

文章作者:张惟师 居理新房大资料 VP
编辑整理:高勇
内容来源:DataFun AI Talk
出品社群:DataFun
注:欢迎转载,转载请注明出处
本次分享的内容提纲:

▌业务背景介绍
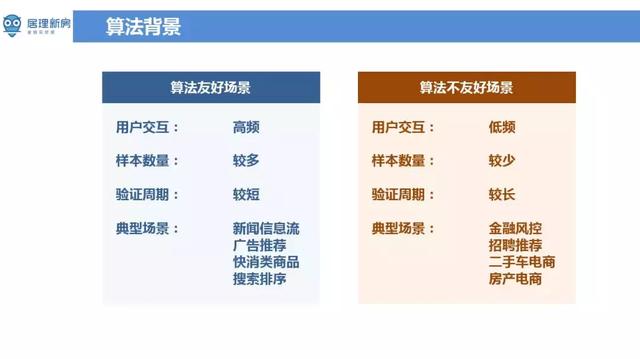
工业界中存在算法友好场景,也存在算法不友好的场景。算法友好场景中使用者互动资讯频繁,样本数量充足,模型验证周期短,常见的应用场景有新闻资讯流、广告推荐、快消类商品,搜寻排序等;算法不友好的场景中恰好相反,面临使用者互动资讯少,样本数量不足,模型验证周期长等多种问题,如金融风控、招聘推荐、二手车点电商、房产电商等场景。居理新房业务场景中属于后者,是在产业互联网中一种客单价极高,频率极低的典型算法不友好场景。
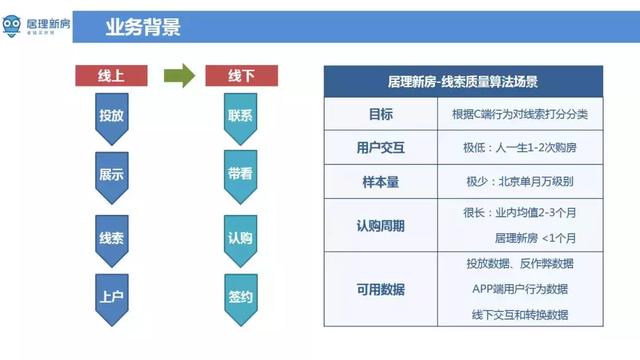
居理新房打造了独特的线上、线下的闭环生态系统。线上部分通过投放效果类、品牌类广告 ( 如 SEM, 资讯流等 ),在广告落地页上进行产品展示,App 下载等方式来引流客户。客户在使用相关产品线的产品时会产生一些线索资讯。这里的线索可以理解为使用者的相关资讯(如手机号码等)。线索资讯较为混乱,真假不一,因此需要线上客服人员对客户留下的线索进行筛选确认,将具有真实购房意愿的名单筛选出来给线下咨询师。由咨询师联络客户,带领客户预约看房, 客户满意的话,带领客户继续认购、签约等后续环节。从上述环节中可以看到线上获客到线下签约资料量呈漏斗式层层过滤,最后签约量较少。在整个流程中,广告自动投放和线索质量质量评估都有相关算法,这里主要介绍线索质量相关的算法。不同线索的质量不同,对于线索质量高的使用者,如果能在恰当的时间点为预测出客户的购房需求,可以提高使用者的转化率,对于线索质量低的客户,例如暂时处于观望或者是虚假资讯,如果能尽早的识别出来这一部分群体,可以降低线上客服稽核成本,进而提高咨询师的工作效率。这样比较自然的引入用线索质量二分类的算法,将好的线索直接给咨询师,不太好的线索给客服进行稽核。但是这种场景下的分类算法面临多种挑战,首先使用者互动频次极低,一个人一生平均购买一到两次房,也就几乎不存在历史购买行为资讯,其次是样本量少,举个例子,北京市2019年上半年新房成交量在 3w 套左右,其中居理新房的成交比例在2%左右,整体用于训练的样本不多。另外客户决策周期长,从平台首次接待客户到客户完成交易的周期业内均值在2-3个月,即使居理新房周期短一些,流程周期也要在20天到30天,换句话说是跟单周期长,算法上线后,至少跟单一个月才能观察算法效果。客户相关资讯较少,目前主要有客户渠道来源 ( 头条创意,百度渠道 ),以及客户在 App 上的历史浏览,点选,搜寻等行为资讯,还有一些线下获取的大量非结构化资讯 ( 如咨询师与客户的线下互动行为 ),但这部分资料线上获取不到,一般用来验证算法的有效性。
▌算法平台
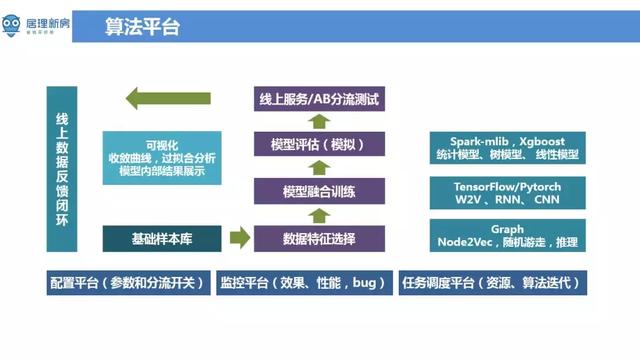
目前居理新房搭建了复用性和扩充套件性都比较好的算法平台,可以通过一些灵活的配置,实现相关监控,任务排程,模型校验,视觉化页面以及 AB Test。算法平台底层支援多种算法引擎包括机器学习模型平台 ( Spark-MLlib,Xgboost ),深度学习平台 ( Tensorflow,Pytorch ) 以及图相关模型。可以通过 pipeline 的方法整合资料流和算法引擎。
▌样本选择

如何选择正负样本?比较直观的做法将最终是否发生认购行为作为正负样本的评估依据。但在当前场景下,由于房屋交易业务转化率低,从线上访问 UV 到最终房屋认购,比例在万分之几左右,只从中间线索角度来看,这个比例也在2%-3%左右。为了解决样本稀疏问题,这里设定了一个代理目标,将是否发生带看行为作为正负样本的评估依据。带看行为发生在认购行为之前,发生认购行为占带看比例中的10分之一左右,周期也可从一到两个月缩减到两周左右。那么样本在一个周期 T 内,将是否被带看作为正负样本的评估依据。另外可以后续模型训练时,提高具有多次带看行为或者发生认购行为的权重。在一个时间周期 T 内,可能存在跟单不完全的情况,但这部分比例在10%以内,可以忽略。由于正负样本比例差异较大,在样本量较大的情况下,这种比例可以接受,但在样本量较少的情况下,正负样本比例差异导致模型学习困难。因此在训练模型前可以先对样本进行取样预处理。常见的样本取样方法有欠取样和过取样。欠取样是保持资料集正样本数量不变,根据一定比例去随机抽取负样本,过取样是通过已有正样本来构造虚拟正样本,来减小正负样本差异。常见的过取样方法有 SMOTE 等。但是取样方法会影响资料集中的正负样本分布,在关注概率值的分类等业务场景下,需要对模型输出的概率进行校准。
▌特征工程
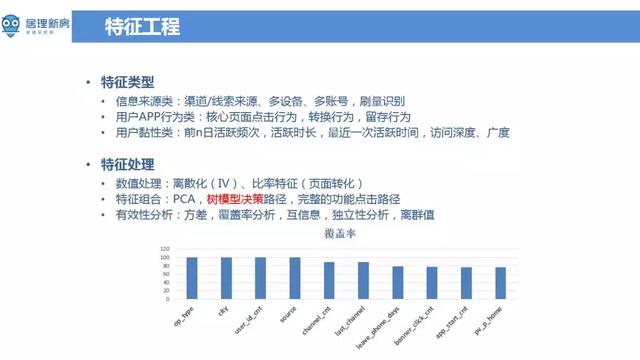
在特征工程中,特征型别主要有以下三类,资讯来源类 ( 渠道/线索来源、多装置、多账号,刷量识别 ),使用者 App 行为类 ( 核心页面点选行为,转换行为,留存行为 ),使用者粘性类 ( 前 n 日活跃频次,活跃时长,最近一次活跃时间,访问深度、广度 )。其中资讯渠道来源是指使用者是来自百度、Feed 还是广点通等平台,多装置、多账号等主要是用于衡量使用者是否发生过作弊行为。另外使用者 App 行为类特征是占比最大的一类特征,主要是指使用者在留电话号码前,在 App 上点选,浏览、搜寻等行为。使用者粘性类特征是一些抽象统计特征,其中访问深度是指 App 页面使用者访问最长的路径,广度是指 App 中使用者使用的功能的数量。
在 Deep Learning 的场景中,一般来说用 Embedding 就 ok 了,不需要较多的特征处理,但在当前场景下特征处理相对来说比较重要。常见的数值处理有 IV ( 离散化 )、页面比率 ( 页面转化 )。什么是页面转化?使用者搜寻 query 词后 App 显示楼盘资讯,如果使用者搜寻五次后发生一次点选行为,那么对于这个使用者来说,该使用者的搜寻点选的转化率就20%。特征组合主要有主成分分析 ( PCA ),树模型决策路径,以及完整的功能点选路径。另外还进行了特征有效性分析,重要包括方差,覆盖率分析,互资讯,独立性分析,离群值分析等。离群值分析在当前场景中影响较大,因为在样本量较少的情况,离群点容易误导模型。下图是资料集中覆盖率前10的特征,包括渠道表示 ( op_type ),城市 ( city ),使用者装置数量 ( user_id_cnt ),来源 ( source ),渠道数量 ( channel_cnt ),最近一次渠道来源 ( last_channel ),上一次留电话距离现在的天数 ( leave_phone_days ),App 中 banner 点选的数量 ( banner_click_cnt ),App 启动次数 ( app_start_cnt ) 等。
▌模型调优

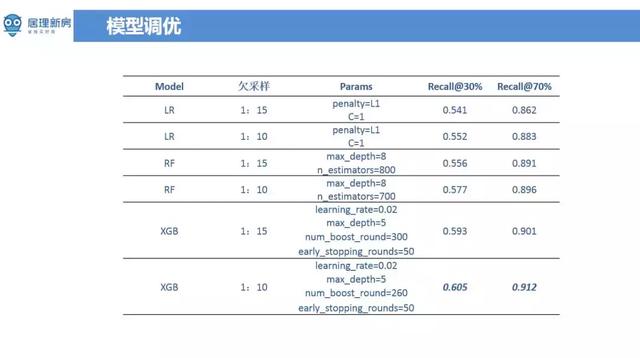
模型主要采用的传统模型 LR,RF,XGBoost,LightGBM,也尝试了使用 Deep Learning 等,但实际效果不足传统模型好。另外在当前场景下样本数量少,而且版本更新迭代较快的时候,常遇到资料分布不一致的问题。产品迭代了新的版本,但离线模型训练用的还是老的资料,而线上用的新版资料,这种资讯不一致将拉低模型效果。当前采用的方案是时间视窗滚动的方式来训练模型,并尽量剔除一些可能因为版本导致资料不一致的特征,努力将影响降至最低。在无论是深度学习还是传统机器学习,引数调优的方法大同小异,主要是网格搜寻 ( Grid Search )、人工引数调优以及分城市阈值调优。网格搜寻调优虽然不能一定找到最优解,但是花费时间较短。另外也尝试了一些贝叶斯优化的方法,它和 grid search 有的区别就是它会根据你上一轮做算法的引数结果去帮你去选择最有可能产生最优算法引数方向去优化这个引数,换句话说做了几轮引数实验并获取对应结果,利用贝叶斯优化自动帮忙寻找引数优化方向。贝叶斯寻优容易陷入区域性最优,需要多进行几轮贝叶斯优化,手工选出里面的极大值。分城市阈值调优是遇到的另一个更严重的一个场景,由于居理新房在全国十多个一二线的城市有业务,而且每个城市有自己不同的特点,使用者的行为都不一样,在模型分类时,每个城市应采取不同的阈值。在本身整体资料量就不多情况,每个城市的资料量更少,这种情况下要么将城市资讯加入特征或者每个城市都分别训练一个模型。
在做算法时,评估的值不一定是一些常用通用指标如 AUC,Top N 的点选率等,而是与业务比较契合的指标。采用通用指标来衡量算法刚开始可能还可以,但是一段时间后发现对业务帮助不大,指标虽然显示比较高,但最后并没有增加使用者的收入,也没有提升使用者的留存。只是说单独的就是算法本身还不错,所以很多时候更多需要的是找到真正跟业务结合的优化目标。经过多次思考和试验后,最后选了两类线索的带看召回率 ( [email protected]%、[email protected]% ) 的评估指标。模型输出概率需要选取阈值来判断线索是好的还是坏的。可以通过阈值选取,将不同比例的线索标成为好线索。比如说有一百个线索,从里面拿出来30个线索就30%,最后这30个线索被带看或成交的比例能达到60%。就相当于30%里面有60%的比例是被召回出来了,这阈值选取的还是不错的。因为在现有算法中不可能保证每一个线索都是好的,通过某个阈值大于70%的线索是好线索。那么在这70%的线索里边,应该至少能召回90%的带看或者认购的线索,才能说明这个算法才是有意义的。
另外就是 early stop 的调优方法,比如说这个模型在训练的时候,模型应该什么时候停止训练。一般来说会用到的方法是学习曲线 ( learning curve ),模型在训练的时候可能迭代一百次、迭代一千次的时候看模型的学习曲线有没有有很大的这种变化,如果在进行更多次迭代时发现测试集上效果在在下降,但是在训练集上其实在上升,这就是过拟合现象。从最好结果看,模型在 recall 为30%的时候,差不多有60%被带看或认购的比例,在 recall 的为70%时能达到91%的这样一个比例,从结果上来看还是能达到预期的结果。
▌可解释性分析
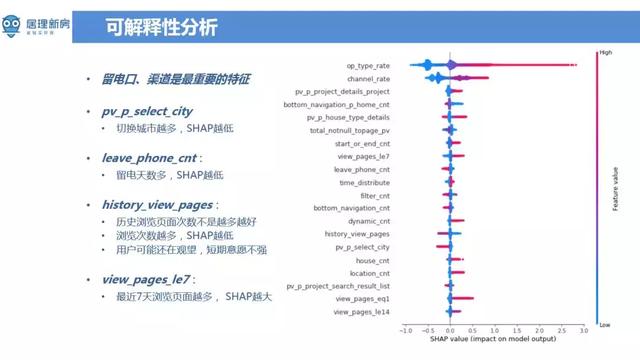
接下来主要讲一下可解释性的分析,因为整个房产行业的客单价都比较高,相当于说每个客户都特别的宝贵。以北京为例,平均每单利润在12万到15万。若将好线索误分为坏线索,没有为客户好好服务将会导致较大的损失。对于业务人员 ( 客服,咨询师 ) 而言,模型预估结果会与他们原有的一些工作模式和习惯矛盾,需要向业务人员解释模型预估结果。当算法去服务于业务团队的时候,这种可解释性显得尤为重要。通过 xgboost 计算得到的特征重要性 ( feature importance ) 不一定是完全可解释的,它和特征在决策森林中出现的次数相关。但特征在决策森林里面出现的次数越多并不能说明特征越重要。这里采用的是 SHAP 来进行可解释性分析,SHAP 计算的是一个特征加入到模型时的边际贡献,考虑了该特征在所有的特征序列的情况下不同的边际贡献。在 SHAP 图中,纵座标是特征列表,横座标是从负数到正数的取值范围,表示对模型输出值的影响。留电口、渠道特征是从 SHAP 方法来看是最为重要的特征。一般来说通过搜寻渠道来的使用者,购房的意向比较强烈,这个也和基本认知符合。另一个比较显著的特征 pv_p_select_city,表示切换城市的动作越多,使用者质量越差。举个例子:假设有北京和天津的都有业务,客户可能一会看看北京的房子,一会又选择天津的房子,就中间各种摇摆,客户可能也没太想好到底在哪个城市要买,这种情况下需要花费很多精力去说服客户,使用者转化成本计较高。留电天数越多,稍微比越低,就相当于一个月之前留的线索和昨天留的线索对比来看,明显是距离现在时间近的线索质量会高一点。如果客户上午留的电话,在下午的时候咨询师就能给客户提供服务,这种情况下转换概率会很大。但并不是所有的特征影响与我们对模型的预期是相同的,比如说特征 history_view_pages ( 使用者在 APP 的上 PV 贡献度 ),PV 贡献度越大,线索质量反而比较差。但如果从购房意愿来看也是可以理解的,对于购房意特别强的客户,浏览页面比较集中,更能体现使用者的关注点,虽然只使用了不到 App 1% 的特征,但转化率比较好。反而是那些楼盘看的特别多的使用者在行为上表现的流程和浏览广度都不错,但质量确实比较低。这种聚焦观点不仅适用于当前场景,也可以推广到产品上的其他场景。
▌实际效果

从模型效果来看,客户认购量提升了十七个百分点,基本达到了算法预期目标。从认购到带看的目标变化,将周期从两个月缩减到了两周,后续希望能找到一个更好的指标来代替带看,进一步缩短模型周期。另外居理新房还做了很多线下资料的累积。比如说咨询师与客户的电话录音,微信记录,交通行为等。通过这些离线资料能大概分析出咨询师和客户的行为,比如说通话频率,通话时长,微信验证,聊天频率,客户需求响应时长等多种详细指标。目前不同的城市资料累积量不同,等资料量积累到一定程度,可以为不同的城市设定独立的模型。另外模型融合 ( stacking ) 是后续优化的方向,看能不能做出更有意思的效果。目前的模型是基于无线资料,PC 资料相对无线来说,使用者行为比较少,下一步是跨站整合 PC 和无线的资料。































