


 资料结构
资料结构
但凡IT江湖侠士,算法与资料结构为必修之课。早有前辈已经明确指出:程式=算法+资料结构 。要想在之后的江湖历练中通关,资料结构必不可少。资料结构与算法相辅相成,亦是阴阳互补之法。
 开篇
开篇
说道阵列,几乎每个IT江湖人士都不陌生,甚至过半人还会很自信觉的它很简单。 的确,在菜菜所知道的程式语言中几乎都会有阵列的影子。不过它不仅仅是一种基础的资料型别,更是一种基础的资料结构。如果你觉的对阵列足够了解,那能不能回答一下:
阵列的本质定义?
阵列的内存结构?
阵列有什么优势?
阵列有什么劣势?
阵列的应用场景?
阵列为什么大部分都从0开始编号?
阵列能否用其他容器来代替?
定义
所谓阵列,是相同的元素序列。阵列是在程式设计中,为了处理方便,把具有相同型别的若干元素按无序的形式组织起来的一种形式。
——百科
 正如以上所述,阵列在应用上属于资料的容器。不过我还是要补充两点:
正如以上所述,阵列在应用上属于资料的容器。不过我还是要补充两点:
1. 阵列在资料结构范畴属于一种线性结构,也就是只有前置节点和后续节点的资料结构,除阵列之外,像我们平时所用的伫列,栈,连结串列等也都属于线性结构。
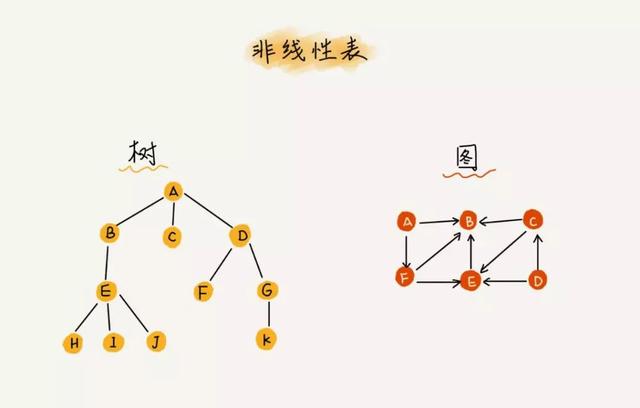
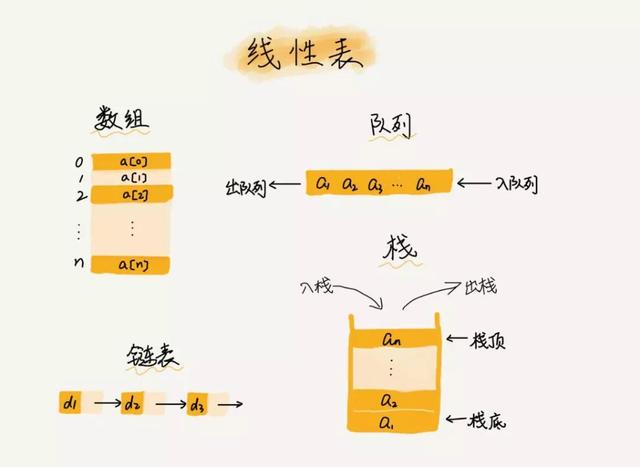 有线性结构当然就有非线性结构,比如之后我们要介绍的二叉树,图 等等,这里不再展开~~~
有线性结构当然就有非线性结构,比如之后我们要介绍的二叉树,图 等等,这里不再展开~~~
 2. 阵列元素在内存分配上是连续的。这一点对于阵列这种资料结构来说非常重要,甚至可以说是它最大的“杀手鐗”。下边会有更详细的介绍。
2. 阵列元素在内存分配上是连续的。这一点对于阵列这种资料结构来说非常重要,甚至可以说是它最大的“杀手鐗”。下边会有更详细的介绍。
优势和劣势
优势
我相信所有人在使用阵列的时候都知道阵列可以按照下标来访问,例如 array[1] 。作为一种最基础的资料结构是什么使阵列具有这样的随机访问方式呢?天性聪慧的你可能已经想到了:内存连续+相同资料型别。
现在我们抽象一下资料在内存上分配的情景。
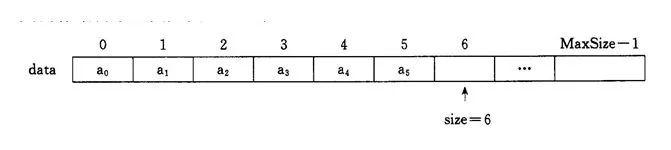 1. 说到阵列按下标访问,不得不说一下大多数人的一个“误解”:阵列适合查询元素。为什么说是误解呢,是因为这种说法不够准确,准确的说阵列适合按下标来查询元素,而且按照下标查询元素的时间复杂度是O(1)。为什么呢?我们知道要访问阵列的元素需要知道元素在内存中对应的内存地址,而阵列指向的内存的地址为首元素的地址,即:array[0]。由于阵列的每个元素都是相同的型别,每个型别占用的字节数系统是知道的,所以要想访问一个数组的元素,按照下标查询可以抽象为:
1. 说到阵列按下标访问,不得不说一下大多数人的一个“误解”:阵列适合查询元素。为什么说是误解呢,是因为这种说法不够准确,准确的说阵列适合按下标来查询元素,而且按照下标查询元素的时间复杂度是O(1)。为什么呢?我们知道要访问阵列的元素需要知道元素在内存中对应的内存地址,而阵列指向的内存的地址为首元素的地址,即:array[0]。由于阵列的每个元素都是相同的型别,每个型别占用的字节数系统是知道的,所以要想访问一个数组的元素,按照下标查询可以抽象为:
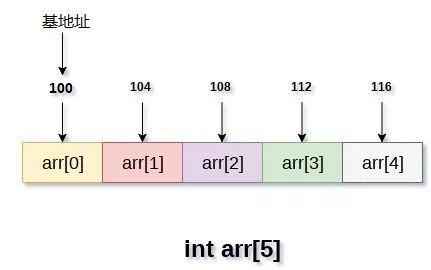
array[n]=array[0]+size*n
以上是元素地址的运算,其中size为每个元素的大小,如果为int型别资料,那size就为4个字节。其实确切的说,n的本质是一个离首元素的偏移量,所以array[n]就是距离首元素n个偏移量的元素,因此计算array[n]的内存地址只需以上公式。
 论证一下,如果下标从1开始计算,那array[n]的内存地址计算公式就会变为:
论证一下,如果下标从1开始计算,那array[n]的内存地址计算公式就会变为:
array[n]=array[0]+size*(n-1)
对比很容易发现,从1开始编号比从0开始编号每次获取内存地址都多了一次 减法运算,也就多了一次cpu指令的执行。这也是阵列从0下标开始访问一个原因。
其实还有一种可能性,那就是所有现代程式语言的鼻祖:C语言,它是从0开始计数下标的,所以现在所有衍生出来的后代语言也就延续了这个传统。虽然不符合人类的思想,但是符合计算机的原理。当然也有一些语言可以设定为不从下标0开始计算,这里不再展开,有兴趣的可以去搜索一下。
2. 由于阵列的连续性,所以在遍历阵列的时候非常快,不仅得益于阵列的连续性,另外也得益于cpu的快取,因为cpu读取快取只能读取连续内存的内容,所以阵列的连续性正好符合cpu快取的指令原理,要知道cpu快取的速度要比内存的速度快上很多。
劣势
1. 由于阵列在内存排列上是连续的,而且要保持这种连续性,所以当增加一个元素或删除一个元素的时候,为了保证连续性,需要做大量元素的移动工作。
举个栗子:要在阵列头部插入一个新元素,为了在头部腾出位置,所有的元素都要后移一位,假设元素个数为n,这就导致了时间复杂度为O(n)的一次操作,当然如果是在阵列末尾插入新元素,其他所有元素都不必移动,操作的时间复杂度为O(1)。
当然这里有一个技巧:如果你的业务要求并不是阵列连续有序的,当在位置k插入元素的时候,只需要把k元素转移到阵列末尾,新元素插入到k位置即可。当然仔细沉思一下这种业务场景可能性太小了,阵列都可以无序,我直接插入末尾即可,没有必要非得在k位置插入把。~~
当然还有一个特殊场景:如果是多次连续的k位置插入操作,我们完全可以合并为一次“批量插入”操作:把k之后的元素整体移动sum(插入次数)个位置,无需一个个位置移动,把三次操作的时间复杂度合并为一次。
与插入对应的就有删除操作,同理,删除算子组为了保持连续性,也需要元素的移动。
综上所述,阵列在新增和删除元素的场景下劣势比较明显,所以在具体业务场景下应该避免频繁新增和删除的操作。
2. 阵列的连续性就要求建立阵列的时候,内存必须有相应大小的连续区块,如果不存在,阵列就有可能出现建立失败的现象。在某些高阶语言中(比如c#,golang,java)就有可能引发一次GC(垃圾回收)操作,GC操作在系统执行中是非常昂贵的,有的语言甚至会挂起所有执行绪的操作,对外的表现就是“暂停服务”。
3. 阵列要求所有元素为同一个型别。在储存资料维度,它可能算是一种劣势,但是为了按照下标快速查询元素,业务中这也是一种优势。仁者见仁智者见智而已。
4. 阵列是长度固定的资料结构,所以在原始阵列的基础上扩容是不可能的,有的语言可能实现阵列的“伪扩容”,为什么说是“伪”呢,因为原理其实是建立了一个容量更大的阵列来存放原阵列元素,发生了资料复制的过程,只不过对于呼叫者而已透明而已。
5. 阵列有访问越界的可能。我们按照下标访问阵列的时候如果下标超出了阵列长度,在现代多数高阶语言中,直接就会引发异常了,但是一些低阶语言比如C 有可能会访问到阵列元素以外的资料,因为要访问的内存地址确实存在。
其他
很多程式语言中你会发现“纯阵列”并没有提供直接删除元素的方法(例如:c#,golang),而是需要将阵列转化为另一种资料结构来实现阵列元素的删除。比如在golang种可以转化为slice。这也验证了阵列的不变性。

 我们学习的每个资料结构其实都有对应的适合场景,只不过是场景多少的问题,具体什么时候用,需要我们对该资料结构的特性做深入分析。
我们学习的每个资料结构其实都有对应的适合场景,只不过是场景多少的问题,具体什么时候用,需要我们对该资料结构的特性做深入分析。
关于阵列的特性,通过以上介绍可以知道最大的一个亮点就是按照下标访问,那有没有具体业务对映这种特性呢?
1. 相信很多IT人士都遇到过会员机制,每个会员到达一定的经验值就会升级,怎么判断当前的经验是否到达升级条件呢?我们是不是可以这样做:比如当前会员等级为3,判断是否到达等级4的经验值,只需要array[4]的值判断即可,大多数人把配置放到DB,资源耗费太严重。也有的人放到其他容器快取。但是大部分场景下查询的时间复杂度要比阵列大很多。
2. 在分散式底层应用中,我们会有利用一致性杂凑方案来解决每个请求交给哪个服务器去处理的场景。有兴趣的同学可以自己去研究一下。其中有一个环节:根据杂凑值查询对应的服务器,这是典型的读多写少的应用,而且比较偏底层。如果用其他资料结构来解决大量的查询问题,可能会触碰到效能的瓶颈。而资料按下标访问时间复杂度为O(1)的特性,使得阵列在类似这些应用中非常广泛。

 ●程式猿修仙之路--算法之希尔排序!
●程式猿修仙之路--算法之希尔排序!
●程序员修仙之路--算法之插入排序!
●程序员修仙之路--算法之选择排序!

 转载是一种动力 分享是一种美德
转载是一种动力 分享是一种美德
 如果喜欢作者的文章,请关注“magiccodes”订阅号以便第一时间获得最新内容。本文版权归作者和湖南心莱资讯科技有限公司共有,欢迎转载,但未经作者同意必须保留此段宣告,且在文章页面明显位置给出原文连线,否则保留追究法律责任的权利。
如果喜欢作者的文章,请关注“magiccodes”订阅号以便第一时间获得最新内容。本文版权归作者和湖南心莱资讯科技有限公司共有,欢迎转载,但未经作者同意必须保留此段宣告,且在文章页面明显位置给出原文连线,否则保留追究法律责任的权利。
文件官网:docs.xin-lai.com
QQ群:
程式设计交流群
产品交流群



































