
针对不同的目标使用不同的损失函式。在本文中,我将通过一组示例向您介绍一些常用的损失函式。本文是使用Keras和Tensorflow框架的设计。
损失函式:简介
损失函式有助于优化神经网络的引数。我们的目标是通过优化神经网络的引数(权重)使其损失最小化。损失由损失函式计算。每个神经网络都给出了一些输出,我们通过将此输出与实际输出(目标值)相匹配来计算损失。然后使用梯度下降法来优化网络的权重,使这种损失最小化。这就是我们训练神经网络的方法。
均方误差(Mean Squared Error)
顾名思义,这种损失是通过计算实际(目标)值和预测值之间的平方差的平均值来计算的。
例如,有一个神经网络,它使用一些与房子相关的引数并预测它的价格。在这种情况下,您可以使用MSE损失。基本上,在输出是实数的情况下,应该使用这个损失函式。
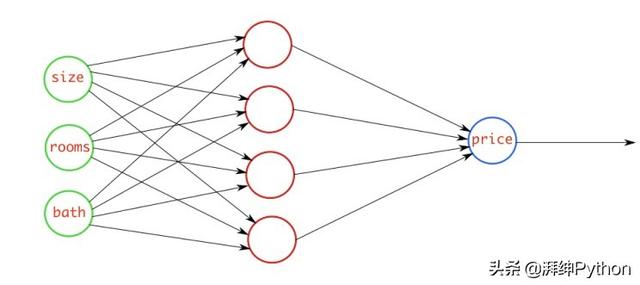 均方误差
均方误差
二元交叉熵(Binary Cross entropy)
当有一个二元分类任务时,如果使用BCEloss函式,则只需要一个输出节点将资料分类为两个类。输出值通过sigmoid启用函式,以便输出在(0-1)之间的范围内。
例如,有一个神经网络,它采用与大气相关的引数,并输出预测是否下雨。如果输出大于0.5,则网络将其分类为rain,如果输出小于0.5,则网络将其分类为not rain。(它可能是相反的,这取决于你如何训练网络)。概率得分值越多,下雨的概率就越大。
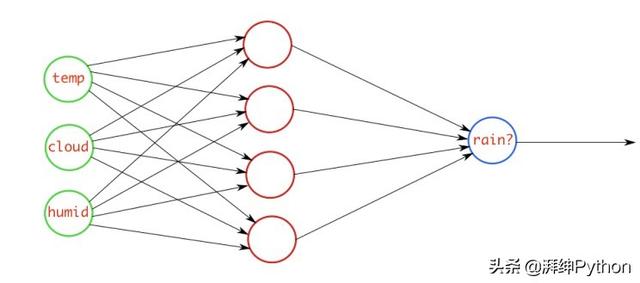 二元交叉熵
二元交叉熵
在训练网络时,如果下雨,则输入网络的目标值应为1,否则为0。
重要的是,如果使用BCE损失函式,节点的输出应在(0-1)之间。这意味着你必须在最终输出上使用sigmoid启用函式。因为sigmoid转换范围在(0-1)之间的任何实际值。
如果你不在最后一层使用sigmoid启用怎么办?然后,可以将一个名为from logitsas 的引数true传递给loss函式,它将在内部将sigmoid应用于输出值。
分类交叉熵(Categorical Cross entropy)
当有一个多类分类任务时,如果使用CCEloss函式,则输出节点的数量必须与类的数量相同。最后一层输出应通过softmax启用,以便每个节点输出范围在(0-1)之间的概率值。
例如,有一个神经网络,它识别影象并将其分类为猫或狗。如果猫节点具有高概率得分,则影象被分类为猫,否则为狗。基本上,无论哪个类节点的概率得分最高,影象将被分类到该类。
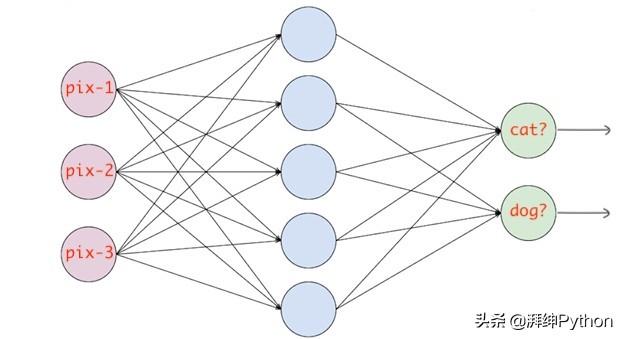 分类交叉熵
分类交叉熵
为了在训练时提供目标值,您必须对它们进行独热编码。如果影象是猫,则目标向量将是(1,0),如果影象是狗,则目标向量将是(0,1)。基本上,目标向量将相同大小的类的数量和索引位置对应于实际的类是1而所有其他的将为零。
如果在最后一层没有使用softmax启用怎么办?可以将一个名为from logitsas 的引数true传递给loss函式,它将在内部将softmax应用于输出值。与上述情况相同。
稀疏分类交叉熵(Sparse Categorical Cross entropy)
除了一个变化外,这个损失函式几乎与CCE相似。
当使用SCCE损失函式时,不需要对目标向量进行独热编码。如果目标影象是猫,则只需传递0,否则为1。基本上,无论哪个类,只需传递该类的索引。
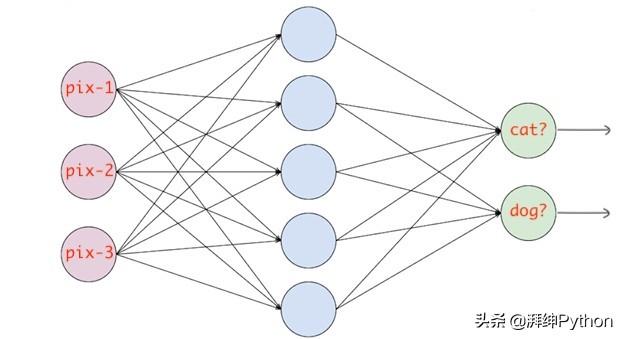 稀疏分类交叉熵
稀疏分类交叉熵
这些是最基本的损失函式。并且在训练神经网络时,您可能会使用其中一种损失函式。


































