
强化学习的历史主要沿两条主线发展而来,第一条主线是心理学上模仿动物学习方式的试错法,第二条主线是求解最优控制问题。两条主线最初是独立发展的。心理学上的试错法从20世纪50年代末、60年代初贯穿了人工智能的发展,并且一定程度上促进了强化学习的发展。20世纪80年代初期,试错法随着人工智能的热潮而被学者们广泛研究。而求解最优控制法则是利用动态规划法求解最优值函式。到20世纪80年代末,基于时间差分法求解的第三条主线开始出现。时间差分法吸收了前面两条主线的思想,奠定了现代强化学习在机器学习领域中的地位。强化学习具体的历史事件阶段节点如表1.1所示。
表1.1 强化学习中有影响力的算法的出现时间
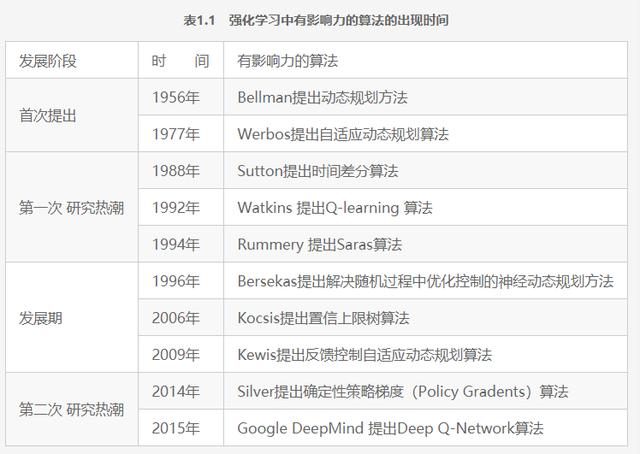
强化学习历史的第一条主线是试错法。试错法是以尝试和错误学习(Trial-and-Error Learning)为中心的一种仿生心理学方法。心理学家Thorndike发表的“效应定律”(Law of Effect)描述了增强性事件对动物选择动作倾向的影响,该定律定义了如何累积生物的学习资料(例如奖罚之间的相互关系)。而在这之后很长一段时间内,如何在生物的学习过程中累积其学习资料,心理学家和科学家们产生了巨大的分歧和争议。甚至在很长一段时间内,部分学者很难区分强化学习和无监督学习之间的区别。
在试错学习中,比较有代表性的是20世纪60年代初Donald Michie的相关研究工作。Michie描述了如何使用一个简单的试错系统进行井字游戏。1968年,Michie又使用试错系统进行一个增强型的平衡杆游戏,该游戏包括两部分:一个是强化学习的学习者GLEE(游戏学习经验引擎),另一个是强化学习的控制者BOXES。Michie的基于试错法的平衡杆游戏是有关强化学习免模型任务的最早例子,该例子对后续Sutton等人的工作产生了一定的影响。
强化学习历史的第二条主线是最优控制。在20世纪50年代末,“最优控制”主要用来描述最小化控制器在动态系统中随着时间变化的行为问题。在20世纪50年代中期,Richard Bellman等人扩充套件了汉弥尔顿和雅可比的理论,通过利用动态系统中的状态资讯和引入一个值函式的概念,来定义“最优返回的函式”,而这个“最优返回的函式”就是求解强化学习通用正规化的贝尔曼方程。贝尔曼通过求解贝尔曼方程来间接解决最优控制问题,此方法后来被称为动态规划(Dynamic Programming)法,并且使用马尔可夫决策过程描述最优控制的过程。时隔不久,在1960年,Ronald Howard提出了策略迭代求解马尔可夫决策的过程。上面提到的两位数学家Richard Bellman和Ronald Howard所提出的理论都是现代强化学习理论和算法的基础要素。
虽然贝尔曼后来提出了使用动态规划去解决最优控制问题,但仍会遇到“维度灾难”问题,这意味着在计算资源极度匮乏的年代,计算需求随着状态数目的增加而呈指数增加的动态规划法难以被大规模实际应用。可是大家仍然认为解决一般随机最优控制问题的唯一方法是动态规划法,因为该方法相对其他算法更加快速、有效。
强化学习历史的第三条主线是时间差分法。跟前两条主线不同,时间差分法虽然是在20世纪80年代末提出的,但是却在免模型的强化学习任务中扮演着重要的角色。时间差分法这一概念可能最早出现在Arthur Samuel的西洋陆棋游戏程式中。
Sutton关于时间差分法的研究主要受到动物学习方式的理论和Klopf研究的影响。1981年,Sutton突然意识到以前研究者的大量工作实际上都是时间差分和试错法的一部分。于是Sutton等人开发了一种新的强化学习框架——演员-评论家架构,并把该方法应用在Michie和Chambers的极点平衡问题中。1988年,Sutton将时间差分中的策略控制概念分离,并将其作为强化学习的策略预测方法。
时间差分法对强化学习影响最显著的标志是在1989年Chris Watkins等人发表了Q-learning算法,该算法成功地把最优控制和时间差分法结合了起来。在这个时间节点之后,强化学习再一次迎来发展高峰期,Watkins等人使得强化学习在人工智能、机器学习、神经网络领域都取得了快速进步。最为著名的是Gerry Tesauro使用TD-Gammon算法玩西洋双陆棋游戏时赢得了最好的人类玩家,这使得强化学习引起了大众和媒体的广泛关注。但在这之后,随着其他机器学习算法的大量出现并在实际应用中表现优异,如PageRank、K-means、KNN、AdaBoost、SVM、神经网络等,而强化学习因为缺少突破性的研究进展,又慢慢地跌入研究的低谷。
直到2013年,结合强化学习和神经网络的深度强化学习的出现,使得强化学习再一次高调地进入大众的视野,也迎来了强化学习的第二次研究热潮。实际上,强化学习的基本学习方法是利用时间差分学习的例项,通过值函式、策略、环境模型、状态更新、奖励等讯号,利用逼近函式的方法来实现对应的算法。而深度学习则是近年来函式逼近模型中最具有代表性、最成功的一种算法。Google收购了DeepMind之后,DeepMind使用深度强化学习Deep Q-Network进行Atari游戏,并在许多Atari的游戏中获得了相当惊人的成绩。在这之后,DeepMind又开发出了AlphaGo围棋程式,一举战胜了人类围棋的天才柯洁和李世石。
虽然深度学习模型有其特定的问题,例如网络模型容易过拟合、网络模型需要大量的资料进行表征学习,但是这并不能说明类似于深度学习的监督式学习方法不适用于大规模应用或者与强化学习结合。DQN算法首次将深度学习与强化学习结合,开创了新的机器学习分支——深度强化学习。深度学习和强化学习这两种学习方式在近年来得到了长足的进步,相信读者也很清楚AlphaGo围棋算法和Google推出的关于深度学习的TensorFlow框架。
我们有理由相信,深度学习和强化学习的结合体——深度强化学习是人工智能的未来之路。智慧的系统必须能够在没有持续监督讯号的情况下自主学习,而深度强化学习正是自主学习的最佳代表。人工智能系统必须能够自己去判断对与错,而不是主动告诉系统或者通过一种监督模拟的方法实现,相信如深度强化学习式的自主学习方式能够给人工智能带来更多的发展空间与想象力。































