

整理编辑:三石
【新智元导读】自动地将人脸照片转换为高质量的艺术肖像画具有重要的艺术价值和实用价值。清华大学刘永进教授课题组对此提出APDrawingGAN,结果优于目前已有方法。该项工作被CVPR 2019录取为oral paper。本文还提供微信小程式,供读者尝试。肖像画是一种独特的艺术形式,通常使用一组稀疏的连续图形元素如线条来捕捉一个人的外表特征。
肖像画通常是在人物面前或基于人物照片进行创作的,其创作依赖于细致的观察、分析和丰富的经验。一幅好的肖像画能很好地捕捉到人的个性和情感。

图1. 一些人脸照片和对应的艺术家画的肖像线条画。
然而,即使是受过专业训练的艺术家,完成一幅精致的肖像画也需要很长时间。因此,自动地将人脸照片转换为高质量的艺术肖像画具有重要的艺术价值和实用价值。
清华刘永进组提出APDrawing GAN
随着深度学习的发展,使用卷积神经网络进行影象风格转换的神经风格转换(NST)方法被提出。随后,基于生成对抗网络(GAN)的方法在影象风格转换上实现了很好的效果。
但是,这些已有方法多数针对于生成资讯较为丰富的风格,如油画,这些风格的影象中包含很多零碎的图形元素(如笔触),而对单个元素的质量要求较低。也就是说,在这些风格的影象中,一些细节上的瑕疵会被忽视。
艺术肖像线条画(Artistic Portrait Drawings,简称APDrawings)和已有工作研究的油画肖像的风格有很大的不同。它主要有5个特点:
首先它是高度抽象的,只由少数稀疏、连续的图形元素组成,因此瑕疵会比油画中更明显。
其次是具有强限制性,由于包含面部特征,APDrawings相比一般的风格有更强的语义限制(因为我们对人脸很熟悉,会对人脸影象中的瑕疵容忍度更低)。
具有多样性,因为对于不同的面部特征,艺术家绘制的方式是不同的(如眼睛和头发)。
艺术创作的模糊性,人工创作导致了一些面部特征的轮廓没法被完全精准的定位,这对基于画素对应的方法是个很大的挑战。
APDrawings的概念性,艺术家有时会在原图没有亮度变化的地方新增额外的概念性的线条,比如头发区域中的白线和五官的轮廓线。因此,即使是顶尖的方法也难以产生好的艺术肖像画结果。
APDrawingGAN和一般P图、抠图、滤镜等工具的不同在于,一般的软件对真实照片进行美化得到更美观或具有某种特点的真实照片,而APDrawingGAN生成的是非真实感的抽象艺术肖像画,既能捕捉到照片特征又和真实照片观感完全不同。并且我们生成的线条风格的艺术肖像画比一般的肖像画(如卡通、铅笔素描)具有更少的图形元素,更抽象,因此也更有难度。下图展示了我们方法和一般影象处理工具的结果对比。

图2. 我们的方法和一般影象处理工具的处理结果的对比。人脸照片来源于免费版权图片网站Pixabay。
在CVPR2019上,清华大学计算机系刘永进教授课题组提出了APDrawingGAN,为了更有效地学习不同面部区域的不同绘制风格,我们的GAN模型包括几个专门针对不同面部特征区域的区域性网络,和一个用于捕捉整体特征的全域性网络。

论文地址:
APDrawingGAN的主要贡献在于:
我们提出了一个层次化的GAN模型,可以有效地将人脸照片生成高质量、富有表现力的艺术肖像线条画。不仅如此,我们的方法对黑白线条分明的复杂发型绘制有更好的效果。
为了学习不同面部区域的不同绘制风格,我们的模型将GAN的渲染输出分为不同层次,每个层次被独立的损失项控制。我们提出了一个针对艺术肖像画的损失函式,它包含四个损失项:对抗损失、画素级损失、一种新的距离变换(DT)损失(用于学习艺术肖像画中的线条笔画)和一个区域性变换损失(用于引导区域性网络保持面部特征)。
我们使用6655张人脸照片和非真实感渲染算法生成的结果进行了预训练,构建了一个包含140对高质量正面人脸照片和对应艺术肖像画的APDrawings资料集,用于正式的训练和测试。

图3. 我们提出的APDrawingGAN的结构图。左侧为层次化生成器网络的结构,右侧为层次化鉴别器网络的结构。
在APDrawingGAN中,生成器网络G和鉴别器网络D都采用层次化的结构。生成器网络G用于将输入照片转换为艺术肖像画,它包含6个区域性生成器(对应于左右眼、鼻子、嘴巴、头发和背景),1个全域性生成器和1个融合网络。
区域性生成器的作用是学习不同区域性面部特征的绘制风格。我们将所有区域性生成器的输出混合到一个影象Ilocal中。区域性生成器和全域性生成器都采用U-Net结构。
然后我们使用一个融合网络将Ilocal和全域性生成器的输出Iglobal融合在一起,以获得最终的生成图。鉴别器网络D用于判断输入影象是否是真实的,即是否是艺术家画的艺术肖像画。
其中全域性鉴别器对整个影象进行检查,以判断肖像画的整体特征。而区域性鉴别器对不同的区域性面部区域进行检查,评估细节的质量。区域性鉴别器和全域性鉴别器都采用PatchGAN的形式。
为了进一步应对线条的风格和艺术家画作中不完全精确定位的轮廓,我们提出了一个全新的距离变换(Distance transform,简称DT)损失来学习艺术肖像线条画中的线条笔画风格。
我们前面提到,在艺术家的肖像画中,线条和原图有时不是精确对应的,会有微小的错位,主要的原因有两个:
艺术家裸眼观察,面部特征的轮廓有时无法被完全精准地定位;
艺术家新增的线条有时是概念性的,不与原图完全对应(如头发区域中的白线)。
因此仅使用L1损失是不足以应对这种情况的——L1损失会惩罚即使是很微小的错位,但是对于较大的错位并不会更敏感。
于是我们提出一种新的损失来容忍这种细微的错位,而惩罚过大的错位。我们提出的这个DT损失是基于距离的,它计算的是艺术家肖像画(Ground truth)中每个线条上的画素到生成肖像画中相同型别(黑或白)的最近画素的距离之和,和生成肖像画到艺术家肖像画的距离之和的总和。
DT损失对于微小的错位的惩罚是非常小的,但会真正惩罚那些过大的错位。我们使用了距离变换和倒角匹配(chamfer matching)来计算这个损失,公式如下:
倒角匹配距离:
距离变换损失:
其中和表示两幅肖像画,和表示距离变换,和分别表示黑白线条检测器,和分别表示人脸照片和对应的艺术家肖像画。APDrawingGAN结果对比

图4. APDrawingGAN在没有对应艺术家肖像画的人脸照片上的测试结果。人脸照片来源于免费版权图片网站Pixabay。
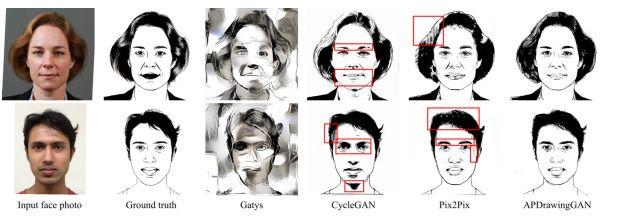
图5. APDrawingGAN与Gatys,CycleGAN和Pix2Pix方法在艺术肖像风格化上的结果对比。其中红色矩形标出了CycleGAN和Pix2Pix方法结果中的一些明显瑕疵。

图6. APDrawingGAN与CNNMRF,Deep Image Analogy和Headshot Portrait方法在艺术肖像风格化上的结果对比。

图7. APDrawingGAN与现有风格转换方法的结果对比。
第一列是人脸照片,第二列是艺术家画的肖像画,第三列是一些方法需要的风格参考图,第四至九列是其他方法的结果,最后一列是我们方法的结果。

使用者研究(user study)结果统计。
73名参与者参与了使用者研究。使用者研究中,每位参与者每次从两种算法生成的肖像画中选择一幅更接近艺术家肖像画和影象质量更好的肖像画,并对三种方法(CycleGAN、Pix2Pix和我们的方法)两两进行了比较,由此我们得到了三种方法的排名。
表中给出了每种方法排名最好(1)、中间(2)和最差(3)的百分比。在71.39%的情况下我们的方法排名最好。
最后,作者还制作了一个小程式展示APDrawingGAN的效果,小程式二维码如下,免费使用,快来试试吧:
论文地址:
新智元春季招聘开启,一起弄潮 AI 之巅!
































