 时间戳写入 Kafka 的一个 Topic(Topic Data)。
2)资料处理
Storm Task 和 Flink Task (每个测试用例不同)从 Kafka Topic Data 相同的 Offset 开始消费,并将结果及相应 inTime、outTime 时间戳分别写入两个 Topic(Topic Storm 和 Topic Flink)中。
3)指标统计
Metrics Collector 按 outTime 的时间视窗从这两个 Topic 中统计测试指标,每五分钟将相应的指标写入 MySQL 表中。
Metrics Collector 按 outTime 取五分钟的滚动时间视窗,计算五分钟的平均吞吐(输出资料的条数)、五分钟内的延迟(outTime - eventTime 或 outTime - inTime)的中位数及 99 线等指标,写入 MySQL 相应的资料表中。最后对 MySQL 表中的吞吐计算均值,延迟中位数及延迟 99 线选取中位数,绘制影象并分析。
2、预设引数
3、测试用例
1)Identity

▲ Identity 流程图
2)Sleep

▲ Sleep 流程图
3)Windowed Word Count
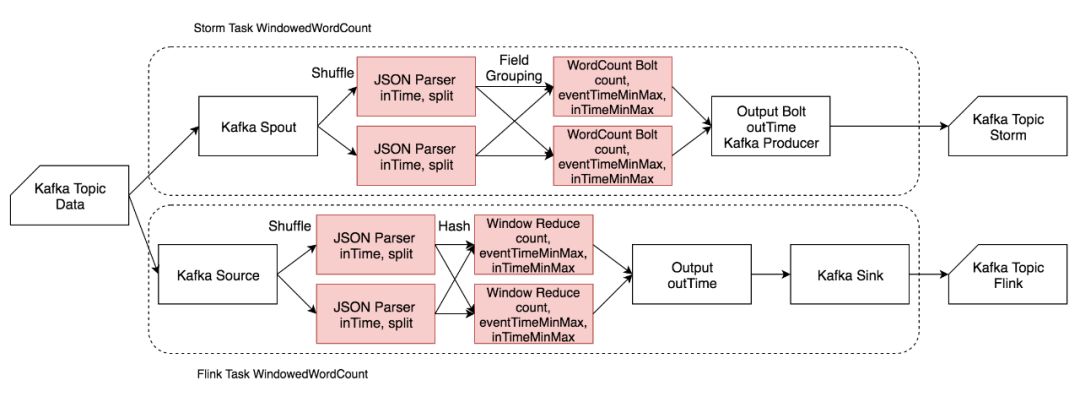
▲ Windowed Word Count 流程图
五、测试结果
① Identity 单执行绪吞吐量

▲ Identity 单执行绪吞吐量
② Identity 单执行绪作业延迟

▲ Identity 单执行绪作业延迟
③ Sleep吞吐量

▲ Sleep 吞吐量
④ Sleep 单执行绪作业延迟(中位数)

▲ Sleep 单执行绪作业延迟(中位数)
⑤ Windowed Word Count 单执行绪吞吐量

▲ Windowed Word Count 单执行绪吞吐量
⑥ Windowed Word Count Flink At Least Once 与 Exactly Once 吞吐量对比

▲ Windowed Word Count Flink At Least Once 与 Exactly Once 吞吐量对比
⑦ Windowed Word Count Storm At Least Once 与 At Most Once 吞吐量对比
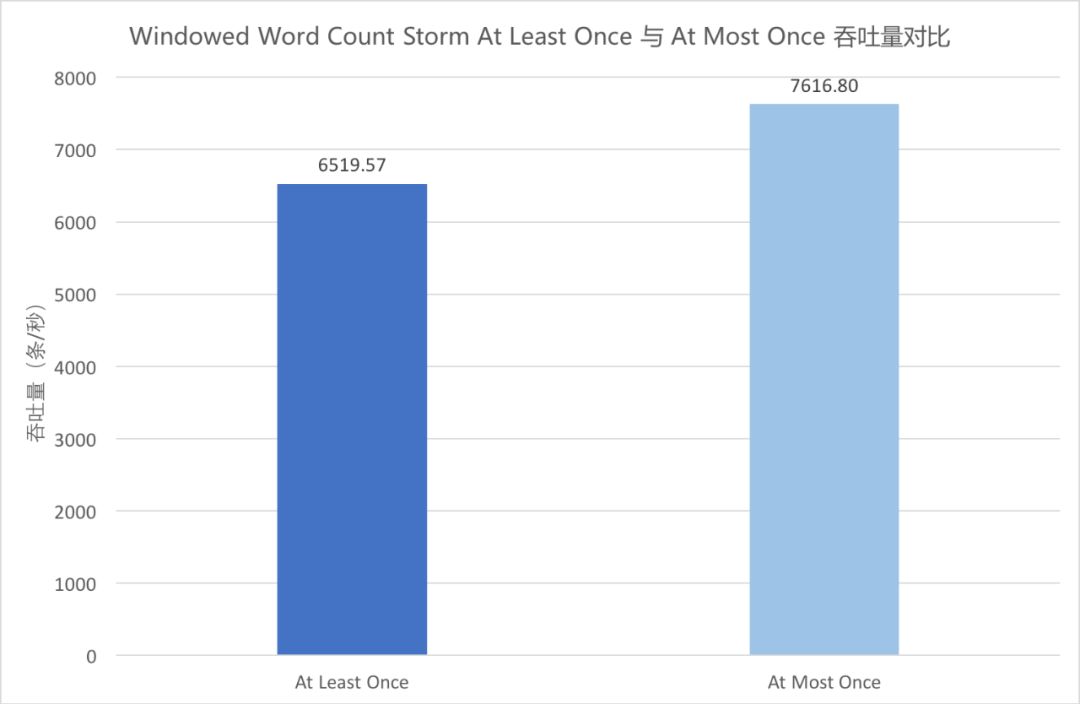
▲ Windowed Word Count Storm At Least Once 与 At Most Once 吞吐量对比
⑧ Windowed Word Count 单执行绪作业延迟

▲ Windowed Word Count 单执行绪作业延迟
⑨ Windowed Word Count Flink At Least Once 与 Exactly Once 延迟对比

▲ Windowed Word Count Flink At Least Once 与 Exactly Once 延迟对比
⑩ Windowed Word Count Storm At Least Once 与 At Most Once 延迟对比
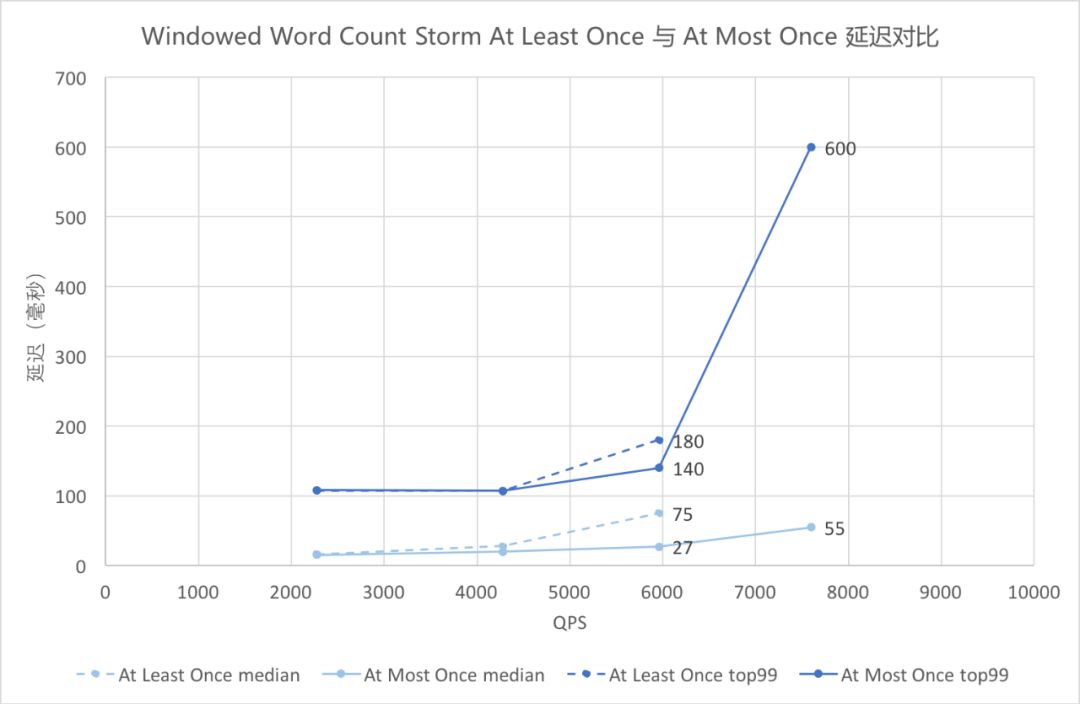
▲ Windowed Word Count Storm At Least Once 与 At Most Once 延迟对比
⑪Windowed Word Count Flink 不同 StateBackends 吞吐量对比

▲ Windowed Word Count Flink 不同 StateBackends 吞吐量对比
⑫Windowed Word Count Flink 不同 StateBackends 延迟对比

▲ Windowed Word Count Flink 不同 StateBackends 延迟对比
六、结论及建议
1、框架本身效能
2、复杂使用者逻辑对框架差异的削弱
3、不同讯息投递语义的差异
4、Flink 状态储存后端选择

5、推荐使用 Flink 的场景
综合上述测试结果,以下实时计算场景建议考虑使用 Flink 框架进行计算:
七、展望
>>>>参考资料
作者:梦瑶
来源:美团技术团队(ID:meituantech)
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:[email protected]


































