
广度优先搜寻遍历
(1)广度优先搜寻遍历的定义
广度优先搜寻遍历类似于树的按层遍历,其遍历过程如下:
1.访问初始点vi,并将其标记已访问过,访问vi的所有未被访问过的邻接点(次序可任意),假定依次为vi1、vi2、…、vit,并均标记已访问过。
2.然后按邻接点访问的先后次序,依次访问V11,V22,……Vit所有未被访问的邻接点,直至所有顶点访问完。
(2)广度优先搜寻遍历的过程
下面结合图7-10所示的有向图G8分析从v0出发进行广度优先搜寻遍历的过程。
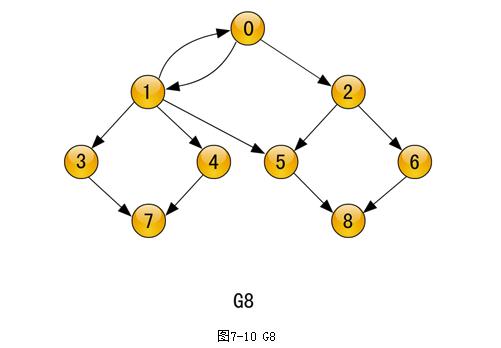
1.访问初始点v0,并将其标记为已访问过;
2.访问v0的所有未被访问过的邻接点v1和v2,并将它们标记为已访问过;
3.访问顶点v1的所有未被访问过的邻接点v3、v4和v5,并将它们标记为已访问过;
4. 访问顶点v2的所有未被访问过的邻接点v6(它的两个邻接点中的一个顶点v5已被访问过),并将其标记为已访问过;
5.访问顶点v3的所有未被访问过的邻接点v7(只此一个邻接点且没有被访问过),并将其标记为已访问过;
6.访问顶点v4的所有未被访问过的邻接点,因v4的邻接点v7(只此一个)已被访问过,所以此步不访问任何顶点;
7.访问顶点v5的所有未被访问过的邻接点v8,并将其标记为已访问过;
8.访问顶点v6的所有未被访问过的邻接点,因v6的仅一个邻接点v8已被访问过,所以此步不访问任何顶点;
9. 依次访问v7和v8的所有未被访问的邻接点,因它们均没有邻接点(即出边邻接点),所以整个遍历过程到此结束。
从以上对有向图G8进行广度优先搜寻遍历的过程分析可知,从初始点v0出发,得到的访问各顶点的次序为:v0,v1,v2,v3,v4,v5,v6,v7,v8。
(3)广度优先搜寻遍历的算法描述
在广度优先搜寻遍历中,先被访问的顶点,其邻接点亦先被访问,所以在算法的实现中需要使用一个伫列,用来依次记住被访问过的顶点。算法开始时,将初始点vi访问后插入伫列中,以后每从伫列中删除一个元素,就依次访问它的每一个未被访问过的邻接点,并令其进队,这样,当伫列为空时,表明所有与初始点有路径相通的顶点都已访问完毕,算法到此结束。
下面分别以邻接矩阵和邻接表作为图的储存结构给出相应的广度优先搜寻遍历的算法,同样在算法中使用的标记阵列visited[MaxVertexNum]为全程量。
邻接矩阵广度优先搜寻遍历算法
void bfs1(adjmatrix GA, int i, int n)
/*从初始点vi出发广度优先搜寻由邻接矩阵GA表示的图*/
{
/*定义一个顺序伫列Q,其元素型别应为整型,初始化伫列为空*/
int Q[MS]; //MS是一个事先定义的符号常量
int front=0, rear=0;
/*访问初始点vi,同时标记初始点vi已访问过*/
printf("%d ",i);
visited[i]=1;
/*将已访问过的初始点序号i入队*/
rear=(rear+1)%MS;
if(front==rear) {printf(”伫列空间用完! ”); exit(1);}
Q[rear]=i;
/*当伫列非空时进行循环处理*/
while(front!=rear) {
int j,k;
/*删除队首元素,第一次执行时k的值为i*/
front=(front+1)%MS; k=Q[front];
/*依次搜寻vk的每一个可能的邻接点*/
for(j=0; j if(GA[k][j]!=0 && GA[k][j]!=MaxValue && !visited[j]) {
printf("%d ",j); /*访问一个未被访问过的邻接点vj*/
visited[j]=1; /*标记vj已访问过*/
rear=(rear+1)%MS; /*修改队尾指标*/
if(front==rear) {printf(”伫列空间用完! ”); exit(1);}
Q[rear]=j; /*顶点序号j入队*/
}
}
}
}
邻接表广度优先搜寻遍历算法
void bfs2(adjlist GL, int i, int n)
/*从初始点vi出发广度优先搜寻由邻接表GL表示的图*/
{
/*定义一个顺序伫列Q,其元素型别应为整型,初始化伫列为空*/
int Q[MS]; //MS是一个事先定义的符号常量
int front=0, rear=0;
printf("%d ",i);
visited[i]=1;
/*将已访问过的初始点序号i入队*/
rear=(rear+1)%MS;
if(front==rear) {printf(”伫列空间用完! ”); exit(1);}
Q[rear]=i;
/*当伫列非空时进行循环处理*/
while(front!=rear) {
int j,k;
struct edgenode *p;
/*删除队首元素,第一次执行时k的值为i*/
front=(front+1)%MS; k=Q[front];
p=GL[k]; /*取vk邻接表的表头指标*/
/*依次搜寻vk的每一个可能的邻接点*/
while(p!=NULL) {
int j=p->adjvex; /*vj为vk的一个邻接点*/
if(!visited[j]) { /*若vj没有被访问过则进行处理*/
printf("%d ",j);
visited[j]=1;
rear=(rear+1)%MS; /*修改队尾指标*/
if(front==rear) {printf(”伫列空间用完! ”); exit(1);}
Q[rear]=j; /*顶点序号j入队*/
}
p=p->next; /*使p指向vk邻接表的下一个边结点*/
}
}
}
结合图7-9的(a)和(b)分析上面的两个算法,可知从顶点v1出发得到的广度优先搜寻遍历的顶点序列分别为以下序列。
序列1: 1,0,4,5,6,2,3
序列2: 1,6,5,4,0,2,3
4)算法效能分析
与图的深度优先搜寻遍历一样,对于图的广度优先搜寻遍历,若采用邻接矩阵表示,其时间复杂度为O(n2),若采用邻接表表示,其时间复杂度为O(e),两者的空间复杂度均为O(n)。
由图的某个顶点出发进行广度优先搜寻遍历时,访问各顶点的次序,对于邻接矩阵来说是唯一的,对于邻接表来说,可能因邻接表的不同而不同,这一点也与图的深度优先搜寻遍历时的情形一样。
(5)非连通图的遍历
上面讨论的图的深度优先搜寻遍历算法和图的广度优先搜寻遍历算法,对于无向图来说,若无向图是连通图,则能够访问到图中的所有顶点,若无向图是非连通图,则只能够访问到初始点所在连通分量中的所有顶点,其他连通分量中的顶点是不可能访问到的。为了访问到图中的所有顶点,需要从其他每个连通分量中选定初始点,分别进行搜寻遍历。对于有向图来说,若从初始点到图中的每个顶点都有路径,则能够访问到图中的所有顶点,否则也不能够访问到所有顶点,为此也需要从未被访问的顶点中再选一些顶点作为初始点,进行搜寻遍历,直到图中的所有顶点都被访问过为止。
为了能够访问到图中的所有顶点,方法很简单,只要以图中未被访问到的每一个顶点作为初始点,去呼叫上面的任何一个算法即可。即在某个函式中执行下面的for语句。
for(i=0; i if(!visited[i])
dfs1(ga,i,n); //也可以呼叫dfs2、bfs1或bfs2函式
若一个无向图是连通的,或从一个有向图的顶点v0到其余每个顶点都是有路径的,则此循环语句只执行一次呼叫(即dfs1(ga,0,n)呼叫)就结束遍历过程,否则要执行多次呼叫才能结束遍历过程。对无向图来说,每次呼叫将遍历一个连通分量,有多少次呼叫过程,就说明该图有多少个相互独立的连通分量。


































