近日,NVIDIA正式揭晓了全新一代GPU架构“安培”(Ampere),其庞大的规模、精妙的架构令人惊叹,同时不出意外、一如既往,首发核心又被割了一刀。
首先需要注意的是,不同于此前首发帕斯卡架构的Tesla P100、伏特架构的Tesla V100,这次的新计算卡被简单地叫做“A100”,并没有冠以Tesla的品牌序列,具体原因不详,可能是想用于更广泛领域。
与此同时,新的核心则被叫做“A100 Tensor Core GPU”,突出张量核心的关键作用,而核心代号按惯例延续为GA100。
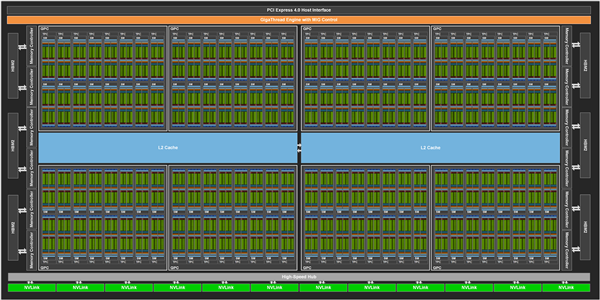
GA100设计了8组GPC(GPU处理集群),每一组GPC里又分为8组TPC(纹理处理集群),而每组又分为两组SM(流式多处理器),然后每组SM包含64个FP32 CUDA核心(流处理器)。

这样一来,一颗完整的GA100芯片就一共有128组SM、8196个流处理器,而这种分组结构和以往的NVIDIA GPU架构是一致的。
同时,每一组SM里还有4个第三代Tensor核心,整颗芯片内共计512个,外部则搭配六颗HBM2显存,每颗8GB,12个512-bit控制器,总位宽6144-bit。
另外,二级缓存从6MB猛增至40MB,每组SM单元的共享内存从最多96KB增至164KB、寄存器容量还是256KB,但整颗芯片寄存器达到27MB。
GA100芯片采用台积电第一代7nm(N7)工艺制造,核心面积达826平方毫米,相比上代12nm GV100仅增大了11平方毫米(0.13%),但晶体管数量从211亿个猛增至542亿个,多了接近1.6倍,同时功耗控制在400W(增加33%),可见新架构和新工艺的威力。
如此庞大的核心在量产初期显然会受制于良品率问题,所以实际使用的A100核心未达成完整规格,但和以往简单屏蔽整组计算单元不同,这次砍得略有些复杂。
GPC单元屏蔽了整整一组,但剩余的也并未全部开启,其中两组GPC也各自屏蔽了一个TPC(两组SM),导致总的SM单元为108个、流处理器为6912个、Tensor核心为432个。
核心加速频率1410MHz,比前两代其实都低了,但整体性能在飞跃。
显存也没有逃过刀法,只开启了五组HBM2,所以总容量为40GB,总位宽为5120-bit,频率1215MHz,带宽1555GB/s,比上代增加73%。
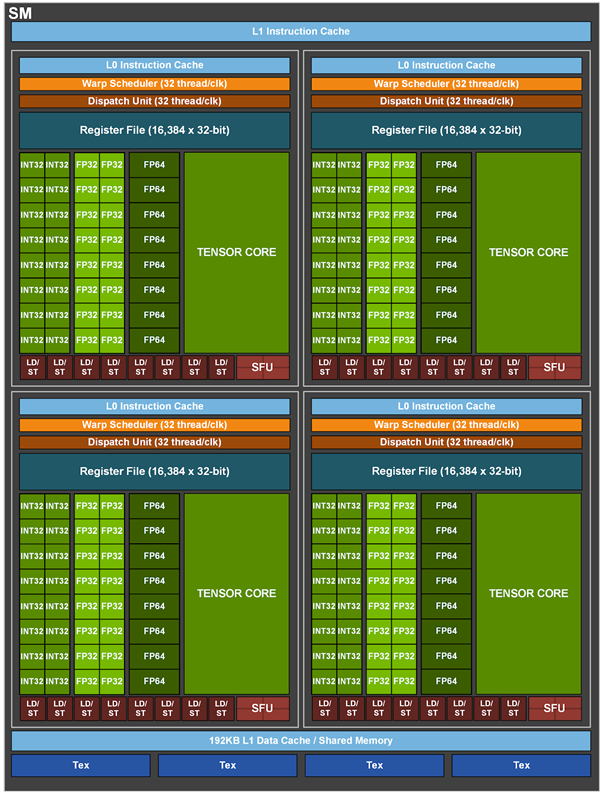
具体到每个SM单元,其中的Tensor核心数量虽然从8个减少到4个,但每一个每时钟周期都支持多达256个FP16FP FMA操作,合计就是1024个,相比伏特、图灵架构翻了一番。
新的Tensor核心还支持对所有数据类型加速,包括FP16、BF16、TF32、FP64、INT8、INT4、Binary。
更精细的专业细节这里就不展开了,你们也没啥兴趣。
三代架构首发核心规模对比
特别提醒:本网内容转载自其他媒体,目的在于传递更多信息,并不代表本网赞同其观点。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,并请自行核实相关内容。本站不承担此类作品侵权行为的直接责任及连带责任。如若本网有任何内容侵犯您的权益,请及时联系我们,本站将会在24小时内处理完毕。