
点选上方关注,All in AI中国

机器学习的一个重要部分是分类,我们想知道一个观察结果属于哪个分类(也就是组)。对观察结果进行精确分类的能力对于各种业务应用程序都非常有价值,比如预测特定使用者是否会购买产品,或者预测给定贷款是否会违约。
资料科学提供了大量的分类算法,如逻辑回归、支援向量机、朴素贝叶斯分类器和决策树。
在这篇文章中,我们将研究基本决策树是如何工作的,如何将个体决策树组合成一个随机森林,并最终发现为什么随机森林在它自己的领域十分如鱼得水。
决策树
让我们快速回顾一下决策树,因为它们是随机森林模型的构建块。幸运的是,它们非常直观。我敢打赌,大多数人在生活的某个时刻,都有意无意地使用过这个决策树。 简单决策树示例
简单决策树示例
我们通过一个例子来理解决策树的工作原理可能要容易得多。
假设我们的资料集由左上方的数字组成。我们有两个1和5个0(1和0是我们的类),并且希望使用它们的特性来分隔类。主要的特征是颜色(红色和蓝色)以及观察是否加下划线。那么我们怎么做呢?
颜色似乎是一个非常明显的特征,因为除了一个0以外,所有的0都是蓝色的。所以我们可以用"是不是红色"来分隔第一个节点。你可以将树中的节点视为路径分成两个部分的点,从而使满足条件的观察值沿着Yes分支向下,而不沿着No分支向下。
No分支(蓝色)现在都是0,所以我们已经完成了,但是Yes分支仍然可以被进一步分隔。现在我们可以使用第二个特性并询问:"它是否带下划线?"可第二次分隔。
带下划线的两个1向下到Yes子分支上,而没有下划线的0向下到右边的子分支上,这些我们都做完了。我们的决策树能够使用这两个特性来完美地分割资料。
显然,在现实生活中,我们的资料不会这么干净,但是决策树所使用的逻辑是相同的。在每个节点,它会问
什么特征将允许我以一种方式分割手头的观察结果,使得结果组尽可能彼此不同(并且每个结果子组的成员尽可能彼此相似)?
随机森林分类器
随机森林,顾名思义,由大量独立的决策树组成,它们作为一个整体执行。随机森林中的每棵树都有一个类预测,投票最多的类将成为我们模型的预测(见下图)。 预测随机森林模型的视觉化
预测随机森林模型的视觉化
模型之间的低相关性是关键。就像低相关性的投资(如股票和债券)如何组合在一起形成一个大于各部分之和的投资组合一样,不相关模型也可以产生比任何单个预测更准确的总体预测。产生这种奇妙效果的原因是,树木可以互相保护,避免各自的错误(只要它们不总是在同一个方向出错)。虽然有些树可能是错的,但是很多其他的树是对的,所以作为一个群体,这些树能够朝着正确的方向移动。因此,随机森林要想表现良好,其先决条件是:
我们的特性中需要有一些实际的讯号,这样使用这些特性构建的模型才能比随机猜测做得更好。单个树做出的预测(以及由此产生的误差)需要彼此之间具有较低的相关性。
这就是为什么不相关的结果如此之好
拥有许多不相关的模型的奇妙效果是一个非常重要的概念,因此我想向你展示一个示例来帮助你真正的理解它。想象一下,我们正在玩以下游戏:我用一个均匀分布的随机数发生器来产生一个数字。如果我生成的数大于或等于40,你赢了(所以你就有60%的机会赢),我付给你一些钱。如果低于40,我赢,你付给我同样的金额。现在我为你提供以下的选择。 我们可以:
游戏1: 玩100次,每次下注1美元。游戏2: 玩10次,每次下注10美元。游戏3: 玩一次,下注100美元。你会选哪一个?每款游戏的期望值相同:
第一场期望值= (0.60*1 + 0.40*-1)*100 = 20第二场期望值= (0.60*10 + 0.40*-10)*10 = 20第三场期望值= 0.60*100 + 0.40*-100 = 20 每个游戏10000个模拟结果的分布
每个游戏10000个模拟结果的分布
那分布呢?让我们用蒙特卡洛模拟视觉化结果(我们将对每种游戏型别执行10,000个模拟;例如,我们将模拟10000次游戏1)的100个玩法。尽管期望值是相同的,但结果分布从正的和窄的(蓝色)到二进位制(粉红色)大不相同。
游戏1(我们玩100次)提供了赚钱的最佳机会,在我执行的10,000个模拟中,97%的模拟都是赚钱的!对于游戏2(我们玩了10次),你在63%的模拟中赚钱,大幅下降(并且你的赔钱概率急剧增加)。而我们只玩了一次游戏3,你在60%的模拟中赚钱,正如预期的那样。

因此,即使游戏具有相同的期望值,它们的结果分布也完全不同。我们把100美元的赌注分成不同的部分越多,我们就越有信心赚到钱。如前所述,这是因为每个剧本都是独立于其他剧本的。
随机森林是一样的,每棵树就像我们之前游戏中的一棵树。我们发现我们玩的次数越多,赚钱的机会就越多。同样,对于随机森林模型,我们做出正确预测的机会随着模型中不相关树的数量增加而增加。
如果你想自己执行模拟游戏的程式码,你可以在我的GitHub上找到它。GitHub - yiuhyuk/coin_flip_game: Used to illustrate why bagging is effective
确保模型之间的多样化
那么,随机森林如何确保每棵树的行为与模型中其他树的行为不太相关呢?它使用了以下两种方法:Bagging (Bootstrap Aggregation)——决策树对它们所训练的资料非常敏感,且对训练集的微小更改可以导致明显不同的树结构。随机森林利用了这一点,允许每棵单独的树从资料集中随机抽取样本,并进行替换,从而生成不同的树。这个过程被称为bagging。
注意,使用bagging时,我们没有将训练资料细分为更小的块,而是在不同的块上训练每棵树。相反,如果我们有一个大小为N的样本,我们仍然向每棵树提供一个大小为N的训练集(除非另有说明)。但是我们没有使用原始的训练资料,而是随机抽取一个N大小的样本进行替换。例如,如果我们的训练资料是[1、2、3、4、5、6],那么我们可以给我们的树中的一个列表[1、2、2、3、6、6]。注意,这两个列表的长度都是6,并且"2"和"6"都在随机选择的训练资料中重复出现,我们将这些资料提供给我们的树(因为我们使用替换抽样)。
 随机森林模型中的节点分裂基于每棵树的随机特征子集
随机森林模型中的节点分裂基于每棵树的随机特征子集
特征随机性——在一个普通的决策树中,当需要分割一个节点时,我们考虑每一个可能的特征,并选择一个在左节点和右节点的观察结果之间产生最大分离的特征。相反,随机森林中的每棵树只能从特征的随机子集中选取。这使得模型中的树之间的差异更大,最终导致树之间的相关性更低,多样性更强。
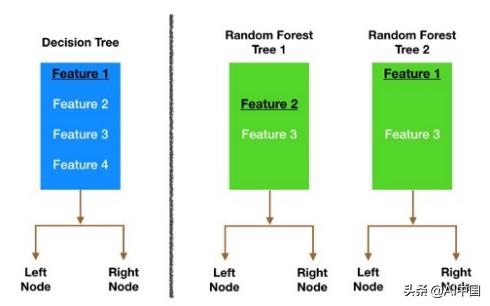
让我们来看一个视觉化的例子,在上面的图中,传统的决策树(蓝色)在决定如何分割节点时可以从所有四个特性中进行选择。它决定使用Feature 1(黑色和下划线),因为它将资料分割成尽可能分离的组。
现在我们来看看随机森林。在本例中,我们将只研究森林中的两棵树。当我们检验随机森林树1时,我们发现它只能考虑feature 2和feature 3(随机选择)来进行节点分割决策。我们从传统的决策树(蓝色)中知道,Feature 1是用于分割的最佳特性,但是树 1不能看到Feature 1,因此它只能选择Feature 2(黑色,下划线)。另一方面,树2只能看到特性1和特性3,因此它能够选择Feature 1。
因此,在我们的随机森林中,我们得到的树不仅针对不同的资料集进行训练(多亏了bagging),而且还使用不同的特性来做出决策。
所以,这就建立了不相关的树来缓冲和保护彼此不受错误的影响。

结论
随机森林是我个人的最爱。因为来自金融和投资领域的圣杯,总是建立一堆不相关的模型,每个模型都有正的预期回报,然后把它们放在一个投资组合中,获得巨大的alpha(alpha =市场跳动回报)。说起来容易做起来难!随机森林是资料科学的等价物。让我们最后复习一次,什么是随机森林分类器?
随机森林是一种由许多决策树组成的分类算法。在构建每棵单独的树时,它使用bagging和特征随机性,试图建立一个不相关的树的森林,委员会的预测比任何单独的树都准确。
为了让我们的随机森林做出准确的类预测,我们需要什么?
我们需要至少具有一定预测能力的特性。毕竟,如果我们把垃圾放进去,我们就会把垃圾拿出来。森林中的树木以及更重要的是,它们的预测需要不相关(或者至少彼此之间的相关性较低)。虽然算法本身通过特征随机性试图为我们设计这些低相关性,但是我们选择的特征和我们选择的超引数也会影响最终的相关性。































