
无论是在Kaggle这类竞赛中,还是商业环境,决策树回归器都已经是最常用的机器学习演算法之一。决策树可用于分类和回归问题。本文介绍了决策树回归器演算法以及一些高阶话题。
目录

Photo by Todd Quackenbush / Unsplash-
简介
决策树可以用以下要点概括:
重要术语
在深入研究之前,让我们看一下决策树的基本术语:

它是如何工作的?
决策树通过向资料提出一系列问题来实现估计值,每个问题都会缩小可能值的范围,直到模型足够自信地进行单个预测。问题的顺序及其内容由模型决定。此外,提出的问题都是真/假的形式。
这有点难以掌握,因为它不是人类自然思考的方式,也许显示这种差异的最好方法是建立一个真正的决策树。在上述问题中X1,X2是两个特征,它们允许我们通过询问真/假来对目标变数y进行预测。

对于每个真/假的答案,都有单独的分支。无论问题的答案如何,我们最终都会实现一个预测(叶节点)。从顶部的根节点开始,然后在树中继续回答问题。所以给出任何一对X1,X2。
我应该提到的决策树的一个方面是它实际是如何学习的(如何形成\'问题\'以及如何设定阈值)。作为监督机器学习模型,决策树学习将资料对映到训练模型构建的输出上。
在训练期间,模型将拟合任何与问题域相关的历史资料,以及我们希望模型预测的真实值。该模型将学习资料和目标变数之间的关系。
在训练阶段之后,决策树产生类似于上图所示的树,计算最佳问题以及要求的顺序,以便能够进行最准确的估计。当我们想要进行预测时,应该向模型提供相同的资料格式。预测将是基于训练过的训练资料集产生估计值。
如何为决策树拆分决策
制定拆分的策略会严重影响树的准确性。对分类和回归树来说决策标准不同。决策树回归器通常使用均方误差(MSE)来决定将节点分成两个或更多个子节点。
假设我们正在做二叉树,演算法首先会选择一个值,然后将资料拆分为两个子集。对于每个子集,它将分别计算MSE。树将会选择具有最小MSE值的结果的值。
让我们来看一下Splitting如何决定决策树回归器的更多细节。建立树的第一步是建立第一个二元决策。你打算怎么做?
那么我们现在有:
这是建立决策树回归器的全部内容,并且当满足一些停止条件(由超引数定义)时将停止:
问答
是否有划分成3组的情况?
没有必要在一个级别上进行多次划分,因为您可以再进一步拆分它们。
它是如何进行预测的?
给定一个资料点,您可以在整个树中执行它,询问真/假,直到它到达叶节点为止。最终预测是该叶节点中因变数的值的平均值。
因为我们尝试了每个变数和每个变数可能的值来决策一个拆分。训练的计算成本会很高吗?
在这里,我们要记住,当今计算机的CPU效能是以千兆赫兹来衡量的,即每秒数十亿个时钟周期,它有多个核心,每个核心都有一个称为单指令、多资料(SIMD)的东西,它可以一次对每个核心进行8次计算。此外,如果您使用的是GPU,那么这个过程会更快,因为它的效能是以teraflops来衡量的,所以每秒要进行数万亿次浮点运算。所以,这就是设计演算法的地方,仅仅是人类很难意识到,考虑到当今计算机的速度有多快,演算法应该多么愚蠢。总而言之,有相当多的操作,但是每秒数万亿次的速度几乎注意不到。
每个节点的MSE计算哪个底层模型?
基础模型只是资料点的平均值。对于初始根节点,我们只是预测了所有训练资料点的因变数平均值。另一个可能的选择是不用平均数来使用中位数,或者我们甚至可以执行一个线性回归模型。我们可以做很多事情,但在实践中,平均值非常有效。它们确实存在在随机森林模型中,其中叶节点是独立的线性回归,但应用并不广泛。
给定相同的资料和超引数,深度为n的DT将包含深度为n-1的DT?
因此,如果我们建立一个深度为3的树和另一个我们摆脱最大深度的树,那么没有最大深度约束的树将包含深度为3的树。这假设资料和超引数将是相同的并且没有新增随机性(更深的树将包含不太深的树)。
什么时候不使用?
如前所述,如果提供给划分预测的资料与训练资料无关,决策树将无法做出准确的预测。让我们用一个例子来证明这个论点:
importnumpy asnp
importmatplotlib.pyplot asplt
fromsklearn.tree importDecisionTreeRegressor
x = np.linspace( 0, 1)
y = x + np.random.uniform( -0.2, 0.2,x.shape)
plt.scatter(x,y)

我们现在要构建一个决策树模型,这实际上是一个时间序列问题。所以我打算将左侧部分作为训练集。并将右侧部分作为我们的验证集。
# train, validation set split
x_trn, x_val = x[: 40, None], x[ 40:, None]
y_trn, y_val = y[: 40, None], y[ 40:, None]
# fit a model
m = DecisionTreeRegressor(max_depth= 6).fit(x_trn, y_trn)
请注意,决策树回归器期望二维阵列,而不是二维阵列中的一维阵列。

我们现在绘制结果:
plt.scatter(x_val,m.predict(x_val),color= \'blue\', label= \'Prediction\')
plt.scatter(x_val,y_val,color= \'red\', label= \'Actual\')
plt.scatter(x_trn,m.predict(x_trn),color= \'blue\')
plt.scatter(x_trn,y_trn,color= \'red\')
plt.legend(loc= \'upper left\')

如果您不知道决策树如何工作,那么这将使模型无用。换句话说,决策树和基于树的模型通常无法推断出他们以前从未见过的任何型别的资料,特别是未来的时间段,因为它只是平均它已经看到的资料。
简而言之,决策树和基于树的模型一般只做一个聪明的最邻近法。
在这种问题中,任何基于树的演算法都没有用,首选模型是神经网络或线性回归模型。原因是当你想要使用一个模型,而它有一个函式或者形状,它可以很好地进行外推。

决策树的一个主要缺点是它们容易过度拟合。这就是为什么很少使用他们,而是使用其他基于树的模型,如随机森林和XGBoost。
总之,决策树和通用基于树的模型是一种监督学习演算法(具有预定义的目标变数),主要用于分类问题。如上所述,当且仅当目标变数位于训练资料集中值的范围内时,它们才用于回归问题。
决策树的优缺点

优势
优势
避免过度拟合的技巧
通常,您可能会发现您的模型与资料过度匹配,这通常会在引入新资料时损害模型的效能。如果决策树没有限制集,它会在训练集上给你一个零MSE,因为在更糟的情况下,它最终会为每次观察生成一个叶子。因此,在训练决策树时,防止过度拟合非常重要,可以通过以下方式进行:
让我们简单地讨论这些方面。
这可以通过微调树的一些超引数来完成。首先,让我们看一下决策树的一般结构:

通过了解树建模中使用的引数的作用,可以帮助您在R&Python中更好地微调决策树。
节点拆分的最小样本
终端节点的最小样本(叶子)
树剪枝
如前所述,设定约束的技术是一种贪婪方法。换句话说,它将立即检查最佳划分并向前移动,直到达到指定的停止条件之一。
决策树演算法中出现的问题之一是最终树的最佳大小。太大的树存在过度拟合训练资料的风险,并且很难推广到新样本。小树可能无法捕获有关样本空间的重要结构资讯。但是,很难判断树演算法何时应该停止,因为无法判断新增单个额外节点是否会显著减少错误。这个问题被称为地平线效应。一种常见的策略是扩充套件树,直到每个节点包含少量例项,然后使用剪枝来删除不提供其他资讯的节点。
剪枝应该减小学习树的大小,而不降低交叉验证集测量的预测精度。在用于优化效能的测量中,有许多不同的剪枝技术。
最简单的剪枝形式之一是减少错误剪枝。从叶子开始,每个节点都用其平均值替换。如果MSE不受影响,则保留更改。虽然有点天真,但减少错误剪枝具有简单和迅速的优点。
使用随机森林
似乎没有多少人真正花时间去剪枝决策树或进行微调,而是选择使用随机森林回归器(决策树集合),它比单个优化树更不容易过度拟合,效能更好。
决策树与随机森林

在随机森林上使用决策树的常见论点是,决策树更容易解释,您只需检视决策树逻辑即可。然而,在一个随机森林中,您不需要研究500个不同树的决策树逻辑。
同时,随机森林实际上是决策树的集合,这使得演算法对于实时预测来说缓慢且无效。一般来说,RF可以快速训练,但是一旦训练开始就会很慢地建立预测。这是因为它必须对每棵树进行预测,然后进行平均以建立最终预测。(解决方法可以是同时使用不同树的丛集)
更准确的预测需要更多的树,这会导致模型变慢。在大多数实际应用中,随机森林演算法速度足够快,但在某些情况下,执行时效能是很重要的,所以会首选其他方法。
最后,决策树确实存在过度拟合问题,而随机森林可以防止过度拟合,从而在大多数情况下得到更好的预测。这是随机森林回归模型事实的一个显著优势,使其对许多资料科学家更具吸引力。
Sklearn决策树的超引数

min_samples_leaf :int,float,optional(default = 1)
它是我们上面讨论的终端节点的最小样本数。
min_samples_split:int,float,optional(default = 2)
max_features:int,float,string或None,optional(default =“auto”)
寻找最佳拆分时要考虑的特征数量:
max_depth :整数或无,可选(预设=无)
基于树的模型 VS 线性模型
实际上,您可以使用任何演算法。这取决于您要解决的问题型别。让我们看一些关键因素,它们将帮助您决定使用哪种演算法:
让我们用一个例子证明我们在第1点和第2点的论证:
importnumpy asnp
importmatplotlib.pyplot asplt
fromsklearn.tree importDecisionTreeRegressor
fromsklearn.linear_model importLinearRegression
plt.figure(figsize=( 20, 10))
x = np.linspace( 0, 2, 10000)
y = 1+ 3*x
plt.scatter(x,y)

我们现在要构建决策树和线性模型。我们期望线性模型完美拟合,因为目标变数与特征x线性相关。因此,我将对资料进行无序处理,将70%视为训练集,将30%视为验证。
idxs_train = sorted(np.random.permutation(len(x))[:int( 0.7*len(x))])
idx_test = [i fori inrange( 0,len(x)) ifi notinidxs_train]
# train, validation set split
x_trn, x_val = x[idxs_train, None], x[idx_test, None]
y_trn, y_val = y[idxs_train, None], y[idx_test, None]
# fit a model
dt = DecisionTreeRegressor(max_depth= 3).fit(x_trn, y_trn)
l = LinearRegression.fit(x_trn, y_trn)
请注意,两个模型都期望二维阵列。我们现在绘制结果:
plt.figure(figsize=( 20, 10))
plt.scatter(x,dt.predict(x[:,None]),color= \'blue\', label= \'Prediction DT\')
plt.scatter(x,l.predict(x[:,None]),color= \'green\', label= \'Prediction Linear\')
plt.scatter(x,y,color= \'red\', label= \'Actual\')
plt.legend(loc= \'upper left\')

在某种程度上,决策树试图适应 staircase。显然,在这种情况下,线性模型执行得很好,但在目标变数与输入特征不线性相关的其他情况下,DT将是更好的选择,因为它能够捕获非线性。另请参阅以下SciKit学习档案中的另一个示例:
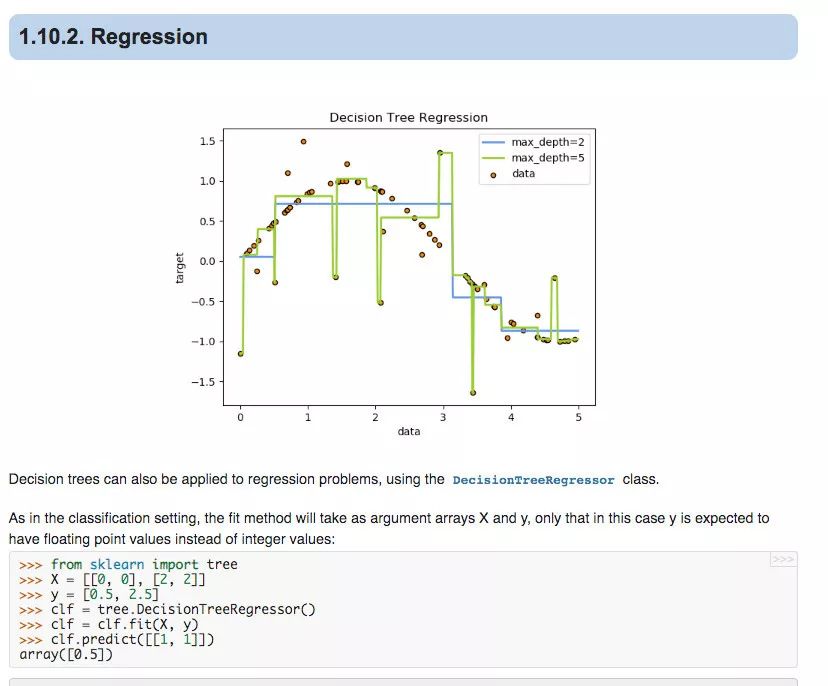
视觉化决策树模型
视觉化决策树非常简单。让我们绘制上面训练过的决策树。
fromsklearn.tree importexport_graphviz
importIPython, graphviz, re, math
然后我们可以简单地绘制决策树,如下所示:
defdraw_tree(t, col_names, size=9, ratio=0.5, precision=3):
""" Draws a representation of a random forest in IPython.
Parameters:
-----------
t: The tree you wish to draw
df: The data used to train the tree. This is used to get the names of the features.
"""
s=export_graphviz(t, out_file= None, feature_names=col_names, filled= True,
special_characters= True, rotate= True, precision=precision)
IPython.display.display(graphviz.Source(re.sub( \'Tree {\',
f\'Tree {{ size={size}; ratio={ratio}\',s)))
col_names =[ \'X\']
draw_tree(dt, col_names, precision= 3)
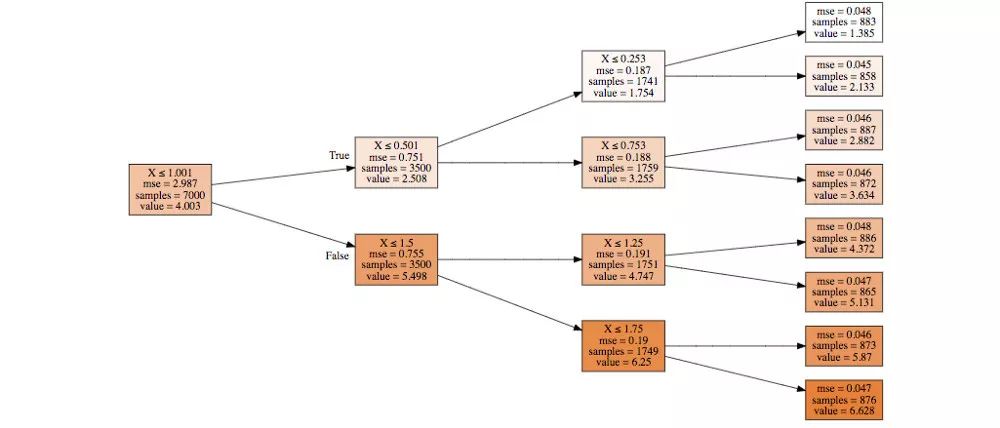
如您所见,我们正在获取资料的子集,并决定进一步划分子集的最佳方式。我们的初始子集是整个资料集,我们根据规则对其进行拆分X
结论
决策树是最广泛使用的机器学习模型之一,因为它们可以很好地处理噪声或丢失的资料,并且可以很容易地进行整合以形成更强大的预测器。此外,您可以直接看到模型的学习逻辑,这意味着它是一个非常受欢迎的模型,适用于模型可解释性很重要的领域。
感谢阅读,我期待着听到你的问题,敬请关注并快乐机器学习。
参考
https://scikit-learn.org/stable/modules/tree.html
https://en.wikipedia.org/wiki/Decision_tree_pruning
https://stackoverflow.com/questions/49428469/pruning-decision-trees
作者:Georgios Drakos
本文转载自: TalkingData资料学堂



































