
深度学习的初始化非常重要,这篇部落格主要描述两种初始化方法:一个是Kaiming初始化,一个是LSUV方法。文中对比了不同初始化的效果,并将每一种初始化得到的启用函式的输出都展示出来以检视每种初始化对层的输出的影响。当然,作者最后也发现如果使用了BatchNorm的话,不同的初始化方法结果差不多。说明使用BN可以使得初始化不那么敏感了。

本文翻译自Meidum的博文:How to initialize a Neural Network。部分连结丢失大家可以点选了解更多,里面会包含连结。
训练神经网络远非一项简单的任务,因为最轻微的错误导致非最佳结果而没有任何警告。训练取决于许多因素和引数,因此需要深思熟虑的方法。
众所周知,训练的开始(即前几次迭代)非常重要。 如果做得不当,你会得到不好的结果 - 有时候,网络根本就不会学到任何东西! 因此,初始化神经网络权重的方式是良好训练的关键因素之一。
本文的目的是解释为什么初始化会产生影响并提供不同的方法来有效地实现它。 我们将针对实际例子测试我们的方法。
程式码使用fastai库(基于pytorch)和最后一个fastai MOOC的课程(顺便说一句,这真的很棒!)。 所有实验笔记本都可以在这个github储存库中找到。
神经网络训练基本上包括重复以下两个步骤:
一个前向步骤,包括权重和输入/启用函式之间的大量矩阵乘法(我们称启用函式为一个层的输出,它将成为下一层的输入,即隐藏层的启用函式结果)反向传播步骤,包括更新网络权重以最小化损失函式(使用引数的梯度)在前向传播步骤中,启用函式(然后是梯度)可以很快变得非常大或非常小 - 这是因为我们重复了很多矩阵乘法。更具体地说,我们可能会得到:
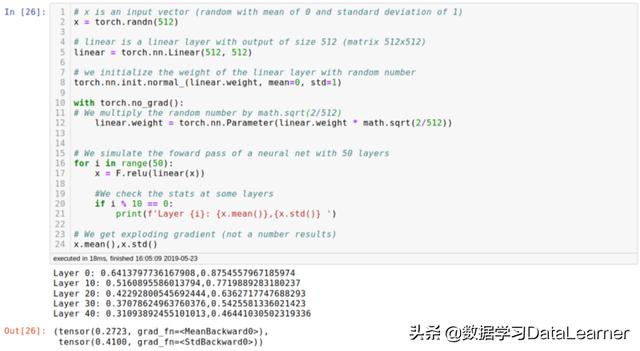
非常大的启用函式结果,趋向于无穷大非常小的启用函式结果,因此无穷小的梯度,根据数值精度可以趋近为零这些因素对任何一个训练都是致命的。下面是第一个前向传播随机初始化权重爆炸示例。

在这个特殊的例子中,平均值和标准偏差在第10层已经很大了!
让事情更棘手的是,在实践中,即使在避免爆炸或消失效果的情况下,经过长时间的训练,你仍然可能得到非最佳结果。 这在下面的简单报告中说明(实验将在本文的第二部分详述):

如何初始化您的网络
回想一下,良好初始化的目标是:
获得随机权重在第一次前向传播的时候将启用函式的结果保持在良好的范围内在实践中有什么好的范围? 定量地说,它意味着输出向量的平均值接近0并且标准偏差接近1。然后每个层将在所有层上传播这些统计量。
即使在深度网络上,您也可以在第一次迭代时获得稳定的统计资讯。
我们现在讨论两种方法。
数学方法:Kaiming初始化
让我们想象一下这个问题。如果初始化的权重在训练开始时太大,那么每个矩阵乘法将指数地增加启用函式结果,导致我们称之为梯度爆炸。
相反,如果权重太小,那么每个矩阵乘法将减少启用函式结果直到它们完全消失。
所以关键在于缩放权重矩阵以获得矩阵乘法的输出,其均值约为0,标准差为1。
但那么如何定义权重的比例呢?好吧,因为每个权重(以及输入)是独立的并且按照正态分布分布,我们可以通过计算一些数学来获得帮助。
两篇著名论文基于这个想法提出了一个很好的初始化方案:
“Xavier初始化”,2010年在论文“Understanding the difficulty of training deep feedforward neural networks”中提出2015年在“Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification”一文中提出的“Kaiming初始化”实际上,这两种方案非常相似:“主要”区别在于Kaiming初始化考虑了每次矩阵乘法后的ReLU启用函式。
如今,大多数神经网络使用ReLU(或类似leaky ReLU的函式)。在这里,我们只专注于Kaiming初始化。
简化公式(对于标准ReLU)是通过以下方式缩放随机权重(从标准分布中提取):

此外,所有bias引数都应初始化为零。
请注意,对于Leaky ReLU,公式有一个额外的部分,我们在此不考虑。
让我们看看这个方法在前面的例子中是如何工作的:
请注意,现在我们在初始化后得到平均值为0.64且标准偏差为0.87的启用函式结果。 显然,这不是完美的(如何用随机数?),但比正态分布的随机权重要好得多。
在50层之后,我们得到平均0.27和0.464的标准偏差,因此不再有爆炸或消失效果。
可选阅读:Kaiming公式的快速解释
Kaiming论文中提供了math.sqrt(2 /输入向量大小)的缩放数的数学推导。 另外,我们在下面提供了一些有用的程式码,读者可以完全跳过这些程式码继续下一部分。 请注意,程式码需要了解如何进行矩阵乘法以及方差/标准偏差。
为了理解公式,我们可以考虑矩阵乘法结果的方差是什么。 在这个例子中,我们有一个512向量,输出为512向量。

所以在我们的例子中,矩阵乘法输出的方差大约是输入向量的大小。 并且,根据定义,标准偏差是其平方根。
这就是为什么将权重矩阵除以输入向量大小的平方根(在本例中为512)给出了标准差为1的结果。
但“2”的分子来自哪里? 这只是考虑到ReLU层。
如您所知,ReLU将负数设定为0。 因此,因为我们的数字以均值0为中心,所以它基本上消除了一半的方差。 这就是为什么我们加上2的分子。
Kaiming初始化的缺点
Kaiming init在实践中表现很好,为什么还要考虑另一种方法呢? 事实证明,Kaming init存在一些缺点:
图层之后的平均值不是0而是大约0.5。 这是因为ReLU启用功能可以删除所有负数,从而有效地改变其均值Kaiming init仅适用于ReLU启用功能。 因此,如果你有一个更复杂的架构(不仅是matmult→ReLU层),那么这将无法在所有层上保持1左右的标准偏差层之后的标准偏差不是1但接近1。在深层网络中,这不足以使标准偏差始终接近1。算法方法:LSUV
那么,如果不为更复杂的架构手动定制Kaiming init,我们可以做些什么来获得良好的初始化方案?
论文所有你需要的是一个好的初始化,从2015年开始,展示了一种有趣的方法。 它被称为LSUV(层序单位方差)。
解决方案包括使用简单的算法:首先,使用正交初始化初始化所有层。 然后,进行小批量输入,并为每个层计算其输出的标准偏差。 将每一层除以产生的偏差,然后将其重置为1。以下是本文中解释的算法:

经过一些测试,我发现正交初始化给出的结果与在ReLU之前进行Kaiming初始化相似(有时甚至更差)。
在Fastai MOOC中,Jeremy Howard展示了另一种实现方式,它增加了权重的更新以保持平均值为0。在我的实验中,我还发现将平均值保持在0附近可以得到更好的结果。
def lsuv(layer, minibatch, model):
# Registering a hook to get the stat of the layer
stats = Hook(model, calculate_stats)
# The loop does a forward pass (model(minibatch)) while the mean of the output of the layer
# is not around 0
while model(minibatch) is not None and abs(stats.mean) > 1e-3:
# We subtract the mean of the output to the bias of the layer.
# It should push the mean of the output of the layer around 0.
layer.bias -= stats.mean
# The loop does a forward pass (model(minibatch)) while the standard deviation
# of the output of the layer is not around 1
while model(minibatch) is not None and abs(stats.std - 1) > 1e-3:
# We divide the weight of the matrix by the standard derivation of the output.
# It should push the standard derivation of the output of the layer around 1
layer.weight.data /= stats.std
# We remove the hook
stats.remove()
现在让我们比较这两种方法的结果。
初始化方案的效能
我们将在两种体系结构上检查不同初始化方案的效能:具有5层的“简单”convnet和更复杂的类似resnet的体系结构。
任务是对imagenette资料集(Imagenet资料集中的10个类的子集)进行影象分类。
简单的架构
这个实验可以在这个笔记本中找到。 请注意,由于随机性,每次结果可能会略有不同(但不会改变顺序和大图)。
它使用一个简单的模型,定义如下:

下面是3个初始化方案的比较:Pytorch预设的init(它是一个kaiming init但有一些特定的引数),Kaiming init和LSUV init。

请注意,随机init效能非常差,我们将其从后面的结果中删除。
init之后的启用统计资讯
第一个问题是第一次迭代的前向传播之后的启用统计资料是什么? 我们越接近平均值0和标准偏差1,它就越好。
该图显示了初始化(训练前)每层启用的统计资料。
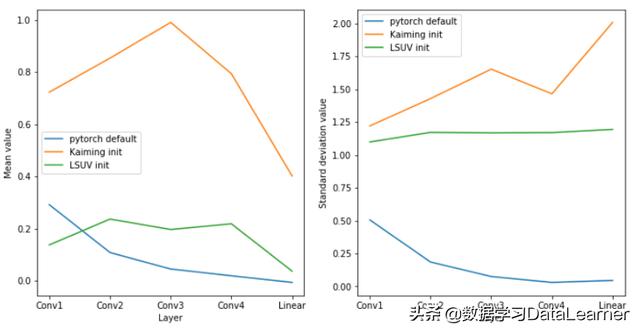
对于标准偏差(右图),LSUV和Kaiming init都接近1(并且LSUV更接近)。 但是对于pytorch预设值,标准偏差更低。
但是对于平均值,Kaiming init的结果更差。 这是可以理解的,因为Kaiming init没有考虑ReLU对平均值的影响。 所以平均值约为0.5而不是0。
复杂架构(resnet50)
现在让我们检查一下我们是否在更复杂的架构上得到了类似的结果。
该架构是xresnet-50,在fastai库中实现。 它比我们之前的简单模型多10倍。
我们将分两步检查:
没有规范化层:batchnorm将被禁用。 因为这个层将修改统计资讯,所以它应该减少初始化的影响使用标准化层:将启用batchnorm第1步:没有batchnorm
这个实验可以在这个笔记本中找到。
没有batchnorm,10个epoch的结果是:

该图显示LSUV的准确度(y轴)为67%,Kaiming初始化为57%,pytorch预设值为48%。 差异很大!
我们在训练前检查启用统计资料:

我们看到一些层的统计资料为0:它是由xresnet50设计的,并且与init方案无关。 这是 Bag of Tricks for Image Classification with Convolutional Neural Networks 论文中的技巧。
我们看到的是:
Pytorch预设初始化:标准差和均值接近于0.这不好并且显示消失的问题Kaiming init:我们得到了很大的均值和标准差LSUV init:我们获得了很好的统计资料,不完美,但比其他方案更好我们看到这个例子的最佳初始化方案为完整训练提供了更好的结果,即使在10个完整的epoch之后也是如此。 这表明在第一次迭代期间保持各层的良好统计资料的重要性。
第2步:使用batchnorm层
这个实验可以在这个笔记本中找到。
因为batchnorm会规范化层的输出,所以我们应该期望init方案的影响较小。

结果显示所有初始方案的准确性接近88%。 请注意,在每次执行时,最佳初始化方案可能会根据随机生成器而改变。
它表明batchnom层使网络对初始化方案不那么敏感。
训练前的启用统计资料如下:

像以前一样,最好的似乎是LSUV init(只有一个保持平均值在0左右,标准偏差接近1)。
但结果表明,这对准确性没有影响,至少对于这种架构和这个资料集而言。 它确认了一件事:batchnorm使网络对初始化的质量不太敏感。
结论
从这篇文章中记住什么?
第一次迭代非常重要,可以对完整的训练产生持久的影响。一个好的初始化方案应该在网络的所有层(第一次迭代)的启用上保持输入统计一致(平均值为0,标准差为1)。Batchnorm层降低了初始化方案的神经网络敏感度。使用Kaiming init + LSUV似乎是一种很好的方法,特别是当网络缺少规范化层时。其他型别的架构可能在初始化方面有不同的行为。原文地址:https://towardsdatascience.com/how-to-initialize-a-neural-network-27564cfb5ffc


































