
1 前文回顾
前篇《“少树”服从“多树”(上)》中系统介绍了单颗分类树算法。同时,我们指出分类树算法不够稳定,对训练样本资料比较敏感,造成其固有的方差,而方差又是预测误差的原因之一。为了有效降低方差,使用多颗分类树然后平均它们的结果作为最终的结果便成为一种自然的选择。在这方面,装袋算法(bagging)、提升算法(boosting)、随机森林(random forest)都是很好的方法。它们都是机器学习领域的集合学习元算法(ensemble learning meta algorithm)。元算法的意思是算法的算法;如果说算法的作用物件是资料,那么元算法的作用物件就是算法。它们可以理解为一种技术(technique),作用于基础分类算法上,以取得更佳的分类效果。本期就分别介绍并比较这三种技术。为了更好的介绍它们,首先来看一个名为自助抽样法的概念。
2 自助抽样法
2.1 可置换的重取样自助抽样法(bootstrapping)是指从给定的资料集中有放回的重取样或称为可置换的重取样(resampling with replacement)。在这个定义中,“可置换”是核心。什么是“可置换”呢?举个例子。假设我们有标号 1 到 10 的 10 个小球,放在一个袋子里。下面我们“可置换”地不断地从袋子里随机抽出小球。假设第一次抽取中,我们抽出了 3 号小球;“可置换”则是说我们在下一次抽取之前把 3 号小球放回到袋子里,即在第二次抽取的时候,我们仍然有可能再次抽到 3 号小球(它和其他 9 个球被抽到的概率是一样的),这便是可置换的含义。作为对比,生活中更多的是“无置换的抽取”,比如体彩 36 中 7 或者欧冠抽签,抽出的小球都不会再放回池子中。

2.2 随机生成大量不同的样本
让我们仍然考虑 10 个小球这个例子。假设我们有置换的从口袋里抽取 10 个球,得到一个小球序号的序列 3,5,6,1,1,7,9,10,2,6(即 1 号和 6 号球被取出两次;4 号和 8 号球没有被抽到)。这便是一个重取样得到的样本序列。通过进行大量的有置换的重取样,我们可以用原始的样本生成许多不同的新的样本序列。这么做的意义重大。
2,3 自助抽样的统计学意义
自助抽样的目的是帮助我们推断样本统计量(sample statistic)在估计总体统计量(population statistic)时的误差。比如我们想知道全世界所有人的平均身高(这个平均身高就是总体统计量,因为我们考虑的全世界所有人)。然而,我们不可能给全世界约 74 亿人都测量身高再计算平均值。因此,我们只能对一小部分样本进行分析。假设我们在全世界随机抽取了 5 万人、测量了这些人的身高,并计算出这 5 万人的平均身高为 1.72 米,这便是样本统计量。当我们用 1.72 米作为全世界总人口平均身高的估计时,我们无法回答这个估计是否准确、误差是多少。这是因为我们只有这一个 5 万人的样本;我们没有更多的其他的样本。这时,有置换的重取样便可大显身手。
具体的,我们可以把这 5 万人看作是原始资料,通过进行大量的有置换重取样(比如 10000 次),得到足够多的样本大小为 5 万人的不同的样本序列。这个分析方法的核心和巧妙之处是:我们暂时抛开那个真实的总体(74 亿人),而把这 5 万人就当作是我们分析的“总体”,并把经过有置换重取样得到的 10000 个样本作为基于这个 5 万人“总体”得到的“样本”。
通过计算这 10000 个"样本"的平均身高,得到“样本”平均身高的分布。由于“总体”就是那 5 万人;它的所有统计量都是已知的,因此我们可以准确地计算这 10000 个“样本”计算出的样本统计量在推断这 5 万人“总体”的总体统计量的误差,记为 e\'。更近一步,不要忘了这 5 万人其实是从那 74 亿人真实总体得到的一个真实样本。令 e 表示用这 5 万人样本的样本统计量推断 74 亿人总体的总体统计量时的误差。如果这 5 万人的概率分布是那 74 亿人的概率分布的一个合理的近似,那么我们就可以用 e\' 来估计 e。
我们想用一个已知样本 S 来推断总体 P 的未知概率分布 J。自助抽样法中,我们以该已知样本 S 为分析中的总体 P\',以重取样得到的新样本为分析中的样本 S\',使用 S\' 对总体 P\' 的经验分布 J\' 做推断。由于 P\' 是已知的,对 J\' 的统计推断的准确性可以确定。如果 J\' 是 J 的一个很好的近似,那么对 J 的统计推断的准确性也可以相应得到。
3 装袋算法
3.1 何为装袋算法装袋算法(bagging)由 Breiman (1996a, 1996b) 发明。Bagging 一词从英文 Bootstrap aggregating 而来,中文翻译为很拗口的引导聚类算法,为了好记又按 bagging 直译取名为装袋算法。为了理解它的含义,我们不用管那个中文翻译,只需要把这两个单词拆开来看:Bootstrap aggregating = Bootstrap + aggregate。前一个词就代表了上一节介绍的自助抽样,而后一个词就是聚合之意。它的意思是:
bootstrap:
通过对原始资料进行自助抽样得到许多新的样本资料,每个样本训练出一颗分类树,得到大量的分类树(这便是 bootstrap);aggregate:
对于新的待分类样本点,用这些分类树分别对其分类,然后把它们的结果按少数服从多数原则得到唯一的结果,该结果就是对这个新样本点最终的分类结果(这便是 aggregate)。3.2 装袋为什么有效
分类树本身是一种不稳定的分类器,对训练资料的敏感性比较高。训练资料的特征值的一些细微扰动可能造成分类树结构的不同,从而使得预测结果不同。这使得分类树的预测方差比较大。
一个分类算法的预测误差由偏差和误差两部分造成(具体的请参阅 Sutton 2005)。装袋算法通过聚合大量单一分类树可以有效的减少单一分类树的预测方差。诚然,聚合也会在一定程度上增加预测偏差,但增加幅度有限,可以被大大减少的方差所抵消。因此,对于分类树这种自身预测偏差较小,但是预测方差较大的分类器来说,装袋算法可以非常有效的提高其整体的预测准确性。
在实际应用中,Hastie et al. (2001) 指出使用 50 到 100 个重取样的样本便可以取得理想的结果(更多的样本也无法明显地进一步提升准确性)。上一篇中提到为了确定分类树的最佳尺寸,需要使用 K 折交叉验证,这意味着找到最优单颗分类树都需要一定的计算时间。然而,当我们采用装袋算法时,可以避免使用交叉验证。对于每一棵分类树,我们都可以使用原始的样本资料作为测试集来检验其准确性。又或者,我们可以通过计算袋外误差(out-of-bag error)来计算。计算袋外误差时,对于训练样本中的每一个点,使用所有那些用不包含该点的重取样样本所训练出的分类树对其分类(这就是袋外的意思),和该点的实际类别比较看看是否分类正确。平均所有样本点的分类正误便得到袋外误差。虽然装袋算法要计算许多分类树,但是由于它可以避免使用交叉验证,因此装袋算法的计算时间仍然是可接受的。
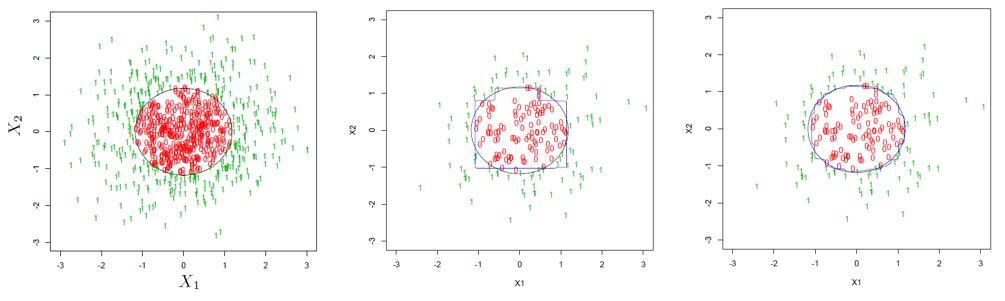
最后用下面这个例子直观的说明装袋法的好处。假设待分类的资料是二维平面上的点,每个点都可以用座标 (x1, x2) 表示。下图左一为所有点表示的总体,0 和 1 表示每一个点的分类,黑色的圆圈表示决策边界(decision boundary)。假设我们从总体中随机抽出 200 个点,并用它们来训练单一分类树,得到的分类决策边界如下图中间那副所示。可以看到该决策边界和真实的边界差别非常明显,这意味着这样一个分类树的分类误差是非常可观的。下图右一为使用了装袋算法后的结果。可以清楚的看到,我们的训练资料仍然还是那 200 个点,但是经过重取样再聚合,最后得到的决策边界比单一分类树的决策边界大大平滑了,更加贴近真实的决策边界,显著提升了分类准确性。
4 随机森林
随机森林(random forests)由 Breiman (2001) 提出,它和装袋算法非常类似,是装袋算法的进阶版。由前述可知,由于考虑了很多分类树,装袋算法本身已经是“森林”了。因此,随机森林和装袋算法的唯一差别就在“随机”两个字上。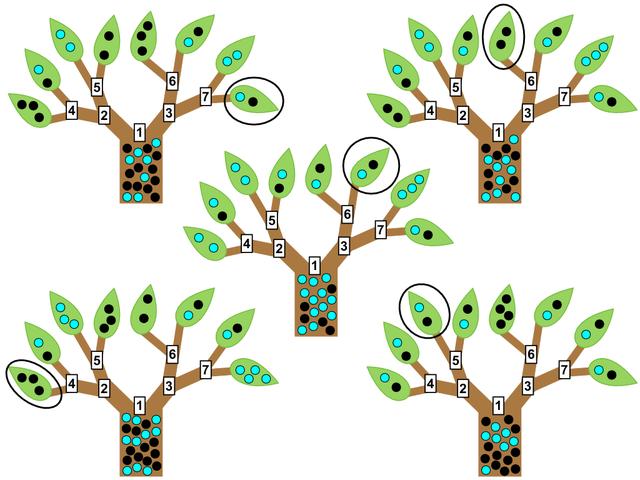
在装袋法中,不同的样本集都是通过对原始资料重取样得到的。因此,这些样本集——虽然它们之间有一定的差异——仍然是有很高的相关性的。在提出随机森林的时候,Breiman 证明了装袋算法的分类误差的上限是和样本集之间的相关性有关的。只有想办法降低样本集之间的相关性,才能进一步提高装袋法的效果。因此,他提出引入随机性。
具体的,随机森林算法在通过重取样构造大量样本集时和装袋算法并无差异。但是,在基于每个样本集训练分类树时,随机森林算法在分类特征选择时引入了随机性。该算法在选择当前的分类特征时,从所有的候选特征中先随机选出一个子集,然后再从该子集中选择出最好的分类特征。如果说装袋法仅仅考虑了样本的随机性,那么随机森林既考虑了样本随机性又考虑了特征随机性,从而降低了不同分类树之间的相关性。
5 提升算法
提升算法(boosting)的出发点是想回答这样一个问题,即一组“弱学习者”(week learners)能否通过集合学习生成一个“强学习者”(strong learner)?弱学习者一般是但不限于一个分类效果只比随机分类强一点点的分类器(因此单一分类树——虽然它有不错的分类效果——仍然也可以在作为弱学习者);强学习者指分类器的结果非常接近真值。因为算法把弱学习者变成强学习者,故得名提升算法。
Freund and Schapire (1996) 提出了 AdaBoost 算法,用于提升分类器的效果。它通过迭代,不断地对原始样本资料进行有权重的分类。在迭代中的每一步中,样本点的权重由上一步分类器的分类误差计算得到。因此,该算法在每次迭代时,都会增加错误分类样本点的权重,使得新的分类器更有可能正确地对这些错误点分类。
我们通过下面这个简单的例子来说明这个过程。假设我们的样本资料属于红蓝了两个不同的型别(如下图(1)所示)。首先我们赋予所有样本点等权重,并用一个(弱)分类器来进行分类,分类边界由虚线表示。可见,一个属于红色的样本和两个属于蓝色的样本被分类错误。在第二步迭代中,这三个点的权重被增大(其他点的权重相应被减小),然后进行第二次分类,得到新的分类边界(图(2))。这时,有两个蓝色的样本点被分类错误,因此在第三步迭代中,它们的权重被增大,然后进行第三次分类得到新的分类边界。继续重复这个过程直到迭代达到一定次数后,比如 M 次。对于任何一个新的待分类样本点,将这 M 个(弱)分类器按照它们各自的分类误差为权重进行加和,得到的结果就是对新样本点的分类结果。
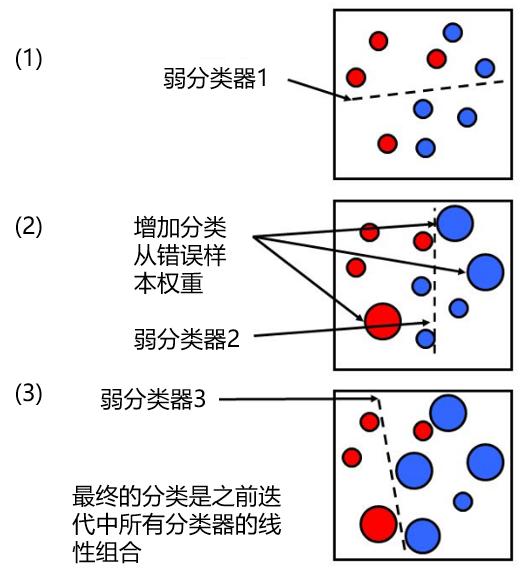
从上面的描述可知,在迭代的每一步,新的分类结果都会倾向于更正确地对之前分类错误的样本进行分类。这使得不同迭代步之间的分类边界有很大得差异,从而造成了不同分类结果之间的低相关性。这也是这个算法能够有效降低分类误差的原因。随机森林的发明者 Breiman 也提出了一种猜想,即 AdaBoost 可以被看作是一种特殊的随机森林。关于 AdaBoost 算法的具体数学表示式和流程,感兴趣的读者请参考 Freund and Schapire (1996)。
6 效果比较
毋庸置疑,装袋、随机森林、以及提升这三种元算法都大大改善了单一分类树的分类效果。就它们之间的比较来说,随机森林和提升法由于有效降低了不同分类树之间的相关性,它们的效果均优于装袋法。下图为装袋法和提升法在某分类问题上的误差比较。随着分类树个数的增加,它们的分类误差都逐渐收敛,但是提升法的误差要明显小于装袋法。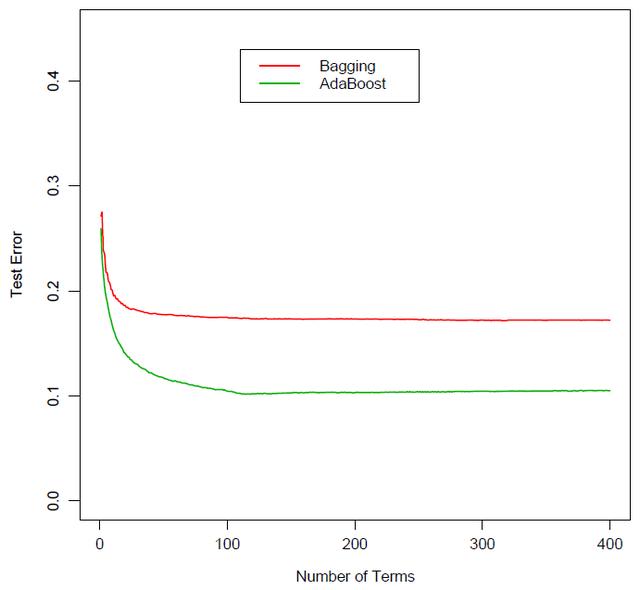
然而,随机森林和提升法孰优孰劣,并没有特别肯定的说法。一些学者认为提升法要优于随机森林,但是随机森林的发明者 Breiman 指出该方法要比提升法有更好的效果。从大量业界的实际分类问题的结果来看,这两个方法都是非常优秀的分类算法,它们的效果在很多问题上和神经网络以及支援向量机不相上下。
参考文献
Breiman, L. (1996a). Bagging predictors. Machine Learning, Vol. 24, 123–140.Breiman, L. (1996b). Heuristics of instability and stabilization in model selection. Ann. Statist., Vol. 24, 2350–2383.Breiman, L. (2001). Random forests. Machine Learning, Vol. 45, 5–32.Breiman, L., Friedman, J.H., Olshen, R.A., Stone, C.J. (1984). Classification and Regression Trees. Wadsworth, Pacific Grove, CA.Freund, Y., Schapire, R. (1996). Experiments with a new boosting algorithm. In: Saitta, L. (Ed.), Machine Learning: Proceedings of the Thirteenth International Conference. Morgan Kaufmann, San Francisco, CA.Hastie, T., Tibshirani, R., Friedman, J. (2001). The Elements of Statistical Learning: Data Mining, Inference, and Prediction. Springer-Verlag, New York.Sutton, C. D. (2005). Classification and Regression Trees, Bagging, and Boosting. In Rao, C. R., Wegman, E. J., Solka, J. L. (Eds.), Handbook of Statistics 24: Data Mining and Data Visualization, Chapter 11.


































