
全文共1794字,预计学习时长15分钟
 图片来源:pexels.com
图片来源:pexels.com
线性回归是资料科学中最简单也是最重要的算法。无论面试的工作领域是资料科学、资料分析、机器学习或者是量化研究,都有可能会遇到涉及线性回归的具体问题。要想熟练掌握线性回归,需要了解以下知识。
注:本文仅涉及理论而非程式码。

了解所做假设
 图片来源:pexels.com
图片来源:pexels.com本文假设读者对线性回归有一定了解,但在开始介绍之前还是要回顾下线性回归的公式和假设。假设现在有N个观察值,输出向量Y(维度为Nx1),p输入X1,X2,...,XP(每个输入向量维度都为Nx1) 。线性回归假设回归函式E(Y |X)在输入中是线性的。因此,Y满足以下条件:

公式中ε代表误差。线性假设是线性回归中唯一必须的假设——稍后本文会新增更多假设以推断更多结果。
虽然以上公式似乎看上去简单,但要找到系数并不容易(β值)。我们将此称为带有‘^’的β值为系数估计值。

了解关键指标定义
以下是三个你必须要知道的指标(须牢记):
· RSS是残差平方和。
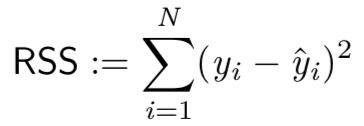
公式中y_i是观察值i的输出值,ŷ_i则是观察值i的估计输出值。

· TSS是总平方和。

其中

· R2用于衡量X与Y之间的线性关系。

只要熟悉以上公式,就应该能通过逻辑推理推断出其他所有结果。

了解答案:如何(与何时)计算
之前谈到,线性回归的关键是找到估系数的估计值。系数可以通过最小化RSS获得。定义X和Y如下:

注意,这里在输入矩阵中添加了一列1,以便考虑截距beta_o。现在最小化问题等同解决:

所以我们能计算出正确项的梯度:

理论上的估计值(带有‘^’的β值)应该也与o相等。
若 X⊤X非奇异,显然答案为:

这是必须了解的公式,但你也应该有能力像上文那样证明该公式。此处非奇异假设是关键。我们也能推汇出y估计值的公式:

了解在Nx1维度(只有一个输入变数)时的明确答案也是有用的:

此处的x是向量(而非矩阵),如果已经有更一般的解决方法时,就会很容易记住:X⊤X是输入变数的方差(在一维空间中,倒数相当于除以该项),而X⊤y则是协方差项。也可以通过在一维空间做类似计算来得出答案。

对假设检验感到满意(假设存在正常误差)
 图片来源:pexels.com
图片来源:pexels.com面试中,了解一些关于线性规划的统计概念也很重要。
本部分假设读者了解统计测试值的基本知识(包括t值、F/f值和假设检验)。
假设存在以下正常误差,例如:

(不要忘记这里的ε是向量!)之后估计值满足以下条件:

因此:

得到以下结论:

此结果有助于计算系数beta_j为零的零假设:可以计算t值:

在零假设中,z_j服从自由度为N-p-1的t值(分布),如果N足够大,则服从正态分布。

计算该值可帮你评估零假设。例如,高于1.96的t_j值可确保在5%的水平下beta_j系数不为空的显著性。
利用给定系数也可以计算置信区间:得出以下近似置信区间(1-2*alpha):
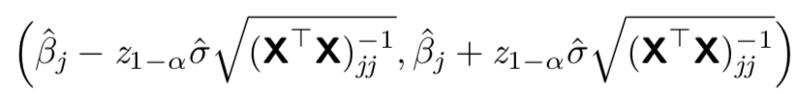
使用标准正态曲线下面积来计算:

通过计算F值也可以检验以下假设,即所有系数均为零。

零假设服从F(p, N-p-1)的统计/分布量。因此F值较大也可用来反对零假设的证据。

附加1:为什么我们需要计算最小*方差?
当寻找β的最佳估计时,会自然地想到最小平方/二乘优化,但为什么呢? 首先,可以证明最小二乘估计量是无偏的,即

实际上,有一个定理证明了最小二乘估计的方差最小 。这就是高斯马尔可夫定理 :该定理显示,最好的无偏估计是最小二乘法。

附加2:如果X⊤X非满秩怎么办?
首先要了解何时会有非满秩矩阵。要记住x是在(N,p+1)维度,X⊤X则在(p+1,p+1)。可以看到,只有在X的秩为p+1的情况下,X⊤X为满秩,从而迫使N必须大于p。
如果不是这种情况(引数多于观察值),可以用缩减技术,例如岭回归。实际上,当我们在 X⊤X 的对角线上新增一个项时,问题就变得可行了。以岭回归举例 :

得到解法:

的确,因为 X⊤X 为半正定矩阵,其特征值均为正,向对角线新增正项使其满秩,这样问题转化为非奇异。这也是为什么要在p>>N的情况下,使用正则化技术。

留言 点赞 关注
我们一起分享AI学习与发展的干货
欢迎关注全平台AI垂类自媒体 “读芯术”































