
引 言
上一篇推文《什么是多因子量化选股模型?》主要介绍了多因子模型产生的理论背景、基本原理和实现步骤,而《【手把手教你】Python量化Fama-French三因子模型》则对国内A股市场的三因子模型进行了实证分析。多因子量化模型研究的物件主要是因子,因此单因子的回测和有效性检验是整个多因子模型的重要组成部分。本文结合Python开源包Alphalens,以A股市场真实场景资料,手把手教你对单因子进行量化回测。Alphalens是Quantopian公司(美帝最大的量化回测平台之一,国内几个基本上都是仿他们家的)三大知名Python开源包之一,其他两个分别是Zipline(策略回测,一直没安装成功)和Pyfolio(策略分析)。Alphalens主要提供因子收益分析、因子IC分析、因子换手分析和事件研究等回测框架,由于简单易上手和科学稳定等优点,是量化分析师最常用的回测工具包之一。资料预处理
资料预处理是使用Alphalens做单因子回测的最主要工作,包括获因子资料,资料归一化和异常值处理等,将原始资料整理成符合要求的格式后,后面的分析就变得很简单,基本上都是一行程式码搞掂。本文以市盈率(PE)指标为例,使用tushare的每日指标界面(daily_basic)获取A股市场3000多只股票2011-2019年收盘价和市盈率资料,为大家展示如何使用alphalens做单因子的历史回测。
#先引入后面可能用到的包(package)
import alphalens #使用pip安装即可
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
#正常显示画图时出现的中文和负号
from pylab import mpl
mpl.rcParams[\'font.sans-serif\']=[\'SimHei\']
mpl.rcParams[\'axes.unicode_minus\']=False
#还是使用tushare获取资料
import tushare as ts
token=\'输入token\'
pro=ts.pro_api(token)
#获取当前交易的股票程式码和名称
def get_code():
df = pro.stock_basic(exchange=\'\', list_status=\'L\')
#剔除2017年以后上市的新股次新股
df=df[df[\'list_date\'].apply(int).values #剔除st股
df=df[-df[\'name\'].apply(lambda x:x.startswith(\'*ST\'))]
codes=df.ts_code.values
return codes
df=pro.daily_basic(ts_code=get_code()[0],start_date=\'20110101\')
for code in get_code()[1:]:
df1=pro.daily_basic(ts_code=code,start_date=\'20110101\')
df=pd.concat([df,df1])
df_new=df.loc[:,[\'ts_code\',\'trade_date\',\'close\',\'pe_ttm\']]
df_new.loc[:,\'trade_date\']=pd.to_datetime(df_new.trade_date)
#设定双重重索引的资料格式
df_new=df_new.set_index([\'trade_date\',\'ts_code\'])
#根据第一索引排序
df_new=df_new.sort_index()
#检视资料前几行
df_new.head()

其中,pe_ttm是动态市盈率,是本文重点考察的单因子,资料预处理的第一步是建立以日期、股票程式码的双重索引,如上表所示。先来看下全市场收盘价和市盈率的描述性统计,市盈率有440万个观测值(删除了市盈率为负的观测值),均值为206,标准差高达12698,最大值为2653832,而75%分位数才77.3,可见均值受极端值影响很大,有必要对原始资料进行归一化和缩尾处理。factor_new是处理后的因子资料。prices是收盘价资料(前复权),必须转化为日期为索引,列名是相应股票程式码或名称格式的资料形式。

df_new.describe().round(2)#对资料进行缩尾处理,并进行标准化
def winsor_data(data):
q=data.quantile([0.02,0.98])
data[data data[data>q.iloc[1]]=q.iloc[1]
return data
#资料标准化
def MaxMinNormal(data):
"""[0,1] normaliaztion"""
x = (data - data.min()) / (data.max() - data.min())
return x
factor=df_new[\'pe_ttm\'].groupby(\'trade_date\').apply(winsor_data)
factor_new=factor.groupby(\'trade_date\').apply(MaxMinNormal)
factor_new.hist(figsize=(12,6),bins=20)

prices=df_new[\'close\'].unstack()
prices.head()

alphalens库所用到是函式名称都非常长,其中资料预处理函式是get_clean_factor_and_forward_returns,要想了解函式的详细引数可以输入help(函式名),这里不考虑分组(行业),其他引数均使用预设,factor_new为因子资料,prices为收盘价资料,quantiles=10表示将资料分成10个分位数进行考察,period是调仓周期,10,20,60,表示分布考察10、20、60日调仓情况。进行到这一步,表明资料清洗工作已完成,下面主要围绕单因子的收益率、资讯比率和换手率进行回测和分析。
data=alphalens.utils.get_clean_factor_and_forward_returns(factor_new,prices,
quantiles=10,periods=(10,20,60))
data.head()

收益率分析Returns Analysis
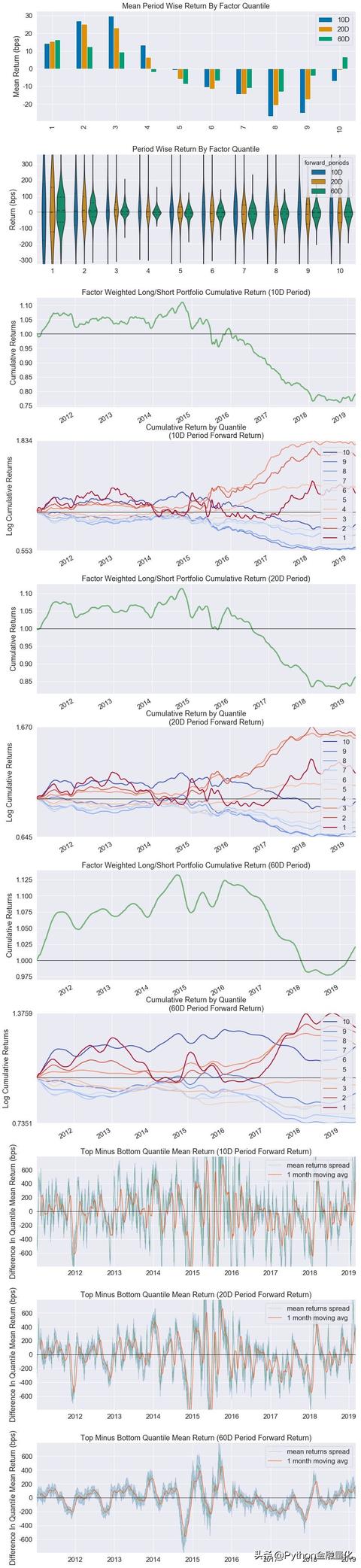
单因子的收益率分析主要围绕10、20、60日(可自己设定)调仓周期,将因子资料从小到大排列,分为10个分位数进行回测,一行程式码便可实现,但函式名称实在太冗长了。第一张表报告了不同调仓期的alpha、beta、高分位(top quantile)和低分位(bottom quantile)的收益情况。柱状图清晰地显示出该因子(市盈率)随着分位的提高收益由正转负,可见市盈率因子与股票收益存在一定的反向关系,即市盈率越小,未来收益越高,与理论和直觉基本一致。小提琴图是多收益率的分布,60日调仓的收益更加集中,方差更小,收益率更加可信。 由于对因子进行了归一化化处理,因此可以以因子值为权重构建一个全市场的股票组合进行回测。对于cumulative return by quantile的评价标准是累计收益率是否发散,越发散越好,说明因子的区分度越高,60天调仓期出现了明显的发散。好的讯号:波动小,在某一个方向的占比处于绝对地位,如大部分的Top minus bottom都是正的。alphalens.tears.create_returns_tear_sheet(data)

资讯分析 Information analysis
资讯分析说白了是考察IC和IR指标。IC全称为Information Coefficient, 即资讯系数,代表因子预测股票收益的能力。其原理是通过计算全部股票在调仓周期期初排名和调仓周期期末收益排名的线性相关度(correlation)。 不难理解,IC绝对值越大的因子,选股能力越强。IC的值在[-1,1]区间内,最大值为1,表示该因子100%准确,对应的是排名分最高的股票,选出来的股票在下个调仓周期中,涨幅最大;相反,如果IC为-1,则代表排名最高的股票,在下个调仓周期中,涨幅最大,是一个完全反向指标,也是非常有意义的,使用的时候反向操作即可。一般而言,当IC的绝对值0.05时,因子选股能力有一定的意义,当IC大于0.5时因子稳定获取超额收益能力较强。IR全称是Information Ratio,等于IC的多周期均值/IC的标准差,或等于超额收益均值/超额收益标准差,代表因子获取稳定Alpha的能力。 整个回测时段由多个调仓期组成,每一个周期都会计算出一根不同的IC值,IR等于多个调仓周期的IC均值除以IC的标准差。因此IR兼顾了因子的选股能力和因子选股能力的稳定性,IR值越大越好。
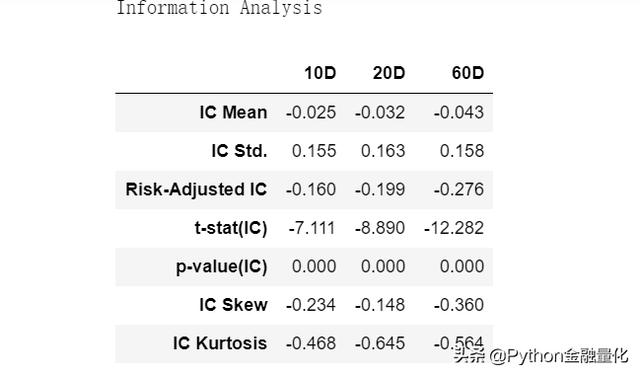
information analysis表给出了每个调仓周期下,IC的均值、方差以及t统计量,还有偏度、峰度以及年化的IR。因子资讯分析好的评判标准是:IC的均值较高,方差小,而t统计量大(一般大于2)或p-value小(一般小于5%)。从结果上看,PE因子的IC均值都比较小,看来不是很理想的选股因子偏度和峰度主要考察和正态分布的偏离程度,主要用于分析小概率事件的影响。
alphalens.tears.create_information_tear_sheet(data)

Q-Q plot图是检视样本分布与正态分布的对比情况,如果满足正态分布,Q-Q图上的点应该在y=x上。虽然有些IC的取值挺大的,但是尾部比较大,均值大是由于极度的尖峰和右偏造成的。还需具体考察IC的分布来决定一个因子的预测能力是不是可靠。
热力图提供了不同时间段因子的预测能力表现,有利于进行因子的情景分析。通过热力图我们可以轻易识别哪些时间段IC值比较好,哪些时间段IC比较差,有没有突发的情况,然后可以对此进行情景分析。
ic=alphalens.performance.mean_information_coefficient(data,by_time=\'1y\')
from pyecharts import Bar
attr=ic.index.strftime(\'%Y\')
v1=list(ic[\'10D\'].round(2))
v2=list(ic[\'20D\'].round(2))
v3=list(ic[\'60D\'].round(2))
bar=Bar(\'IC均值:2006-2019\')
bar.add(\'10D\',attr,v1)
bar.add(\'20D\',attr,v2)
bar.add(\'60D\',attr,v3)
bar

因子换手率 Turnover analysis
实际交易是有手续费的,因子对单因子的回测还需要考虑换手率的影响,换手率越高说明交易次数越多,可能产生的手续费越高。如果一个因子,今天给一个股票打了很高的分,明天就打很低的分,这将导致对该股频繁的买卖,从而造成很高的手续费。所以,因子的换手率分析也是很重要的一个部分。还有一个角度可以检视因子造成的换手率高低,就是因子的自相关性。如果因子的自相关性低,那么就一会儿高,一会儿低,往往会造成很大的换手率。而因子的自相关性高,就不会有这样的问题。因子的截面换手率越低,因子的自相关性越高
alphalens.tears.create_turnover_tear_sheet(data)



结语
本文以动态市盈率作为选股因子,旨在为大家展示如何利用alphalens进行单因子的历史回测,没有考虑行业或市值大小的分组因素影响,实战应用到量化因子筛选时还需考虑更多因素和细节的处理,包括调仓周期和分位数确定等,本文仅提供一个因子量化回测的一般分析框架,不构成任何投资建议。关于alphalens的详细使用教程可参看其官网或东北证券金融工程研报《Alphalens使用教程》,公众号后台回复“Alphalens ”即可下载。关于Python金融量化
专注于分享Python在金融量化领域的应用。加入知识星球,可以免费获取30多g的量化投资视讯资料、公众号文章Python完整源代码、量化投资前沿分析框架,与博主直接交流、结识圈内朋友等。































