
防不胜防!现在, AI只需要听你的声音,就能知道你说话手势了。
这项“脑补力”Max的新研究,来自UC伯克利大学等机构,被今年的学术顶级会议CVPR 2019收录。
不信?看看美国知名脱口秀Last Week Night主持人Oliver就知道了,他的手势已经被AI研究透了。说话的时候,肩膀什么角度,手指如何挥动,预测得一清二楚。


看到这项研究之后,就有网友评论称,不知道它能不能预测川普的魔性手势?

也有人表示,还好这只是项研究,如果能够应用到现实中,那还了得?
以后打电话,一边在电话里说着爱对方,一边却搞著小动作,会暴露的。

手势,是人们在说话过程中自发发出的行为,用于补充语音资讯,来帮助更好地传递说话人的想法。
通常情况下, 说话的时候,手势与话语都是有关联的。但想要从话语中获取手势资讯,还需要学习音讯和手势之间的对映关系。在实践中,还有不少麻烦:
为了解决这些问题,研究人员提出了一种时间跨模态翻译的方法,采用端到端的方式将语音转换成手势,并使用了范围非常大的时间背景来进行预测,以此克服异步性问题。
他们建立了一个由10名说话人组成的144个小时的大型个人视讯资料集。为了体现出模型的适用范围,说话人的背景不尽相同:有电视节目主持人、大学教师和电视上的福音传道者。
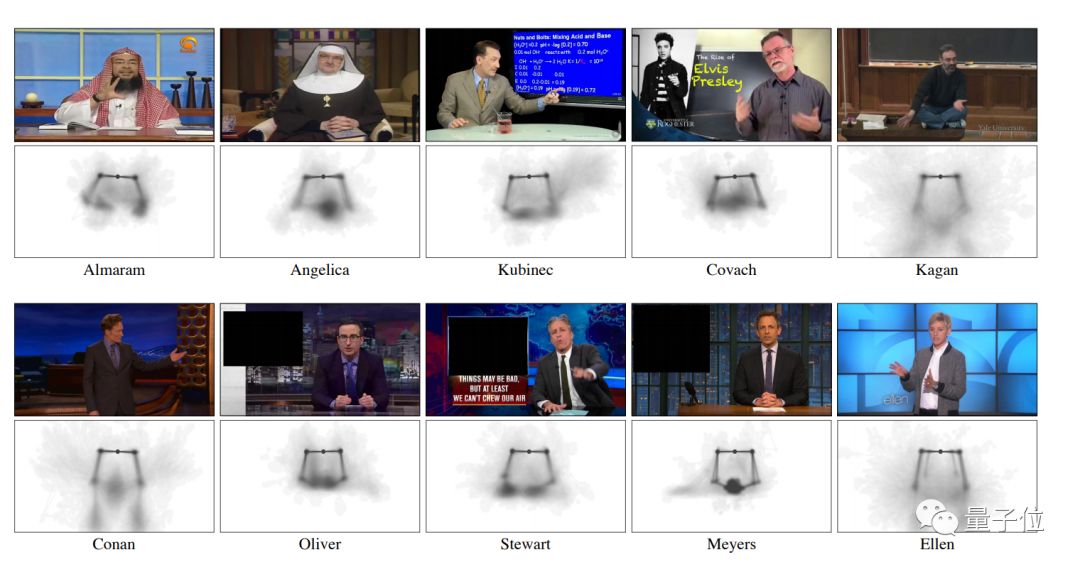

给定一段语音,通过翻译模型(G)预测说话人与话语匹配的手势动作(手和胳膊的运动)。
然后采用回归函式(L1)从资料中提出训练讯号,并通过度抗性鉴别器来确保预测的只是在时间上与话语是一致的,并符合说话人的风格。

整个卷积网络,由一个音讯编码器和一个1D UNet翻译架构组成。音讯编码器采用2D对数-梅尔频谱图作为输入,并通过一系列卷积对其进行下采样,从而产生与视讯取样率相同的1D讯号(15 Hz)。
UNet翻译架构随后通过L1回归损失学会将该讯号对映到手势向量的时间堆叠。
之所以使用UNet架构进行翻译,是因为它的瓶颈为网络提供了过去和未来的时间上下文,允许高频时间资讯流过,从而能够预测快速的手势运动。
虽然L1回归是从资料中提取训练讯号的唯一方法,但它存在回归均值的已知问题,这种回归均值会产生过度平滑的运动。为了解决这个问题,添加了一个以预测的姿态序列的差异为条件对抗性鉴别器。

这一研究的作者,大部分来自UC伯克利。
一作为Shiry Ginosar,UC伯克利计算机系的博士生。之前是人机互动领域的研究员,曾经在CMU计算机系做访问学者。
共同一作为Amir Bar,是一名生活在伯克利的机器学习工程师。目前,在Zebra Medical Vision工作,致力于提高医疗保健领域的效率。
他们在论文中说,这一研究是朝着对话手势的计算分析迈出的一步,之后也可以用于驱动虚拟任务的行为。
http://people.eecs.berkeley.edu/~shiry/speech2gesture/
https://github.com/amirbar/speech2gesture
小程式|全类别AI学习教程
AI社群|与优秀的人交流
喜欢就点“在看”吧 !


































